Single Image Action Recognition using Se
前言
小组最近在做基于骨骼点的动作识别课题,在找到了一篇ICCV 2017的“ Image using Body Part ”()觉得对基于身体局部的动作识别有很多很好的想法,且作者也公布了caffe的开源代码,小组也正在使用 ,keras重写,现特地分享给大家,若有不准确的地方,欢迎大家指正。
概要
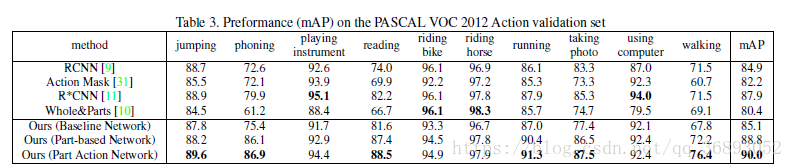
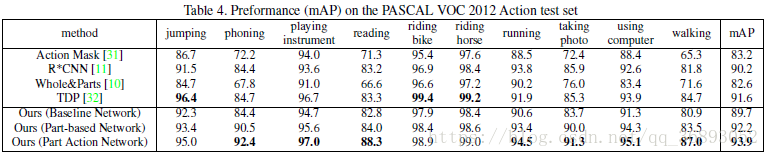
在这篇文章中,作者提出了基于人体局部区域的语义特征进行单张图片的人体动作识别。不同于以往(2017年以前)的方法,作者提出了三种具有中级语义信息的身体局部动作语义特征,并通过组合这些特征和上下文信息来达到人体动作识别。在本文中,作者将人体身体分成了7个部分:头,躯干,手臂,手,下肢。对每一个部分,会定义一些身体局部的语义信息(例如,头:笑)。最后,通过利用这些局部动作来识别整个动作(例如,鼓掌)。为了实现这些idea,作者提出了由两个子网络组成的深度神经网络作为框架,一个用于局部位置的回归,一个用于动作的识别。动作识别网络会组合身体局部特征与身体特征,并对组合后的特征进行分类。作者在 VOC数据集上的mAP为93.9%,-40上的mAP为91.2%,比最新最好(2017年)的方法分别提升2.3%,8.6%。
介绍
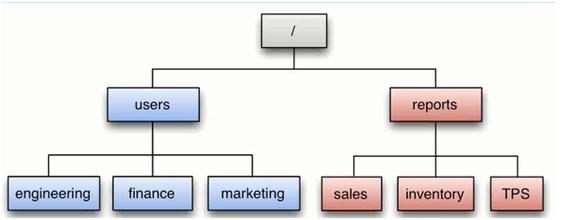
已有的基于身体局部的动作识别方法都是通过身体的局部获取特征,但是身体局部的特征与整个动作还是有差别的,如图1,对于已有的方法,会认为手上拿着一个杯子的可能会被认为是“喝酒”,即是头部区域判断为“带眼睛”也很难对将喝酒的动作纠正为“倒酒”。
作者认为中级语义信息在链接身体局部特征与身体动作识别中很重要。例如图1中,通过局部特征的语义信息会认为人的手是向下,胳膊是弯曲向下,动作识别为“倒酒”的可能性就会大于“喝酒”。
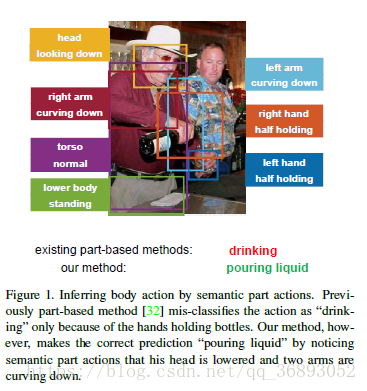
作者设计的网络结构如图2,首先利用骨骼关键点预测网络找到身体局部位置(头,躯干,手臂,手,下肢)。然后,身体与身体局部图像输入到Part (PAN)中预测动作。PAN有多个通道组成:两个body 分别输入原始图像与身体局部区域图像,作为常用的分类网络进行动作识别,part 预测身体局部动作,并融合局部动作与身体动作。在part 中,定义一组身体局部动作,例如“head: up”,“hand:”。
这篇文章作者的主要贡献为三个方面:
1.提出了用身体局部动作来识别人体动作。
2.提出融合局部动作与全身动作的识别方法
