【通览一百个大模型】GLM(THU)
订阅专栏【大模型&NLP&算法】可获得博主多年积累的全部NLP、大模型和算法干货资料大礼包,近200篇论文,300份博主亲自撰写的笔记,近100个大模型资料卡,助力NLP科研、学习和求职。
一、GLM原理 GLM大模型基本资料卡 序号大模型名称归属推出时间规模预训练语料评测基准模型与训练方法开源论文模型地址相关资料
13
GLM
清华NLP
2022-05
、等13GB英文语料;
中文版本模型预训练语料为.0
、CNN/、XSum
(1)预训练任务为自回归填充任务。通过进行统一训练。输入部分含有mask片段的文本(蓝色),所有token的全部可见;输出部分为自回归式依次生成被mask的各个片段的文本(黄绿色),片段顺序是被打乱的(黄绿色先后顺序是随机的),矩阵被mask,每个片段生成起始终止符号为[S]和[E]。
(2)多任务训练:文档级别和句子级别的填充任务;
(3)Fine-:所有NLG和NLU转换为生成式任务。
GLM
glm-10b
查看
GLM模型架构及预训练目标如下所示:
GLM相关开源项目:
模型架构: -only 模型
预训练任务:输入一个含有 token的文本[MASK](蓝色),按照 目标生成 token对应的文本(黄色和绿色)。预训练时生成的 token先后顺序是随机的,同时每一个 span都有两个特殊标记[START]和[END];
下游微调&推理:
目前开放的GLM系列模型如下表所示:
fig
GLM-Base
110M
Wiki+Book
Token
glm-base-blank.tar.bz2
.sh
GLM-Large
335M
Wiki+Book
Token
glm-large-blank.tar.bz2
.sh
GLM-Large-
335M
Token+Sent+Doc
glm-large-.tar.bz2
.sh
GLM-Doc
335M
Wiki+Book
Token+Doc
glm-large-.tar.bz2
.sh
GLM-410M
410M
Wiki+Book
Token+Doc
glm-1.25-.tar.bz2
..sh
GLM-515M
515M
Wiki+Book
Token+Doc
glm-1.5-.tar.bz2
..sh
GLM-
335M
Token
glm--large-blank.tar.bz2
.sh
GLM-2B
2B
Pile
Token+Sent+Doc
glm-2b.tar.bz2
.sh
GLM-10B
10B
Pile
Token+Sent+Doc
.sh
GLM-10B-
10B
Token+Sent+Doc
inese.sh
GLM仓库:
使用GLM进行文本生成任务,例如:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-10b", trust_remote_code=True)
model = AutoModelForSeq2SeqLM.from_pretrained("THUDM/glm-10b", trust_remote_code=True)
model = model.half().cuda()
model.eval()# Inference
inputs = tokenizer("Ng is an adjunct professor at [MASK] (formerly associate professor and Director of its Stanford AI Lab or SAIL ). Also a pioneer in online education, Ng co-founded Coursera and deeplearning.ai.", return_tensors="pt")
inputs = tokenizer.build_inputs_for_generation(inputs, max_gen_length=512)
inputs = inputs.to('cuda')
outputs = model.generate(**inputs, max_length=512, eos_token_id=tokenizer.eop_token_id)
print(tokenizer.decode(outputs[0].tolist()))# Training
inputs = tokenizer(["Tsinghua University is located in [MASK].", "One minus one equals zero, is it correct? Answer: [MASK]"],return_tensors="pt", padding=True)
