语音合成(speech synthesis)方向五:多语言模型multi
目录
1 研究背景
2研究情况
2.1 迁移学习
2.1.1系统架构设计
2.1.2 输入格式设计
2.2 数据增量(data )
3 总结
4 引用
1 研究背景
随着国际化的进展,语言交叉使用现象也变得非常普遍,生活中的信息往往由多种语言混合使用(例如,中文的文本中包含英文的单词,英文中包含法语、德语等等),这给语音合成提出巨大挑战。处理多语言交叉的文本,最直观的方案是:让同一个说话人录制多种语言的训练语料,然后使用每种语言的训练语料来分别训练一个模型。当合成语音的时候,先把文本按照语言先进性切分,然后使用对应的模型合成部分语音片段,最后把合成的语音片段进行拼接。但该方法的缺点也很突出,有几种语言就要训练几个模型,这增加了内存开销,同时语音片段拼接也会出现很不自然的情况。现在主流的方案是把多语言语料混合在一起进行多语言模型的训练,这样当进行语音合成的时候就不需要进行模型切换,因此也避免的语言间切换的不自然现象。理想很丰满,现实很残酷。以上的两种方案的前提是需要同一个发音人具备多种语言的训练语料。通常,一种语言的标注语料都需要几十万开销,并且寻找精通多种语言而且音色优美的发音人更是难上加难。因此,使用多人的单语言语料来训练多语言()模型成为近期研究的热点。
对于使用多人单语言语料进行多语言模型的研究,需要解决很多问题。比如,多种语言如何统一标准格式进行输入?如何进行各种语言间的风格迁移?如何处理语言之间的切换(code ),使切换更加自然?当前,机器学习的方法突飞猛进(比如:迁移学习( ),知识共享( ), 声音复制(voice clone)等等),促使语音合成获得巨大的成功,因此本文针对语音合成在多语言模型上的研究进展进行总结,以供同行参考。
2研究情况
到目前为止,发表的 & code 的相关文章很多,主要解决的问题如下:1)多语言之间的输入格式问题,如何保留语言之间的上下文信息,切换更自然;2)如何进行语言与说话人之间进行解耦,使其说话人可以进行语言复刻(同一个说话人讲多种语言);处理以上的问题,大部分文章的解决方案可以归纳为迁移学习( )和数据增量(data ),接下来我将选取这两年具有代表性的文章进行总结。文章列表如下:
1)迁移学习:
a)系统架构设计
to Speak in a : and Cross- Voice
Cross- Text-to- under -Data
One Model, Many : Meta- for Text-to-
b) 输入内容格式设计
End-to-End Code- TTS with Cross- Model
Using IPA-Based for Data Cross- and
for 0-shot
Code- Using Only
2)数据增量
and Code- Based on Mix of and Cross- Voice
2.1 迁移学习 2.1.1系统架构设计
该部分主要选取对系统架构设计的文章
2.1.1. to Speak in a : and Cross- Voice
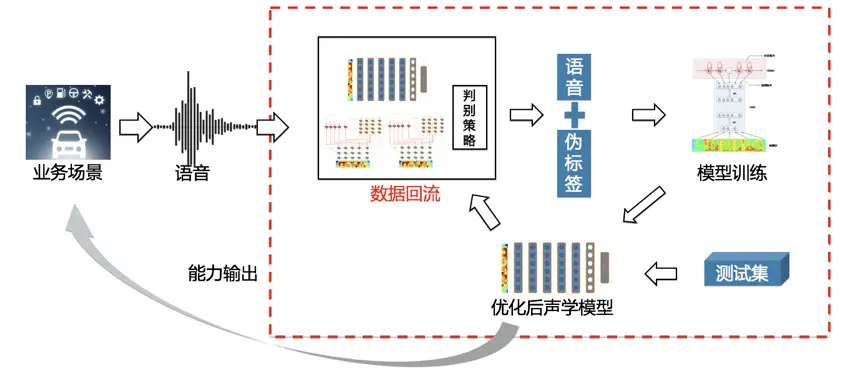
先看一下本文的系统结构,该结构太经典了,该文章之后发表的很多文章都是在这种架构上修修改改,毕竟是出自。详细的系统架构如图1所示,该架构由3部分网络组成: (左上角模块,更多的文章标注为 , 等等), DAT( ,右上角绿色模块)和 (最下方模块)。 使用了变分自编码VAE来学习音频的隐含变量,比如韵律,噪声,情感等等,该模块为非监督学习。DAT模块为图中绿色部分( loss,主要在模型训练时候使用),主要功能把输入的语言信息和固定的进行解耦。 模块为最下边的模块,本文使用架构,该模块主要功能是把语言特征转成声学特征。此外,本文研究内容为 & ,因此 2额外添加 和 的控制变量。另外,本文也对文本输入的三种格式进行对比:/,uft8-bytes 和,后边的实验结果可以做个很好的经验。
本文实验主要测试客观指标:相似度和自然度。
首先,先测试原始英语EN,西班牙语ES,和中文CN之间的相似性,测试结果如table 1所示。由结果可知,ES和CN稍微相似一些,其值大于2,其它语言之间相似度很低。
接下来,先验证输入格式的效果对比:/, uft8-bytes 和。由可知,无论何种情况,使用都是效果最好(这个可以作为积累的经验记着)。
然后,可以对比一下 和 模块的作用(我按照自己的想法对本文章的实验顺序改了一下,这样看起来更好)。由可知,使用 (DAT)的效果更好。由table 5可知,使用 的MOS值更高。