3.提出的方法在已有最好方法上有提升
已有工作
1.单张图片的动作识别
2.基于局部动作的方法
3.姿态估计与骨骼关键点
在上述网络中,作者需要先找到身体局部的位置,作者采用先使用人体姿态估计的方法找到骨骼点,作者使用了的方法找骨骼点,再通过这些骨骼点来得到身体局部区域位置。
局部动作语义 局部动作作为中级语义信息
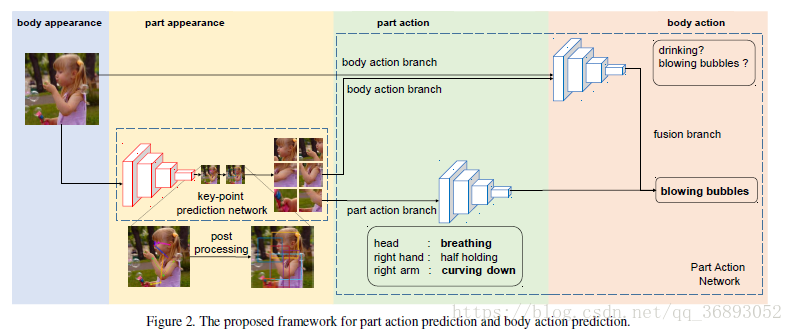
作者认为整个人体动作不仅仅是身体和部位外观的直接组合,还应该有一个中级语义信息,即人体局部动作。如上图3©所示,局部动作从图像特征得来,使用中级语义特征以帮助推断身体动作。例如,如下图4中第二行所示如果局部动作为“head: down”,“torso:”,“arms: down”,“hands:fully ” “lower body:”,即是我们没有看到这张原图,我们也能猜测这个动作是“ ”。

局部动作的定义
就作者所知,在他当时没有关于局部动作语义信息的工作(2017年)。所以,需要先定义一组局部动作的语义信息。
首先定义7个身体部分:头,躯干,下肢,手臂,手。将每个部分定义下相关动作。若下表1所示:
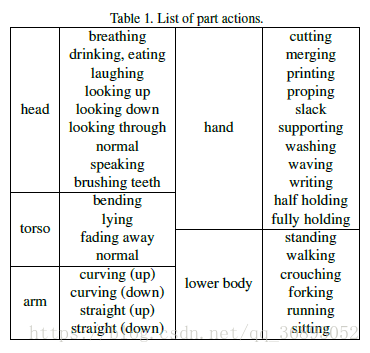
动作识别
作者设计的网络为PAN,如图2所示,首先使用人体姿态估计网络预测人体骨骼点,并通过预处理得到图像的 boxes。然后,使用PAN网络进行局部动作识别与动作识别。
身体局部位置的定位
使用骨骼关键点网络来定位身体局部位置。之所以选择这关键点网络有两个原因:(1)关键点基本上是显示部件的位置,部分边界可以通过后处理生成框。(2)有很多关于骨骼关键点公开的数据集与标签,而且很多都有开源。
作者选用在MS-COCO数据集上表现很好的Part (PAF)来处理-40 和 数据集。
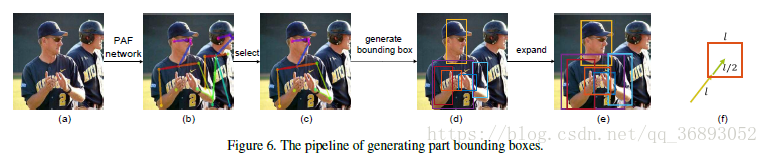
如上图6所示,输入一张图片到PAF网络,得到图像中所有人的骨骼点坐标。再选择其中概率最大人的骨骼点,并根据骨骼点的坐标求出其身体局部 boxes。
例如,求躯干的 boxes,就只选用肩膀与臀部的骨骼点。对于头部,选择鼻子的坐标作为 box为中心,到耳朵/眼睛的距离为宽。对于其他部位的 box的选择,需要根据具体规则来选择,所有的 box都会扩大50%。如果该位置没有骨骼点,则使用空白图像作为占位符(这里作者处理的细节还没有看*_*)。
局部与身体动作识别
使用PAN网络接受原始图像、身体局部区域作为输入,并学习出身体局部动作,身体动作并融合,最后识别出动作。作为比较,作者使用了图7的 进行对比。
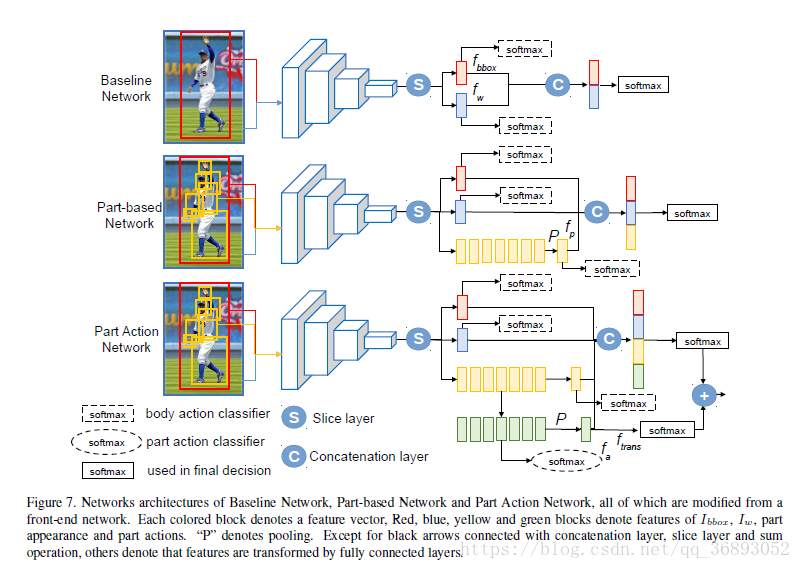
1.
