《TCP/IP网络编程》第 10 章 多进程服务器端 笔记
第 10 章 多进程服务器端
本章代码,在TCP-IP-中可以找到。
10.1 进程概念及应用 10.1.1 并发服务端的实现方法
通过改进服务端,使其同时向所有发起请求的客户端提供服务,以提高平均满意度。而且,网络程序中数据通信时间比 CPU 运算时间占比更大,因此,向多个客户端提供服务是一种有效的利用 CPU 的方式。接下来讨论同时向多个客户端提供服务的并发服务器端。下面列出的是具有代表性的并发服务端的实现模型和方法:
先是第一种方法:多进程服务器
10.1.2 理解进程
进程的定义如下:
占用内存空间的正在运行的程序
假如你下载了一个游戏到电脑上,此时的游戏不是进程,而是程序。只有当游戏被加载到主内存并进入运行状态,这是才可称为进程。
10.1.3 进程 ID
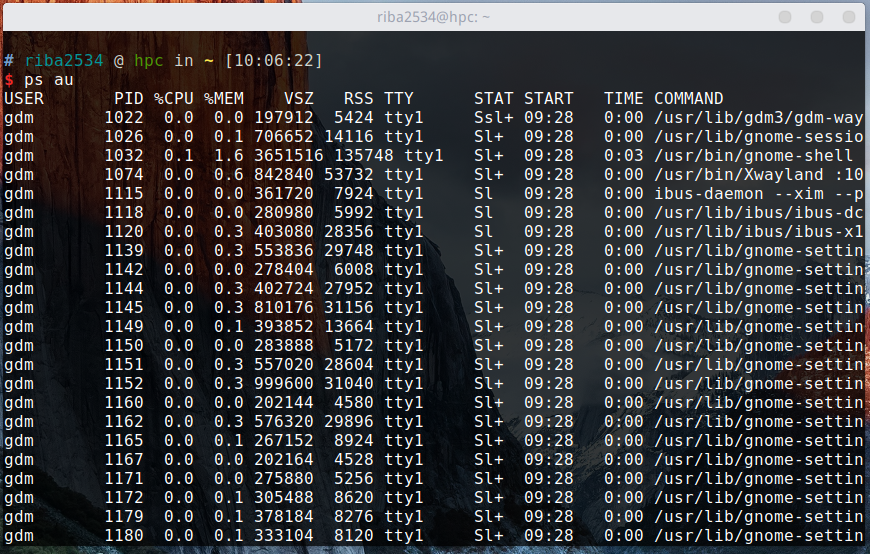
在说进程创建方法之前,先要简要说明进程 ID。无论进程是如何创建的,所有的进程都会被操作系统分配一个 ID。此 ID 被称为「进程ID」,其值为大于 2 的证书。1 要分配给操作系统启动后的(用于协助操作系统)首个进程,因此用户无法得到 ID 值为 1 。接下来观察在 Linux 中运行的进程。
ps au
通过上面的命令可查看当前运行的所有进程。需要注意的是,该命令同时列出了 PID(进程ID)。参数 a 和 u列出了所有进程的详细信息。
创建进程的方式很多,此处只介绍用于创建多进程服务端的 fork 函数。
#include fork 函数将创建调用的进程副本。也就是说,并非根据完全不同的程序创建进程,而是复制正在运行的、调用 fork 函数的进程。另外,两个进程都执行 fork 函数调用后的语句(准确的说是在 fork 函数返回后)。但因为是通过同一个进程、复制相同的内存空间,之后的程序流要根据 fork 函数的返回值加以区分。即利用 fork 函数的如下特点区分程序执行流程。
此处,「父进程」( )指原进程,即调用 fork 函数的主体,而「子进程」(Child )是通过父进程调用 fork 函数复制出的进程。接下来是调用 fork 函数后的程序运行流程。如图所示:

从图中可以看出,父进程调用 fork 函数的同时复制出子进程,并分别得到 fork 函数的返回值。但复制前,父进程将全局变量 gval 增加到 11,将局部变量 lval 的值增加到 25,因此在这种状态下完成进程复制。复制完成后根据 fork 函数的返回类型区分父子进程。父进程的 lval 的值增加 1 ,但这不会影响子进程的 lval 值。同样子进程将 gval 的值增加 1 也不会影响到父进程的 gval 。因为 fork 函数调用后分成了完全不同的进程,只是二者共享同一段代码而已。接下来给出一个例子:
#include 编译运行:
gcc fork.c -o fork
./fork
运行结果:

