Hadoop之使用MR编程实现join的两种方法
文章目录 3.端实现Join
前言:通过MR不同方式的Join编程是为了更加熟悉join的实现过程以及不同方式的优缺点,切记,生产中要杜绝写MR,本文只供学习参考 1.需求
有两张表,分表是产品信息数据以及用户页面点击日志数据如下:
#产品信息数据:product_info.txt
#c1=产品ID(id),c2=产品名称(name),c3=价格(privce),c4=生产国家(country)
p0001,华为,8000,中国
p0002,小米,3000,中国
p0003,苹果,1500,美国
p0004,三星,10000,韩国#用户页面点击日志数据:page_click_log.txt
#c1=用户ID(id),c2=产品id(prod_id),c3=点击时间(click_time),c4=动作发生地区(area)
u0001,p0001,20190301040123,华中
u0002,p0002,20190302040124,华北
u0003,p0003,20190303040124,华南
u0004,p0004,20190304040124,华南
由于点击日志的数据量过去庞大,数据是存在HDFS上,故需要使用MR来实现如下的逻辑:
select b.id,b.name,b.privce,b.country,a.id,a.click_time,a.area
from page_click_log a join product_info b on a.prod_id=b.id
2.Map端实现Join 2.1思路分析
可以将小表数据分发到所有的map节点,然后可以与在本所读到的大表数据进行join并输出最终结果
优缺点:大大提高了jion的并发,速度快
2.2编程实现
数据封装类Info.java
package com.wsk.bigdata.pojo;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.ArrayList;public class Info implements Writable {/*** 产品唯一标识id*/private String pId;/*** 产品名称*/private String pName;/*** 产品价格*/private float price;/*** 产品生产地区*/private String produceArea;/*** 用户Id*/private String uId;/*** 用户点击时间戳:yyyyMMddHHmmss*/private String dateStr;/*** 用户点击发生地区*/private String clickArea;/*** flag=0,表示封装用户点击日志数据* flag=1,表示封装产品信息*/private String flag;public String getpId() {return pId;}public void setpId(String pId) {this.pId = pId;}public String getpName() {return pName;}public void setpName(String pName) {this.pName = pName;}public float getPrice() {return price;}public void setPrice(float price) {this.price = price;}public String getProduceArea() {return produceArea;}public void setProduceArea(String produceArea) {this.produceArea = produceArea;}public String getuId() {return uId;}public void setuId(String uId) {this.uId = uId;}public String getDateStr() {return dateStr;}public void setDateStr(String dateStr) {this.dateStr = dateStr;}public String getClickArea() {return clickArea;}public void setClickArea(String clickArea) {this.clickArea = clickArea;}public String getFlag() {return flag;}public void setFlag(String flag) {this.flag = flag;}public Info(String pId, String pName, float price, String produceArea, String uId, String dateStr, String clickArea, String flag) {this.pId = pId;this.pName = pName;this.price = price;this.produceArea = produceArea;this.uId = uId;this.dateStr = dateStr;this.clickArea = clickArea;this.flag = flag;}public Info() {}@Overridepublic String toString() {String[] fileds = {this.pId,};return "pid=" + this.pId + ",pName=" + this.pName + ",price=" + this.price+ ",produceArea=" + this.produceArea+ ",uId=" + this.uId + ",clickDate=" + this.dateStr + ",clickArea=" + this.clickArea;}@Overridepublic void write(DataOutput out) throws IOException {out.writeUTF(this.pId);out.writeUTF(this.pName);out.writeFloat(this.price);out.writeUTF(this.produceArea);out.writeUTF(this.uId);out.writeUTF(this.dateStr);out.writeUTF(this.clickArea);out.writeUTF(this.flag);}@Overridepublic void readFields(DataInput in) throws IOException {this.pId = in.readUTF();this.pName = in.readUTF();this.price = in.readFloat();this.produceArea = in.readUTF();this.uId = in.readUTF();this.dateStr = in.readUTF();this.clickArea = in.readUTF();this.flag= in.readUTF();}