输入原始图片与 box,即提前将每张图片的人体 box求出。如图7所示,输入为两种图片,即原始图片 I w I_w Iw, box 图片 I b b o x I_{bbox} Ibbox使用50-layer的 作为front-end卷积网络,将两种图片调整到再前向传入front-end网络中,pool5上的Slice层得到特征 f b b o x f_{bbox} fbbox (如图中红色块)和 f w f_w fw(如图中蓝色块),最后再结合两者特征得到分类结果。在训练的时候,需要训练三个损失函数,但是在测试的时候仅仅只求最后最后输出分类的概率值。
2.Part-based
基于 ,增加了一个捕捉身体局部特征的通道(如图黄色块)。除了输入上述的 I b b o x I_{bbox} Ibbox和 I w I_{w} Iw,所有的位置身体局部部分需要提前处理出来,全部到并前向传播到网络中。多个身体部位(图中7个黄色)会通过全连接层转换为单一的特征 f p f_p fp。最后联合三种特征 f b b o x f_{bbox} fbbox, f w f_w fw, f p f_p fp进行分类并输出最终概率。
3.Part
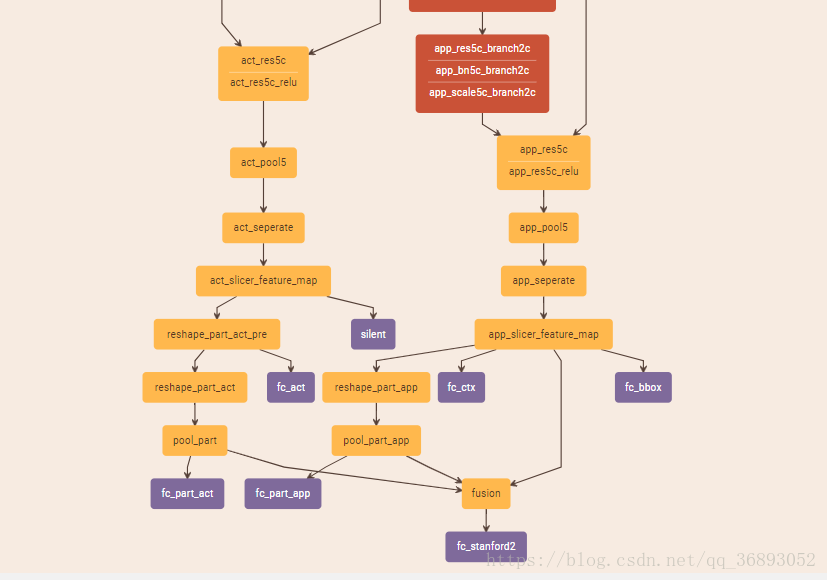
在PAN中,添加了一个学习与预测局部动作的通道(绿色块),结合全部的身体动作识别与局部动作的位置。Part 首次将局部位置特征(图中7个黄色)求得局部动作特征(图中7个绿色),并使用全连接 f c t e a n s fc_{teans} 将局部动作特征转换为动作特征(单个绿色块, f a f_a fa)。通道联合了四个特征,并最终做出分类。
为了避免在身体动作与局部身体动作标签的冲突,作者在局部动作标签上增加了偏执。例如,-40数据集由40种动作( C b i a s = 40 C_{bias}=40 Cbias=40),那么身体的第一个部分(“head:”)就被认为是第41种动作,对于不可见的身体部分,使用blank 来代替,所以最终我们有40+34+1=75种概率得分。
在本文中,作者在-40数据集上做出标签。若想在另一数据集上使用:首先在-40数据集上预训练PAN网络,然后固定身体局部预测通道,fine-tune另外的通道。
实验
网络:作者比较了如图7的三个网络,其中使用了在上的作为pre-,学习率为 1 0 − 5 10^{-5} 10−5,5K ,batch size=20。使用了, ,scale 三种数据增强,使用caffe框架,硬件为一张Titan X GPU
数据集:选用两种数据集
(1) VOC 2012:10种不同的动作,每个动作大概有400~500张图片
(2)-40:40种不同动作,每个动作训练集大概100张图片,如下图8所示:

这里的实验有兴趣的同学再去看看原文,我在这里贴两个图看看,