inputs = tokenizer.build_inputs_for_generation(inputs, targets=["Beijing", "No"], max_gen_length=8, padding=False)
inputs = inputs.to('cuda')
outputs = model(**inputs)
loss = outputs.loss
logits = outputs.logits
二、-6B
-6B 是一个开源的、支持中英双语的对话语言模型,基于 Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 -6B 使用了和 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 -6B 已经能生成相当符合人类偏好的回答,
2.1 硬件需求 量化等级最低 GPU 显存(推理)最低 GPU 显存(高效参数微调)
FP16(无量化)
13 GB
14 GB
INT8
8 GB
9 GB
INT4
6 GB
7 GB
环境安装
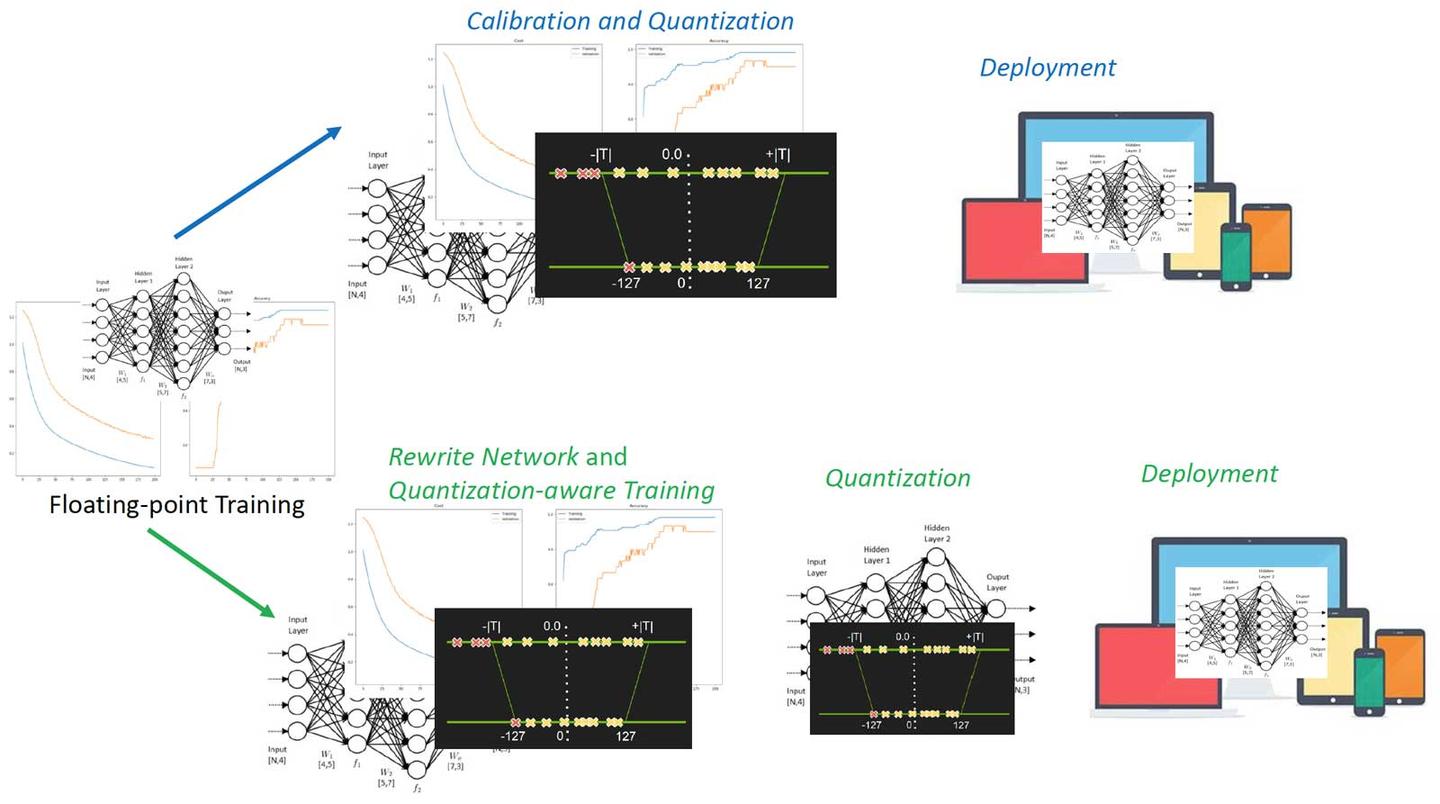
使用 pip 安装依赖:pip -r .txt,其中 库版本推荐为 4.27.1,但理论上不低于 4.23.1 即可。
此外,如果需要在 cpu 上运行量化后的模型,还需要安装 gcc 与 。多数 Linux 发行版默认已安装。对于 ,可在安装 TDM-GCC 时勾选 。 测试环境 gcc 版本为 TDM-GCC 10.3.0, Linux 为 gcc 11.3.0。在 MacOS 上请参考 Q1。
2.2 代码调用
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
2.3 从本地加载模型
以上代码会由 自动下载模型实现和参数。完整的模型实现可以在 Face Hub。如果你的网络环境较差,下载模型参数可能会花费较长时间甚至失败。此时可以先将模型下载到本地,然后从本地加载。
从 Face Hub 下载模型需要先安装Git LFS,然后运行
git clone
如果你从 Face Hub 上下载 的速度较慢,可以只下载模型实现
=1 git clone
然后从这里手动下载模型参数文件,并将下载的文件替换到本地的 -6b 目录下。
将模型下载到本地之后,将以上代码中的 THUDM/-6b 替换为你本地的 -6b 文件夹的路径,即可从本地加载模型。
2.4 微调-6B (1)基于进行参数有效性训练
官网已经给出了一种基于P- V2的参数有效性微调,详见:。
使用自己的训练数据
修改 train.sh 和 .sh 中的 、和为你自己的 JSON 格式数据集路径,并将 和 改为 JSON 文件中输入文本和输出文本对应的 KEY。可能还需要增大 和 来匹配你自己的数据集中的最大输入输出长度。
对话数据集
如需要使用多轮对话数据对模型进行微调,可以提供聊天历史,例如以下是一个三轮对话的训练数据:
{“”: “长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线”, “”: “用电脑能读数据流吗?水温多少”, “”: []}
{“”: “95”, “”: “上下水管温差怎么样啊?空气是不是都排干净了呢?”, “”: [[“长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线”, “用电脑能读数据流吗?水温多少”]]}
{“”: “是的。上下水管都好的”, “”: “那就要检查线路了,一般风扇继电器是由电脑控制吸合的,如果电路存在断路,或者电脑坏了的话会出现继电器不吸合的情况!”, “”: [[“长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线”, “用电脑能读数据流吗?水温多少”], [“95”, “上下水管温差怎么样啊?空气是不是都排干净了呢?”]]}
训练时需要指定 -- 为数据中聊天历史的 key(在此例子中是 ),将自动把聊天历史拼接。要注意超过输入长度 的内容会被截断。
开始训练时执行以下脚本:
bash .sh
(2)基于LoRA的参数有效性训练
其他开源项目实现了基于LoRA训练,例如:
目前这两个项目还在和中。这些项目的实现思路是基于开发了简单的数据加载和微调代码,并直接从上加载-6B模型。