最后,比较一下 的效果,由table 4和图2可以看出,该系统可以很好的做到语言迁移,使说话者可以说不同语言。
2.1.1.- Text-to- under -Data
为了支持多语言和语言转换,本文章添加了 序列,该序列跟 seq是一对一关系。输入时候, token 和 seq拼接在一起,输入到的部分。另外为支持多发音人还需要还需要拼接 信息,其它的部分没有改变,详细的系统设计如图一:(比较上一篇文章可知,本文需要添加DAT模块,使其发音人信息和语言信息进行解耦,这样学习的效果更好)
本文章对语音的自然度,相似度和可懂度等多个方面进行评估,由结果可知(Table 2 ,3 ,4),单语言发音人可以发出多种语言,而且可以进行语言切换。另外,由图2的对齐图片可知,要是拥有语言混合的语料进行训练,则语言切换的效果会更好。
2.1.1.3One Model, Many : Meta- for Text-to-
本文详细的系统结构如图1。首先,该系统把的部分BLSTM去掉,全部使用卷积层conv,而且每种语言拥有单独的部分。其次,该系统添加 部分,把音素相应的语言类型信息进行处理然后拼接到的每一层。最后,的输出输入到和 部分。(系统整体很简单,至于 需要多层FC与 的每一层进行对应,只是感觉这样很复杂)
本文对比的系统主要有三类:单语言系统( SGL), 多种语言共享系统(SHA), 语言独享系统(SEP)。本文设计的系统被命名为GEN。首先,对比以上系统合成的音质,该对比先使用各类系统合成音频,然后使用ASR对合成的语音进行识别,测CER。从Table 2 的左侧部分可知,本文的GEN在大部分语言效果相对好一些(加粗部分),右侧部分是进行少数据的压测,由结果可知,GEN的效果比SHA较好。
其次对比合成质量MOS和漏字情况,从Table 3和图4可知,本文的Gen效果最好。
2.1.2 输入格式设计
2.1.2.1End-to-End Code- TTS with Cross- Model
该文章的主要想法其实很简单:先使用跨语言语言模型(CLLM)把输入的文本输出词向量(WV),该词向量包含了上下文语境。然后,把该向量与输出和音素进行拼接,使输入到的内容包含更多的语言信息,从而提高语音自然度。
本文章是在(图 1所示)基础上进行修改,另外比较有意思的是图2的残差,该部分把音素与 输出进行拼接,从而保持更多的语言信息。图3是本文添加了跨语言语言模型(CLLM属于NLP处理的知识),该模型可以输出多种语言的词向量,词向量包含上下文环境变量。(这样看来文章整体思想很简单。)
本文使用方法进行对比。图4是显示是否做效果,其中i-vex是不做,由结果可知做效果好。图5图6显示本文提出的添加CLWE模块在跨语言和单语言效果都较好。
2.1.2. IPA-Based for Data Cross- and
本系统是基于架构进行修改,主要的修改包括以下几点:第一,phone 是使用的国际音标IPA集,因此可以兼容多种语言。第二, input 与rnn输出进行拼接(跟上文差不多)。另外本文章主要提出如何去做自适应训练,定义自适应更新的模块。
基于的声学模型如下公式表示:其中Y是声学特征,X是文本输入,Sid是说话者的id,We,Wd,Wp,Ws分别为, , phone table和 table的参数。做个性化训练的时候,如果相同语言的自适用使用公式2,加粗部分是部分,不进行参数更新。训练跨语言模型则使用公式3。
本文章的评测主要包括主观和客观两个方面,由结果可知在单语言和多语言实验都可以进行迁移学习(我总感觉缺少对比试验,现在个性化方案已经很多了,可以对比。而且可以把原始语音的MOS标注出来作为标准,感觉对比试验太少)
2.1.2. for 0-shot
本文的思想:为了使多语言能够进行统一格式输入,因此选择国际音标IPA作为统一输入集,然后把IPA转成具有诸多特征的语音特征。该特征包括(/vowel, (/), vowel , vowel , vowel , on vowel, place, , and (e.g., , ). )等等。整体过程为:多语言的音素集--->国际音标IPA--->语音特征 。具体的转换脚本可以查看以下的代码库:
本文实验是在上进行,系统结构不在进行讲解。基础模型数据库(VCTK, MIX(英语vctk &西班牙语)),迁移目标数据为德语,数据的情况为table 1。其中oos为未覆盖的音素集
实验的对比系统::对oos的音素的随机赋值;为把oos音素跟基础模型的音素根据语音特征计算距离,选取距离较短的音素值赋值给该因素。本文的方案为AUTO。