}
map实现类.java
package com.wsk.bigdata.mapreduce.mapper;import com.wsk.bigdata.pojo.Info;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;/*** 文件间的Mapjoin*/
public class FileMapJoinMapper extends Mapper<LongWritable, Text, Info, NullWritable> {/*** 产品信息信息集合,key=产品ID,value=产品信息*/private Map<String, Info> infos = new HashMap<>();/*** 执行Map方法前会调用一次setup方法,我们可以用于* 初始化读取产品信息加到到内存中**/@Overrideprotected void setup(Context context) throws IOException, InterruptedException {System.out.println("--------MAP初始化:加载产品信息数据到内存------");BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(System.getProperty("product.info.dir"))));String line;while (StringUtils.isNotEmpty(line = br.readLine())) {String[] fields = line.split(",");if (fields != null && fields.length == 4) {Info info = new Info(fields[0], fields[1], Float.parseFloat(fields[2]), fields[3], "", "", "", "1");infos.put(fields[0], info);}}br.close();System.out.println("--------MAP初始化:共加载了" + infos.size() + "条产品信息数据------");}@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String[] fields = line.split(",");if (fields != null && fields.length == 4) {String pid = fields[1];Info produceInfo = infos.get(pid);if (produceInfo == null) {return;}Info info = new Info(produceInfo.getpId(), produceInfo.getpName(), produceInfo.getPrice(), produceInfo.getProduceArea(), fields[0], fields[2], fields[3], null);context.write(info, NullWritable.get());}}}
程序入口类.java
package com.wsk.bigdata.mapreduce.driver;import com.wsk.bigdata.mapreduce.mapper.FileMapJoinMapper;
import com.wsk.bigdata.pojo.Info;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class MapJoinDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {if(args.length != 3 ) {System.err.println("please input 3 params: product_File page_click_file output_mapjoin directory");System.exit(0);}String productInfo = args[0];String input = args[1];String output = args[2];System.setProperty("hadoop.home.dir", "D:\\appanzhuang\\cdh\\hadoop-2.6.0-cdh5.7.0");System.setProperty("product.info.dir",productInfo);Configuration conf = new Configuration();// 写代码:死去活来法FileSystem fs = FileSystem.get(conf);Path outputPath = new Path(output);if(!fs.exists(new Path(productInfo))){System.err.println("not found File "+productInfo);System.exit(0);}if(fs.exists(outputPath)) {fs.delete(outputPath, true);}Job job = Job.getInstance(conf);job.setJarByClass(MapJoinDriver.class);job.setMapperClass(FileMapJoinMapper.class);// 指定mapper输出数据的kv类型job.setMapOutputKeyClass(Info.class);job.setMapOutputValueClass(NullWritable.class);FileInputFormat.setInputPaths(job, new Path(input));FileOutputFormat.setOutputPath(job, new Path(output));// map端join的逻辑不需要reduce阶段,设置reducetask数量为0job.setNumReduceTasks(0);boolean res = job.waitForCompletion(true);}
}
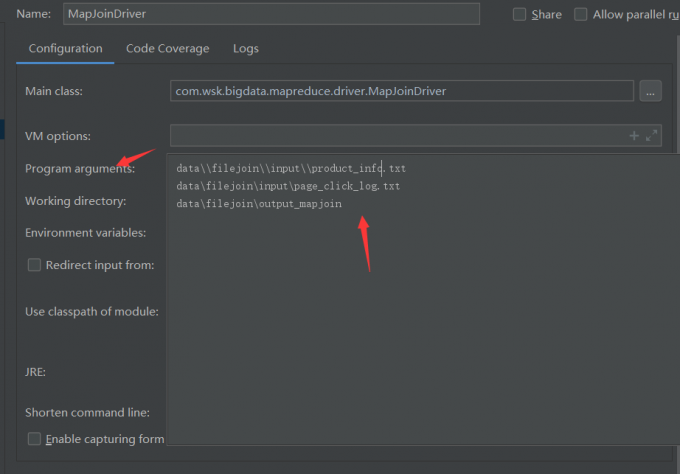
程序运行参数,分别是产品信息文件路径、页面点击日志数据路径、输出结果路径
3.端实现Join
#####3.1思路
通过将关联的条件作为map输出的key,将两表满足join条件的数据并携带数据所来源的文件信息,发往同一个 task,在中进行数据的串联
优缺点:这种方式中,join的操作是在阶段完成,端的处理压力太大,map节点的运算负载则很低,资源利用率不高,且在阶段极易产生数据倾斜
#####3.2编程实现
map实现类.java
