多目标学习(Multi-task Learning)-网络设计和损失函数优化
目前多目标学习主要从两个方向展开,一个是网络结构设计,一个是损失函数优化;
一、MTL网络设计
MTL网络通常可分为两种,一种是hard- 不同任务间共用底部的隐层,另一种是soft- ,形式较为多样,如两个任务参数不共享,但对不同任务的参数增加L2范数的限制;也有一些对每个任务分别生成各自的隐层,学习所有隐层的组合;这两种方式各有优劣,hard类的网络较soft不容易陷入过拟合,但如果任务差异较大,模型结果较差,但soft类网络通常参数较多,结构比较复杂,线上部署困难;
1、hard-
hard- 为不同任务底层共享模型结构和参数,顶层分为几个不同的目标进行网络训练
这种结构本质上可以减少过拟合的风险,但是效果上可能受到任务差异和数据分布带来的影响
基本上,只要是能预测单模型的模型,都可以很简单的转化为hard- 的结构,只需要将共享层的最后一层与多个输出层拼接即可。
2 soft-
soft- 不同于hard- model,每个任务有自己的参数,最后通过对不同任务的参数之间的差异加约束,表达相似性。比如可以使用L2, trace norm(迹范数)等。
网络结构如下:
3、相关技术 3.1 MMoE 谷歌2018
其中(a)是传统的硬共享参数模型,(b)是MoE模型,使用单个gate控制多个任务的参数,(c)是MMoE模型,在MoE的基础上,每个任务使用一个gate控制其权重。
名词解释:
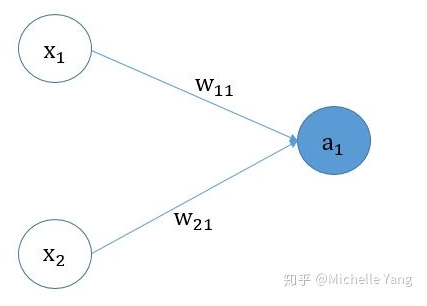
a、:指对模型输入进行不同方式的变换处理的网络层,每个表示一种网络(也可以都一样)
b、gate:控制每个权重的变量,对于每一个任务,不同的权重可能是不一样的,因此使用gate来控制权重,类似于
MoE模型对于不同的任务的gate权重是一样的,其函数表达式如下:
y k = h k ∑ i = 1 n g i f i ( x ) y^k=h^k\sum_{i=1}^{n}(x) yk=hki=1∑ngifi(x)
其中k表示第k个任务,n表示n个网络
MMoE是在MoE的基础上提出的方法,作者认为对于不同的任务,模型的权重选择是不同的,所以为每个任务分配一个gate模型。对于不同的任务,gate k的输出表示不同被选择的概率,将多个加权求和,得到f_k(x),并输出给特点的Tower模型,用于最终的输出。
MMoE模型的表达式如下:
f k ( x ) = ∑ i = 1 n g i k ( x ) f i ( x ) f^k(x)=\sum_{i=1}^{n} g_i^k(x)f_i(x) fk(x)=i=1∑ngik(x)fi(x)
g k ( x ) = s o f t m a x ( W g k ( x ) ) g^k(x)=(W_{g^k(x)}) gk(x)=(Wgk(x))
类似于MoE,k表示第k个任务,每个任务对应一个gate。
MMoE的底层参数仍然是共享的,但是通过目标和网络参数直接的gate来学习,让每部分网络充分学习到对每个目标的贡献最大的一组参数结构,通过这种方式来保证,底层网络参数共享的时候,不会出现目标之间相互抵消的作用。
3.2 SNR 谷歌2019
论文地址为:
SNR 是MMOE作者对多任务学习的进一步工作,为了尽量共享不同任务之间的信息,提高精度,也节约线上服务代价而提出的一种算法。
其结构图如下
主要优化点:
把网络结构的跨任务参数共享抽象为网络子结构的路由问题;
引入0-1隐变量对路由作最优化;
通过L1正则化(可以得到参数量更小的网络),学到稀疏解,同等精度下节约11%的网络结构开销
SNR-Trans 可形式化为如下表达
hard 可形式化为
u是0,1之间的随机分布函数 β, γ, ζ 都是超参数
加L1正则化的损失函数可表示为
其中,q是s的累计概率分布函数
线上的的时候,z简化为
可参见:网友的中文翻译
二、损失函数优化
现有的损失函数优化方法大概有如下几类
1、 ——梯度标准化
: for loss in deep 》 ICML 2018
论文参考链接:
希望不同的任务Loss量级接近;不同的任务以相近的速度来进行学习。
【评价】
优点: 既考虑了loss的量级,又考虑了不同任务的训练速度。