可以看出,当执行了 fork 函数之后,此后就相当于有了两个程序在执行代码,对于父进程来说,fork 函数返回的是子进程的ID,对于子进程来说,fork 函数返回 0。所以这两个变量,父进程进行了 +2 操作 ,而子进程进行了 -2 操作,所以结果是这样。
10.2 进程和僵尸进程
文件操作中,关闭文件和打开文件同等重要。同样,进程销毁和进程创建也同等重要。如果未认真对待进程销毁,他们将变成僵尸进程。
10.2.1 僵尸()进程
进程的工作完成后(执行完 main 函数中的程序后)应被销毁,但有时这些进程将变成僵尸进程,占用系统中的重要资源。这种状态下的进程称作「僵尸进程」,这也是给系统带来负担的原因之一。
僵尸进程是当子进程比父进程先结束,而父进程又没有回收子进程,释放子进程占用的资源,此时子进程将成为一个僵尸进程。如果父进程先退出 ,子进程被init接管,子进程退出后init会回收其占用的相关资源
维基百科:
在类UNIX系统中,僵尸进程是指完成执行(通过exit系统调用,或运行时发生致命错误或收到终止信号所致)但在操作系统的进程表中仍然有一个表项(进程控制块PCB),处于"终止状态"的进程。这发生于子进程需要保留表项以允许其父进程读取子进程的exit :一旦退出态通过wait系统调用读取,僵尸进程条目就从进程表中删除,称之为"回收()"。正常情况下,进程直接被其父进程wait并由系统回收。进程长时间保持僵尸状态一般是错误的并导致资源泄漏。
英文术语 源自丧尸 — 不死之人,隐喻子进程已死但仍然没有被收割。与正常进程不同,kill命令对僵尸进程无效。孤儿进程不同于僵尸进程,其父进程已经死掉,但孤儿进程仍能正常执行,但并不会变为僵尸进程,因为被init(进程ID号为1)收养并wait其退出。
子进程死后,系统会发送 信号给父进程,父进程对其默认处理是忽略。如果想响应这个消息,父进程通常在 信号事件处理程序中,使用wait系统调用来响应子进程的终止。
僵尸进程被收割后,其进程号(PID)与在进程表中的表项都可以被系统重用。但如果父进程没有调用wait,僵尸进程将保留进程表中的表项,导致了资源泄漏。某些情况下这反倒是期望的:父进程创建了另外一个子进程,并希望具有不同的进程号。如果父进程通过设置事件处理函数为显式忽略信号,而不是隐式默认忽略该信号,或者具有标志,所有子进程的退出状态信息将被抛弃并且直接被系统回收。
UNIX命令ps列出的进程的状态(“STAT”)栏标示为 "Z"则为僵尸进程。[1]
收割僵尸进程的方法是通过kill命令手工向其父进程发送信号。如果其父进程仍然拒绝收割僵尸进程,则终止父进程,使得init进程收养僵尸进程。init进程周期执行wait系统调用收割其收养的所有僵尸进程。
10.2.2 产生僵尸进程的原因
为了防止僵尸进程产生,先解释产生僵尸进程的原因。利用如下两个示例展示调用 fork 函数产生子进程的终止方式。
**向 exit 函数传递的参数值和 main 函数的 语句返回的值都回传递给操作系统。而操作系统不会销毁子进程,直到把这些值传递给产生该子进程的父进程。处在这种状态下的进程就是僵尸进程。**也就是说将子进程变成僵尸进程的正是操作系统。既然如此,僵尸进程何时被销毁呢?
