训练集噪声对于深度学习的影响
总所周知,在深度学习的训练中,样本的质量和数量都是非常重要的一环。然后在实际的生产过程中,样本的数量往往可以通过一些手段得到满足,但是质量却非常依赖人工的标注,因此往往在训练中会包含一定数量的标注不正确的数据。一般认为这样的一些数据,会对于最终的结果造成负面影响,但是具体怎样影响训练和最终的模型推广效果我们来做一个小实验。
实验设置
使用工具 :MXNET
数据集:MNIST
训练集大小:60000
测试集大小:10000
分类类别数目:10 类
实验流程:
训练时,将训练集中的一定比例的样本重新赋一个标签值,标签为[0,9]中的一个随机数,来模拟训练集中的脏数据,
训练超参数:
MXNET默认:初始化学习率:0.05, 在第10个ephos时候降为0.005,20个 停止迭代。优化方法SGD,使用的模型为经典的LeNet。
实验结果:
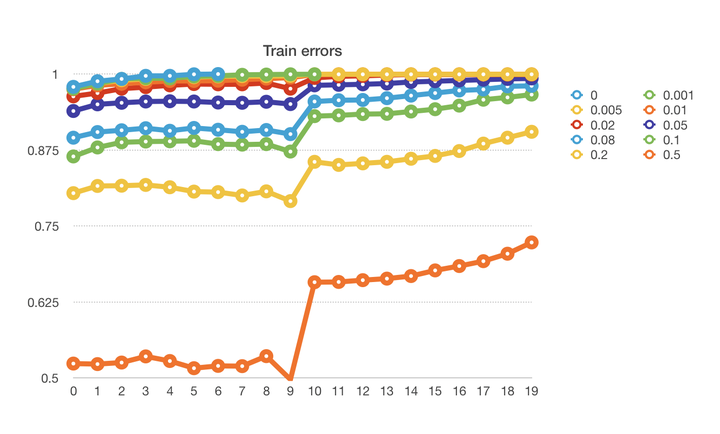
训练集上的准确率:
验证集上的准确率:
实验结果分析:
较大学习率下训练时,可以明显发现随着脏数据的增加,训练集中的准确率降低与脏数据的比例成正相关,且脏数据的比例越大训练集中的准确率波动也就越大,这些都是符合一般的预期的,即随着不靠谱的样本的增加,训练的难度加大,本身的准确率也没办法继续提高,且波动也会教导。
但是我们很惊奇的发现,在验证集上较大学习率的情况下,甚至在脏数据占比达到骇人听闻的20%的情况下,在一开始的几个epoch上,准确率都没有断崖式的下降,但是随着迭代的轮数的增加,当比例大于2% 都会出现断崖式的下降。从这个现象我们可以发现,神经网络的学习能力以及推广能力还是非常强悍的,在开始的时候学习到的都是杂乱数据中的有效特征,但是随着迭代轮数的增加,样本里面一些不正确的信息还是会添加到模型中来, 导致推广能力的下降,即过拟合了。
当学习率降低十分之一后,在训练集中,大比例脏数据的模型在训练集上的准确率都得到了明显的提高,证明当学习率下降后,模型的学习能力得到了提高,会强行学习一些并不一定正确的样本中的信息,并得到新的区分样本类别的方法,而且从图上可以发现,随着迭代轮数的增加,准确率会不断的提高,说明学习率较小的情况下,脏数据也是会被模型不断的学习到的。
当学习率较小时,验证集上面的结果要比大学习率的情况下变得稳定许多,甚至在脏数据比例高达10%的情况下依旧保持了96%的准确率,并且随着迭代轮数的增加,基本保持稳定。在此再次感慨下深度学习网络的推广能力。但是当脏数据的比例达到20% 以上的时候,我们发现随着学习到的脏数据的不断增加,模型在验证集上的能力也会随之下降,这和我们的直观感觉也是符合的。
总结和结论:
本文讨论了在训练数据集中混有脏数据的情况下,所得模型在训练和测试样本集上的表现情况,发现
大学习率下,模型会首先学习有效样本中的特征信息,然后再学习到脏数据中的信息,并随着脏数据的增加和迭代次数的增加在验证集上,识别率出现断崖式的下降 调小学习率的情况下,模型的学习会变得稳定许多且受到脏数据的影响明显减少,也不容易出现断崖式的下降,但是随着脏数据的比例不断的扩大,模型学习到的脏数据的信息也会对于模型的推广能力造成不可忽视的影响。 因此在带有脏数据的数据集上学习,建议使用较小的学习率,同时保证验证集的准确性,当发现训练集识别率不断提高,但是在验证集上反而下降时,此时就可以怀疑时学习到了脏数据的信息,及时停止训练应该也可以得到不错的效果 最后再次感慨下深度学习变态的推广能力