首先看一下图1,子图(a)为的音素分布,音素之间没有形成聚类(b)为本文方案,音素之间有聚类现象 (c)为oss的音素可以寻找到相似的音素集群中
在音质可懂度方面,图2显示本文的方案可懂度最好。
在AB偏爱的比较之间则没有特别的好坏之分。
2.1.2.4Code- Using with Only
现有基准的模型架构如图1所示, 学习一些未标注的隐含特征, 模块主要把语言特征和说话人进行解耦,其它模块就是标准的--模型。本文借鉴该模型提出了使用PPG特征进行中间特征,使其语言特征和声学特征更好的映射,具体的模块如图2所示。首先,训练PPG提取模块,该模块用来提取跟说话人和语言无关的特征PPG。然后,使用--模型来映射语言特征和PPG+lf0+uv。最后,使用生成的PPG+lf0+uv来映射声学特征。
本文实验主要从主观角度。图三为可懂度测评,由结果可以看出本文提出的Prop的效果好于base系统。图4和图5为自然度和喜爱度测评,两个系统没什么区别,作者说可能是PPG的准确度造成的。
2.2 数据增量(data )
本部分为使用声音转换(voice VC)进行数据增量。
2.2. and Code- Based on Mix of and Cross- Voice
本文章主要使用基于 来实现vc,具体的结构如图1。该结构先对原发音人的语料进行特征提取,如MFCC和lf0。然后,通过PPG (ASR的AM部分,把声学特征转成跟发音人无关的特征表示)模块把MFCC生成对应的PPGs。接下来,把PPGs和lf0输入到目标发音人模型中生成声学特征。最后,通过目标发音人的把声学特征转成语音波形。举例来说,要生成中文发音人的英文语料,就要把英文作为 ,中文发音人作为 。英文发音人生成中文语料的过程类似。基于-VC 的训练不需要 data,详细的+的结构如图二。(个人感觉主要的麻烦还是ppg训练,我是做TTS的,还需要ASR提供帮助)
该文章使用训练数据包括中文32000句差不多30小时,英文27000大约41小时,同时合成17000句中英混合的语料。该文章在, 和上进行效果评估,具体效果语音链接。对比结果如下:table 1是VC的效果,可以看出合成的语音虽然没有 truth的好,但可以使用。和分别是中文发音人和英文发音人在,和上做的实验,可以看出合成的语音跟十分接近,效果非常好。
3 总结
现在的的模型架构设计大同小异(以上系统的架构几乎都在 系列基础上进行优化试验),效果还算不错。当然,想要在生产环境上使用还需要想法进行进一步优化。(如果对以上文章内容存疑,可以详看相应的论文,本文只是做个简单的介绍,更细的设计和参数需要自己去阅读)
4 引用
[1]Zhang Y, Weiss R J, Zen H, et al. to speak in a : and cross- voice [J]. arXiv arXiv:1907.04448, 2019.
[2]Cai Z, Yang Y, Li M. Cross- Text-to- under -Data [J]. arXiv arXiv:2005.10441, 2020.
[3] T, Dušek O. One Model, Many : Meta- for Text-to-[J]. arXiv arXiv:2008.00768, 2020.
[4]Zhou X, Tian X, Lee G, et al. End-to-End Code- TTS with Cross- Model[C]// 2020-2020 IEEE on , and (). IEEE, 2020: 7614-7618.
[5] H, Borth D. Using IPA-Based for Data Cross- and [J]. arXiv arXiv:2011.06392, 2020.
[6]Staib M, Teh T H, A, et al. for 0-shot [J]. arXiv arXiv:2008.04107, 2020.
[7]Cao Y, Liu S, Wu X, et al. Code- Using with Only [C]// 2020-2020 IEEE on , and (). IEEE, 2020: 7619-7623
[8]Zhao S, T H, Wang H, et al. and Code- Based on Mix of and Cross- Voice [J]. arXiv arXiv:2010.08136, 2020.