应该向创建子进程册父进程传递子进程的 exit 参数值或 语句的返回值。
如何向父进程传递这些值呢?操作系统不会主动把这些值传递给父进程。只有父进程主动发起请求(函数调用)的时候,操作系统才会传递该值。换言之,如果父进程未主动要求获得子进程结束状态值,操作系统将一直保存,并让子进程长时间处于僵尸进程状态。也就是说,父母要负责收回自己生的孩子。接下来的示例是创建僵尸进程:
#include 编译运行:
gcc zombie.c -o zombie
./zombie
结果:

因为暂停了 30 秒,所以在这个时间内可以验证一下子进程是否为僵尸进程。
通过 ps au 命令可以看出,子进程仍然存在,并没有被销毁,僵尸进程在这里显示为 Z+.30秒后,红框里面的两个进程会同时被销毁。
利用 ./ &可以使程序在后台运行,不用打开新的命令行窗口。
10.2.3 销毁僵尸进程 1:利用 wait 函数
如前所述,为了销毁子进程,父进程应该主动请求获取子进程的返回值。下面是发起请求的具体方法。有两种,下面的函数是其中一种。
#include 调用此函数时如果已有子进程终止,那么子进程终止时传递的返回值(exit 函数的参数返回值,main 函数的 返回值)将保存到该函数的参数所指的内存空间。但函数参数指向的单元中还包含其他信息,因此需要用下列宏进行分离:
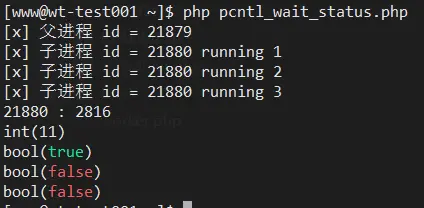
也就是说,向 wait 函数传递变量 的地址时,调用 wait 函数后应编写如下代码:
if (WIFEXITED(status))
{puts("Normal termination");printf("Child pass num: %d", WEXITSTATUS(status));
}
根据以上内容,有如下示例:
#include 编译运行:
gcc wait.c -o wait
./wait
结果:
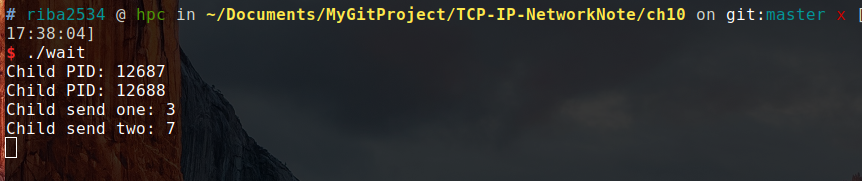
此时,系统中并没有上述 PID 对应的进程,这是因为调用了 wait 函数,完全销毁了该子进程。另外两个子进程返回时返回的 3 和 7 传递到了父进程。
这就是通过 wait 函数消灭僵尸进程的方法,调用 wait 函数时,如果没有已经终止的子进程,那么程序将阻塞()直到有子进程终止,因此要谨慎调用该函数。
10.2.4 销毁僵尸进程 2:使用 函数
wait 函数会引起程序阻塞,还可以考虑调用 函数。这是防止僵尸进程的第二种方法,也是防止阻塞的方法。
#include 以下是 的使用示例:
#include 编译运行:
gcc waitpid.c -o waitpid
./waitpid
结果:
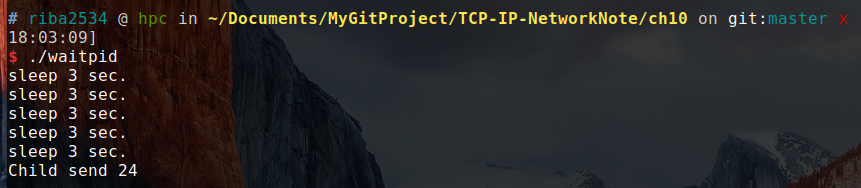
可以看出来,在 while 循环中正好执行了 5 次。这也证明了 函数并没有阻塞
10.3 信号处理
我们已经知道了进程的创建及销毁的办法,但是还有一个问题没有解决。
子进程究竟何时终止?调用 函数后要无休止的等待吗?