模型部署 模型量化
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
# 按需修改,目前只支持 4/8 bit 量化
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).quantize(8).half().cuda()
进行 2 至 3 轮对话后,8-bit 量化下 GPU 显存占用约为 10GB,4-bit 量化下仅需 6GB 占用。随着对话轮数的增多,对应消耗显存也随之增长,由于采用了相对位置编码,理论上 -6B 支持无限长的 -,但总长度超过 2048(训练长度)后性能会逐渐下降。
模型量化会带来一定的性能损失,经过测试,-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。使用 GPT-Q 等量化方案可以进一步压缩量化精度/提升相同量化精度下的模型性能,欢迎大家提出对应的 Pull 。
量化过程需要在内存中首先加载 FP16 格式的模型,消耗大概 13GB 的内存。如果你的内存不足的话,可以直接加载量化后的模型,INT4 量化后的模型仅需大概 5.2GB 的内存:
# INT8 量化的模型将"THUDM/chatglm-6b-int4"改为"THUDM/chatglm-6b-int8"
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).half().cuda()
量化模型的参数文件也可以从这里手动下载。
CPU 部署
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float()
如果你的内存不足,可以直接加载量化后的模型:
# INT8 量化的模型将"THUDM/chatglm-6b-int4"改为"THUDM/chatglm-6b-int8"
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4",trust_remote_code=True).float()
如果遇到了报错 Could not find ‘.dll’ 或者 : : (MacOS) ,请从本地加载模型
Mac 部署
对于搭载了 Apple 或者 AMD GPU 的Mac,可以使用 MPS 后端来在 GPU 上运行 -6B。需要参考 Apple 的 官方说明 安装 -(正确的版本号应该是2.1.0.,而不是2.0.0)。
目前在 MacOS 上只支持从本地加载模型。将代码中的模型加载改为从本地加载,并使用 mps 后端:
model = AutoModel.from_pretrained("your local path", trust_remote_code=True).half().to('mps')
加载半精度的 -6B 模型需要大概 13GB 内存。内存较小的机器(比如 16GB 内存的 Pro),在空余内存不足的情况下会使用硬盘上的虚拟内存,导致推理速度严重变慢。此时可以使用量化后的模型如 -6b-int4。因为 GPU 上量化的 是使用 CUDA 编写的,因此无法在 MacOS 上使用,只能使用 CPU 进行推理。
# INT8 量化的模型将"THUDM/chatglm-6b-int4"改为"THUDM/chatglm-6b-int8"
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4",trust_remote_code=True).float()
为了充分使用 CPU 并行,还需要单独安装 。
多卡部署
如果你有多张 GPU,但是每张 GPU 的显存大小都不足以容纳完整的模型,那么可以将模型切分在多张GPU上。首先安装 : pip ,然后通过如下方法加载模型:
from utils import load_model_on_gpus model = load_model_on_gpus("THUDM/chatglm-6b", num_gpus=2)
即可将模型部署到两张 GPU 上进行推理。你可以将 改为你希望使用的 GPU 数。默认是均匀切分的,你也可以传入 参数来自己指定。
博客记录着学习的脚步,分享着最新的技术,非常感谢您的阅读,本博客将不断进行更新,希望能够给您在技术上带来帮助。
【大模型&NLP&算法】专栏
近200篇论文,300份博主亲自撰写的笔记。订阅本专栏【大模型&NLP&算法】专栏,或前往即可获得全部如下资料: