NLP:预训练+转移学习
# pre-
目前神经网络在进行训练的时候基本都是基于后向传播(BP)算法,通过对网络模型参数进行随机初始化,然后通过BP算法利用例如SGD这样的优化算法去优化模型参数。那么预训练的思想就是,该模型的参数不再是随机初始化,而是先有一个任务进行训练得到一套模型参数,然后用这套参数对模型进行初始化,再进行训练。可以看成是第一层word 进行了预训练,此外在基于神经网络的迁移学习中也大量用到了这个思想 [来源]
#
迁移学习( ) 是把已训练好的模型(预训练模型)参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务都是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习[来源]
#
以情感分析(属于监督学习 )为例,探究一直以来是如何解决该NLP任务的?
Model
1️⃣ the model
(这些参数都是从头开始学习,模型需要从少量的标注数据集中学习语言的运作方式
2️⃣ all by using cross loss from set
Why train from (从头开始)?
How can we lots of data?
Model
we can the
(word ) using that takes of data (self-) 衍生出的技术如 、Glove
1️⃣ of with a word space, we start from a space in which word embs. some prop.
2️⃣ train all other from (
)
预训练语言模型的开山之作,由的两位作者 M. Dai和Quoc V. Le于2015年发表的《Semi- 》。
本文主要使用无标签的数据(即普通的文本)和RNN进行了两种尝试,实际上是通过两种不同训练目标来预训练了LSTM。第一种是训练模型去预测一句句子里下一个词是什么,这是一种典型的语言模型训练方法;第二种是训练模型成为一个自编码器(),用于将句子映射成向量后重建原来的句子。
这两种无监督训练得到的参数可以作为接下来有监督学习的模型的起始点,他们发现这样做了以后,可以使后续模型更稳定,泛化得更好,并且经过更少的训练,就能在很多分类任务上得到很不错的结果。
本文的核心倒不是模型架构本身,而是一种预训练的思路。该思路就是,利用无标签数据先训练模型(非监督学习un-),由此得到的参数,作为下一阶段模型训练的初始化参数(监督学习)。因此,本文取名半监督学习(semi-)[来源]
《 for to 》(2017)
这篇文章是在2017年ICLR会议上由 Brain团队 、Peter J. Liu、Quoc V. Le共同发表的,与上面介绍的 2015年发表的 Semi- 可谓一脉相承。本文描述了一种通用的非监督预训练方法,提升了模型的准确性。作者用两个语言模型的预训练权重分别初始化了模型的 与,然后再用监督数据对模型进行,这种做法在机器翻译和概要提取任务上大大超过了以前的纯监督模型,证明了预训练的过程直接提高了模型的泛化能力,再次提出了预训练的重要性和通用性。这篇文章最大的贡献是证明了在大量无监督数据上预训练语言模型,并在少量有监督数据上这个思路对模型同样具有效性 [来源]
存在的问题:
1️⃣ word embs. are , only one per word type of .
2️⃣ the rest of the model (in our case, the RNN) is for from given just data
what if we use the of a NLM of word ?
Model
每个时刻 t 的隐藏状态里编码了当前与之前词汇的信息,离得越近的词汇在向量里占的比重更大,这些向量比起之前的 word embs更蕴含了上下文信息
将NLM中学习到的 作为初始词向量应用到情感分析,即
为了更好的学习上下文,通常是 Left-to-Right 和 Right-to-Left 双向编码
Model
ELMo就是这么做的。使用了分离的两个LMs:一个Left-to-Right,一个Right-to-Left,将结果形成一个
Can we share more than just the word ? what about
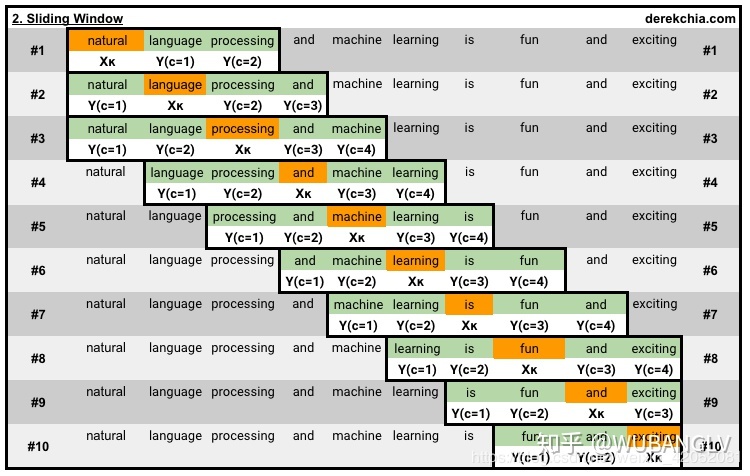
?
NLM
my RNN with the LMs
,all we have to do is learn
from , all the other are .
Model
This is (范式) in NLP, by BERT model.
We init our model with a NLM, and then the error from a task ( task) into these . This is fine-
# ELMo(2018.2)
《Deep Word 》作者认为一个预训练的词表示应该能够包含丰富的句法和语义信息,并且能够对多义词进行建模。而传统的词向量(例如)是上下文无关的,无法对一词多义进行建模。所以他们利用语言模型来获得一个上下文相关的预训练表示,称为ELMo( from Model)
在ELMo中,他们使用的是一个双向的LSTM语言模型,由一个前向和一个后向语言模型构成,目标函数就是取这两个方向语言模型的最大似然。
先在大语料上以 Model为目标训练出 LSTM模型,然后利用LSTM产生词语的表征。为了应用在下游的NLP任务中,一般先利用下游任务的语料库(注意这里忽略掉label)进行 model的微调,这种微调相当于一种 ,然后才利用label的信息进行 。
ELMo的语言模型经过权衡了模型性能、大小、以及所需算力定为两层双向LSTM,每层4096个units,512维。
ELMo表征是“深”的,就是说它们是biLM的所有层的内部表征的函数。这样做的好处是能够产生丰富的词语表征。高层(第二层)的LSTM的状态可以捕捉词语意义中和语境相关的那方面的特征(比如可以用来做语义的消歧),而低层(第一层)的LSTM可以找到语法方面的特征(比如可以做词性标注)。如果把它们结合在一起,在下游的NLP任务中会体现优势。( 最简单的也可以使用最高层的表示,但论文的实验结果表明:使用所有层的效果要比只使用最后一层作为ELMo的效果要好。
论文揭示了,预训练语言模型能生成深层特征是关键,下游任务可以混合不同层的半监督语义信号,来提高自己的效果。
当有多个 state时,如何选择?
然后进行有监督的NLP任务时,可以将ELMo直接当做特征拼接到具体任务模型的词向量输入或者是模型的最高层表示上(在输入还是输出上面加ELMo效果好的问题上,并没有定论,不同的任务可能效果不一样。
ELMo的使用流程主要如下:
1️⃣ 首先,在较大的语料库中预训练biLM模型,使用两层Bi-LSTM,并使用残差连接,作者提出,低层(第一层)的Bi-LSTM能获取语料中的句法信息,而高层(第二层)能获取语料中的语义信息。
2️⃣ 其次,在我们任务的语料中(忽略标签的)fine 微调预训练好的biLM模型,称为 。
3️⃣ 最后,在具体的任务中,我们使用ELMo输出的词嵌入作为下游任务的输入,也可以作为下游任务的输出层。
#Open AI GPT(2018)
GPT: Pre-
《 by Pre-》这篇论文的亮点主要在于,他们利用了网络代替了LSTM作为语言模型来更好的捕获长距离语言结构。然后在进行具体任务有监督微调时使用了语言模型作为附属任务训练目标。
在语言模型网络上他们使用了团队在《 is all your need》论文中提出的解码器作为语言模型。在具体NLP任务有监督微调时,与ELMo当成特征的做法不同, GPT不需要再重新对任务构建新的模型结构,而是直接在这个语言模型上的最后一层接上作为任务输出层,然后再对这整个模型进行微调。如果使用语言模型作为辅助任务,能够提升有监督模型的泛化能力,并且能够加速收敛[链接]
目前将预训练的语言模型应用到NLP任务主要有两种策略,一种是基于特征的语言模型,如ELMo模型;另一种是基于微调的语言模型,如 GPT。
GPT采用了Pre-(预训练)和Fine-(微调)的训练方法,目标是学习一种通用的表示形式,该表示形式几乎不需要怎么调整就可以适用于各种NLP下游任务。
首先,对未标记的数据建立语言模型,学习神经网络模型的初始参数。随后,使用相应的有监督的方式将这些参数调整为NLP下游任务所需要。即整个训练过程包括两个阶段,第一阶段是在大型语料库上使用无监督的方式训练。随后是微调阶段,使用的是当前任务的有监督数据。
由于不同NLP任务的输入有所不同,在模型的输入上针对不同NLP任务也有所不同。具体如下图,1️⃣ 对于分类任务直接将文本输入即可;2️⃣ 对于文本蕴涵任务,需要将前提和假设用一个Delim分割向量拼接后进行输入;3️⃣ 对于文本相似度任务,在两个方向上都使用Delim拼接后,进行输入;4️⃣ 对于像问答多选择的任务,就是将每个答案和上下文进行拼接进行输入。
在四种类型的语言理解任务上评估该方法,分别是:自然语言推理,问题回答,语义相似性和文本分类任务。在12个子任务中有9个达到了当时的最先进水平(state of the art)。
# BERT(2018.10)
《BERT: Pre- of Deep for 》BERT ( ) 是使用编码器来作为语言模型,在语言模型预训练的时候,提出了两个新的目标任务:
1️⃣遮挡语言模型 Model
- given a full of words(not just ) where x%(通常为15%) of the words have benn out
- of the next word, we only words
2️⃣预测下一个句子Next
BERT为了让下游的问答(QA)和自然语言推理(NLI)任务能够进行,增加了另一个预训练任务,在 BERT 的训练过程中,模型将两个句子为一对作为输入,预测第二个句子是否在原始文档中是第一句的后续句子。
在实际预训练过程中,文章作者从文本语料库中随机选择50%正确语句对和50%错误语句对进行训练,与 LM任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。
在语言模型上,BERT使用的是编码器,并且设计了一个小一点的Base结构和一个更大的Large网络结构。
BERT本质上是一个训练好的 堆栈。Base 版本有12层,Large版本有24层。它们也比初始论文里的的默认配置(6个编码器层,512个隐藏单元,8个 heads)有更大的前馈网络(分别为768个和1024个隐藏单元), heads(分别为12个和16个)。
在论文中他们训练base版本需要在16个TGPU上,large版本需要在64个TPU上训练4天,对于一般条件,一个GPU训练的话,得用上1年。
对比一下三种语言模型结构,BERT使用的是编码器,由于self-机制,所以模型上下层直接全部互相连接的。而 GPT使用的是解码器,它是一个需要从左到右的受限制的,而ELMo使用的是双向LSTM,虽然是双向的,但是也只是在两个单向的LSTM的最高层进行简单的拼接。所以作者们认为只有BERT是真正在模型所有层中是双向的。
在之前,我们提到过ELMo,虽然都说是“双向”的,但目标函数其实是不同的。ELMo是分别以
和
作为目标函数,训练后拼接在一起,而BERT则是以
直接作为目标函数训练,所以可以理解为BERT是真正的双向!
而在模型的输入方面,BERT做了更多的细节。将英文词汇作进一步切割,划分为更细粒度的语义单位(),例如:将分割为play和##ing,并加入了位置向量和句子切分向量。并在每一个文本输入前加入了一个CLS向量。
对于不同的NLP任务,模型输入会有微调,对模型输出的利用也有差异。
## LM
文章作者在一句话中随机选择15%的词汇用于预测。对于在原句中被抹去的词汇,80%情况下采用一个特殊符号[MASK]替换,10%情况下采用一个任意词替换,剩余10%情况下保持原词汇不变。这么做的主要原因是:在后续微调任务中语句中并不会出现[MASK]标记,而且这么做的另一个好处是:预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇(10%概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。
例如对于“my doy is hairy”这句话:
## From ELMo(2018.2) To BERT(2018.10)
the ELMo of two LMs that are then is a hacky...
- can we the same goal a model
- :from LM to LMs
2 LMs 1 LM
BERT was on a lot more data
ELMo 通过读人上文来预测当前单词的方式为词嵌入引入了上下文信息,而的BERT模型则通过一种高效的双向 网络同时对上文和下文建模。
# GPT-2(2019)
在论文《 are 》中,GPT-2被提出,可以认为GPT-2是GPT的升级版!
GPT-2在GPT的基础上,有以下几个大变化:
1️⃣ 使用的训练数据更多、更高质量、更宽泛
找了800万互联网网页作为语言模型的训练数据,在论文中称为,网页中的内容宽泛,训练的模型通用性好,这数据大概有40GB。