10.3.1 向操作系统求助
子进程终止的识别主题是操作系统,因此,若操作系统能把如下信息告诉正忙于工作的父进程,将有助于构建更高效的程序
为了实现上述的功能,引入信号处理机制( )。此处「信号」是在特定事件发生时由操作系统向进程发送的消息。另外,为了响应该消息,执行与消息相关的自定义操作的过程被称为「处理」或「信号处理」。
10.3.2 信号与 函数
下面进程和操作系统的对话可以帮助理解信号处理。
进程:操作系统,如果我之前创建的子进程终止,就帮我调用 函数。
操作系统:好的,如果你的子进程终止,我舅帮你调用 函数,你先把要函数要执行的语句写好。
上述的对话,相当于「注册信号」的过程。即进程发现自己的子进程结束时,请求操作系统调用的特定函数。该请求可以通过如下函数调用完成:
#include 调用上述函数时,第一个参数为特殊情况信息,第二个参数为特殊情况下将要调用的函数的地址值(指针)。发生第一个参数代表的情况时,调用第二个参数所指的函数。下面给出可以在 函数中注册的部分特殊情况和对应的函数。
接下来编写调用 函数的语句完成如下请求:
「子进程终止则调用 函数」
此时 函数的参数应为 int ,返回值类型应为 void 。只有这样才能称为 函数的第二个参数。另外,常数 定义了子进程终止的情况,应成为 函数的第一个参数。也就是说, 函数调用语句如下:
signal(SIGCHLD , mychild);
接下来编写 函数的调用语句,分别完成如下两个请求:
已到通过 alarm 函数注册时间,请调用 函数输入 ctrl+c 时调用 函数
代表这 2 种情况的常数分别为 和 ,因此按如下方式调用 函数。
signal(SIGALRM , timeout);
signal(SIGINT , keycontrol);
以上就是信号注册过程。注册好信号之后,发生注册信号时(注册的情况发生时),操作系统将调用该信号对应的函数。先介绍 alarm 函数。
#include 如果调用该函数的同时向它传递一个正整型参数,相应时间后(以秒为单位)将产生 信号。若向该函数传递为 0 ,则之前对 信号的预约将取消。如果通过改函数预约信号后未指定该信号对应的处理函数,则(通过调用 函数)终止进程,不做任何处理。
#include 编译运行:
gcc signal.c -o signal
./signal
结果:
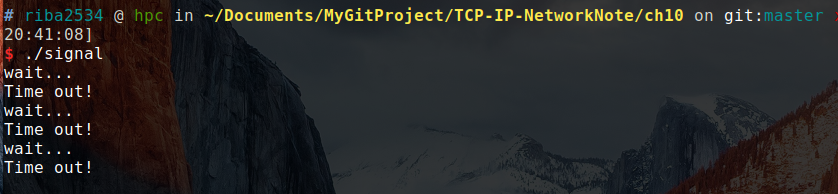
上述结果是没有任何输入的运行结果。当输入 ctrl+c 时:
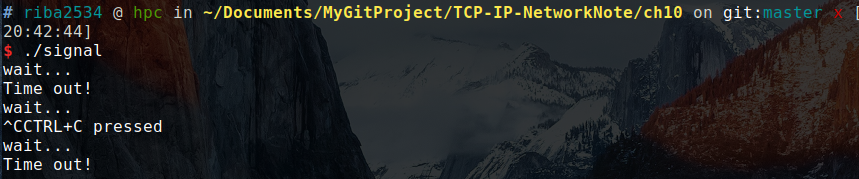
就可以看到 CTRL+C 的字符串。
发生信号时将唤醒由于调用 sleep 函数而进入阻塞状态的进程。
调用函数的主题的确是操作系统,但是进程处于睡眠状态时无法调用函数,因此,产生信号时,为了调用信号处理器,将唤醒由于调用 sleep 函数而进入阻塞状态的进程。而且,进程一旦被唤醒,就不会再进入睡眠状态。即使还未到 sleep 中规定的时间也是如此。所以上述示例运行不到 10 秒后就会结束,连续输入 CTRL+C 可能连一秒都不到。