package com.wsk.bigdata.mapreduce.mapper;import com.wsk.bigdata.pojo.Info;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;import java.io.IOException;public class FileReduceJoinMapper extends Mapper<LongWritable, Text, Text, Info> {Text k = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String[] fields = line.split(",");String pid = "";Info info = null;// 通过文件名判断是哪种数据FileSplit inputSplit = (FileSplit) context.getInputSplit();String name = inputSplit.getPath().getName();if (name.startsWith("product")) {pid=fields[0];info = new Info(pid,fields[1],Float.parseFloat(fields[2]),fields[3],"","","","1");} else {pid=fields[1];info = new Info(pid,"",0,"",fields[0],fields[2],fields[3],"0");}if(info==null){return;}k.set(pid);System.out.println("map 输出"+info.toString());context.write(k, info);}
}
实现类r.java
package com.wsk.bigdata.mapreduce.reduce;import com.wsk.bigdata.pojo.Info;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;public class FileReduceJoinReducer extends Reducer<Text, Info, Info, NullWritable> {@Overrideprotected void reduce(Text key, Iterable<Info> values, Context context) throws IOException, InterruptedException {Info pInfo = new Info();List<Info> clickBeans = new ArrayList<Info>();Iterator<Info> iterator = values.iterator();while (iterator.hasNext()) {Info bean = iterator.next();System.out.println("reduce接收 "+bean);if ("1".equals(bean.getFlag())) { //产品try {BeanUtils.copyProperties(pInfo, bean);} catch (IllegalAccessException | InvocationTargetException e) {e.printStackTrace();}} else {Info clickBean = new Info();try {BeanUtils.copyProperties(clickBean, bean);clickBeans.add(clickBean);} catch (IllegalAccessException | InvocationTargetException e) {e.printStackTrace();}}}// 拼接数据获取最终结果for (Info bean : clickBeans) {bean.setpName(pInfo.getpName());bean.setPrice(pInfo.getPrice());bean.setProduceArea(pInfo.getProduceArea());System.out.println("reduce结果输出:"+bean.toString());context.write(bean, NullWritable.get());}}}
程序入口.java
package com.wsk.bigdata.mapreduce.driver;import com.wsk.bigdata.mapreduce.mapper.FileReduceJoinMapper;
import com.wsk.bigdata.mapreduce.reduce.FileReduceJoinReducer;
import com.wsk.bigdata.pojo.Info;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class ReduceJoinDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {if (args.length != 2) {System.err.println("please input 2 params: inpt_data output_mapjoin directory");System.exit(0);}String input = args[0];String output = args[1];System.setProperty("hadoop.home.dir", "D:\\appanzhuang\\cdh\\hadoop-2.6.0-cdh5.7.0");Configuration conf = new Configuration();FileSystem fs = FileSystem.get(conf);Path outputPath = new Path(output);if (fs.exists(outputPath)) {fs.delete(outputPath, true);}Job job = Job.getInstance(conf);job.setJarByClass(ReduceJoinDriver.class);job.setMapperClass(FileReduceJoinMapper.class);job.setReducerClass(FileReduceJoinReducer.class);// 指定mapper输出数据的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(Info.class);//定义Reducer输出数据的kv类型job.setOutputKeyClass(Info.class);job.setOutputValueClass(NullWritable.class);FileInputFormat.setInputPaths(job, new Path(input));FileOutputFormat.setOutputPath(job, new Path(output));boolean res = job.waitForCompletion(true);if (!res) {System.err.println("error:作业执行失败");}}
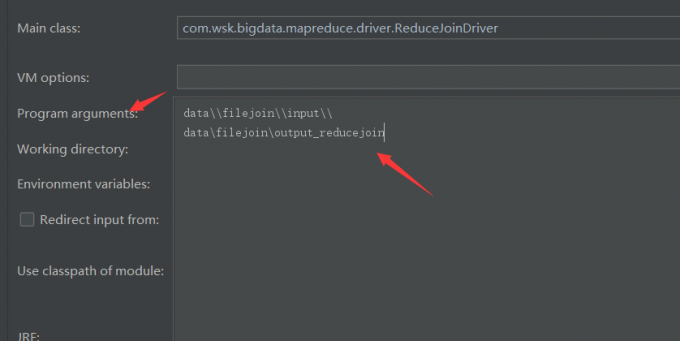
}程序运行的两个参数,第一是输入输入目录,第二个是输出数据目录
备注踩坑:
tags:
hadoop