缺点:每一步迭代都需要额外计算梯度,当W选择的参数多的时候,会影响训练速度;
此外,该loss依赖于参数的初始值;如果初始值变化很大的话,paper建议可以采用其他值代替,比如分类任务,可以用 l o g ( C ) log(C) log(C)来代替初始值,C是类别数量。
其梯度损失( Loss)函数定义为,各个任务实际的梯度范数与理想的梯度范数的差的绝对值和,可表示为:
其中 G i w ( t ) G_i^w(t) Giw(t)是任务i梯度标准化的值,是任务i的权重 w i ( t ) w_i(t) wi(t)与loss L的乘积对 L i ( t ) L_i(t) Li(t)参数W求梯度的L2范数, G i w ( t ) G_i^w(t) Giw(t)可以衡量某个任务loss的量级; G ‾ W ( t ) \ G_W(t) GW(t)是全局梯度标准化的值(即所有任务梯度标准化值的期望值),通过所有 G i w ( t ) G_i^w(t) Giw(t)求均值实现。
计算完 Loss后,通过以下函数对 w i ( t ) w_i(t) wi(t) 进行更新(GL指 Loss):
w i ( t + 1 ) = w i ( t ) + λ ∗ G r a d i e n t ( G L , w i ( t ) ) w_i(t+1)=w_i(t)+\*(GL,w_i(t)) wi(t+1)=wi(t)+λ∗(GL,wi(t))
α是超参数,α 越大,对训练速度的平衡限制越强
2 、 ——动态加权平均
参见论文:《End-to-End Multi-Task with 》,CVPR 2019
论文作者知乎:(Multi-task and : 过去,现在与未来)
直观来看,loss缩小快的任务,则权重会变小;反之权重会变大。
w k ( t ) w_k(t) wk(t) 代表了每个任务i的权重, L n ( t ) L_n(t) Ln(t) α n t \{n}t αnt分别代表任务k在t时刻的loss,和训练速度,n代表任务数,t足够大时,w趋近于1
【评价】
优点:只需要记录不同step的loss值,从而避免了为了获取不同任务的梯度,实现简单,运算较快。
缺点:没有考虑不同任务的loss的量级,需要额外的操作把各个任务的量级调整到差不多。
3、 Task ——动态任务优先级
参见论文:《 task for 》,ECCV 2018,Cites:53
DTP希望让更难学的任务具有更高的权重
其不同任务的权重为
F L ( p c ; γ 0 ) = − ( 1 − p c ) γ 0 l o g ( p c ) FL(p_c;\)=-(1-p_c)^{\} log(p_c) FL(pc;γ0)=−(1−pc)γ0log(pc)
4、 ——不确定性加权
论文地址:《Multi-task using to weigh for scene and 》
Keras 实现参见:
其他有价值的参考链接:
让“简单”的任务有更高的权重
最终的loss为
其中, δ 1 \ δ1和 δ 2 \ δ2 是两个任务中,各自存在的不确定性。
因此, δ 2 \delta^2 δ2越大,任务的不确定性越大,则任务的权重越小,即噪声大且难学的任务权重会变小。
【评价】
优点:不确定性建模似乎可以适用于标签噪声更大的数据,而DTP可能在干净的标注数据里效果更好
缺点:参考:
5、帕累托最优( )
参见论文:Multi-Task as Multi- ()
地址为:
task- 方法都基于一些特定的 ,很难保证在 MTL 取得 . 在该论文中,作者将 MTL 问题看做是多目标优化问题,其目标为取得 .
论文的损失函数为
是指任何对其中一个任务的效果变好的情况,一定会对其他剩余所有任务的效果变差。作者利用了一个叫 (MGDA) 的方法来寻找这个 point。大致方式是,在每次计算 task- 后,其得到 来更新共享参数。这个 如果存在,则整个 并未收敛到 。这样的收敛方法保证了 共享参数不会出现 让每一个任务的 loss 收敛更加平滑。
三、MTL Tips
可参见:
部分tip罗列如下:
7 某些估计作为特征(交替训练)
【参考链接】
1、
2、
3、(帕累托最优)
4、
5、新火试茶