简言之,就是本来系统要睡眠100秒,但是到了 alarm(2) 规定的两秒之后,就会唤醒睡眠的进程,进程被唤醒了就不会再进入睡眠状态了,所以就不用等待100秒。如果把 () 函数中的 alarm(2) 注释掉,就会先输出wait...,然后再输出Time out! (这时已经跳过了第一次的 sleep(100) 秒),然后就真的会睡眠100秒,因为没有再发出 alarm(2) 的信号。
10.3.3 利用 函数进行信号处理
前面所学的内容可以防止僵尸进程,还有一个函数,叫做 函数,他类似于 函数,而且可以完全代替后者,也更稳定。之所以稳定,是因为:
函数在 Unix 系列的不同操作系统可能存在区别,但 函数完全相同
实际上现在很少用 函数编写程序,他只是为了保持对旧程序的兼容,下面介绍 函数,只讲解可以替换 函数的功能。
#include 声明并初始化 结构体变量以调用上述函数,该结构体定义如下:
struct sigaction
{void (*sa_handler)(int);sigset_t sa_mask;int sa_flags;
};
此结构体的成员 保存信号处理的函数指针值(地址值)。 和 的所有位初始化 0 即可。这 2 个成员用于指定信号相关的选项和特性,而我们的目的主要是防止产生僵尸进程,故省略。
下面的示例是关于 函数的使用方法。
#include 编译运行:
gcc sigaction.c -o sigaction
./sigaction
结果:
wait...
Time out!
wait...
Time out!
wait...
Time out!
可以发现,结果和之前用 函数的结果没有什么区别。以上就是信号处理的相关理论。
10.3.4 利用信号处理技术消灭僵尸进程
下面利用子进程终止时产生 信号这一点,来用信号处理来消灭僵尸进程。看以下代码:
#include 编译运行:
gcc remove_zomebie.c -o zombie
./zombie
结果:
Child proc id: 11211
Hi I'm child process
Child proc id: 11212
wait
Hi! I'm child processwaitwait
Removed proc id: 11211
Child send: 12
wait
Removed proc id: 11212
Child send: 24
wait
请自习观察结果,结果中的每一个空行代表间隔了5 秒,程序是先创建了两个子进程,然后子进程 10 秒之后会返回值,第一个 wait 由于子进程在执行,所以直接被唤醒,然后这两个子进程正在睡 10 秒,所以 5 秒之后第二个 wait 开始执行,又过了 5 秒,两个子进程同时被唤醒。所以剩下的 wait 也被唤醒。
所以在本程序的过程中,当子进程终止时候,会向系统发送一个信号,然后调用我们提前写好的处理函数,在处理函数中使用 来处理僵尸进程,获取子进程返回值。
10.4 基于多任务的并发服务器 10.4.1 基于进程的并发服务器模型
之前的回声服务器每次只能同事向 1 个客户端提供服务。因此,需要扩展回声服务器,使其可以同时向多个客户端提供服务。下图是基于多进程的回声服务器的模型。
从图中可以看出,每当有客户端请求时(连接请求),回声服务器都创建子进程以提供服务。如果请求的客户端有 5 个,则将创建 5 个子进程来提供服务,为了完成这些任务,需要经过如下过程:
10.4.2 实现并发服务器
下面是基于多进程实现的并发的回声服务器的服务端,可以结合第四章的 .c 回声客户端来运行。
编译运行:
gcc echo_mpserv.c -o eserver
./eserver
结果:
和第四章的几乎一样,可以自己测试,此时的服务端支持同时给多个客户端进行服务,每有一个客户端连接服务端,就会多开一个子进程,所以可以同时提供服务。
10.4.3 通过 fork 函数复制文件描述符
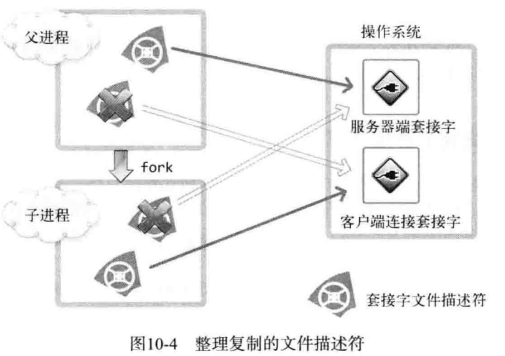
示例中给出了通过 fork 函数复制文件描述符的过程。父进程将 2 个套接字(一个是服务端套接字另一个是客户端套接字)文件描述符复制给了子进程。
调用 fork 函数时赋值父进程的所有资源,但是套接字不是归进程所有的,而是归操作系统所有,只是进程拥有代表相应套接字的文件描述符。
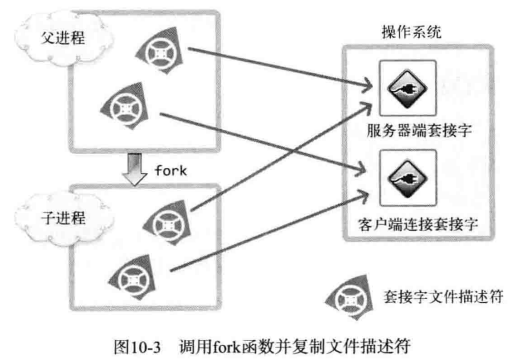
如图所示,1 个套接字存在 2 个文件描述符时,只有 2 个文件描述符都终止(销毁)后,才能销毁套接字。如果维持图中的状态,即使子进程销毁了与客户端连接的套接字文件描述符,也无法销毁套接字(服务器套接字同样如此)。因此调用 fork 函数候,要将无关紧要的套接字文件描述符关掉,如图所示:
10.5 分割 TCP 的 I/O 程序 10.5.1 分割 I/O 的优点
我们已经实现的回声客户端的数据回声方式如下:
向服务器传输数据,并等待服务器端回复。无条件等待,直到接收完服务器端的回声数据后,才能传输下一批数据。
传输数据后要等待服务器端返回的数据,因为程序代码中重复调用了 read 和 write 函数。只能这么写的原因之一是,程序在 1 个进程中运行,现在可以创建多个进程,因此可以分割数据收发过程。默认分割过程如下图所示:
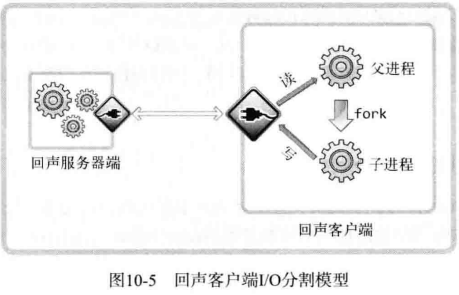
从图中可以看出,客户端的父进程负责接收数据,额外创建的子进程负责发送数据,分割后,不同进程分别负责输入输出,这样,无论客户端是否从服务器端接收完数据都可以进程传输。
分割 I/O 程序的另外一个好处是,可以提高频繁交换数据的程序性能,图下图所示:
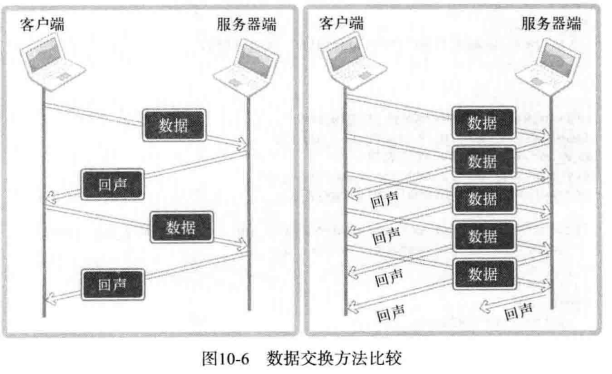
根据上图显示可以看出,再网络不好的情况下,明显提升速度。
10.5.2 回声客户端的 I/O 程序分割
下面是回声客户端的 I/O 分割的代码实现:
可以配合刚才的并发服务器进行执行。
编译运行:
gcc echo_mpclient.c -o eclient
./eclient 127.0.0.1 9190
结果:

可以看出,基本和以前的一样,但是里面的内部结构却发生了很大的变化
10.6 习题