Prompt的科学范式(上篇)
相信很多人在用LLM做下游任务时,能够感受到不同写法的重要性。同样的一段文本,不同的 写法可能会得到完全不同的结果。因此,了解和掌握写法是非常必要的。
本文将从的定义和作用以及演进和写作的科学范式两个方面为大家详细介绍。
1 的定义和作用
提示()是指一段用于引导模型理解问题的文本,通常位于问题的开头或结尾。它用于为模型提供上下文和任务要求,以帮助模型更好地理解和回答问题。
例如:你想让写出一篇文章,文章的题目是“我有一个朋友叫张三”,那么就可以写成:
请以"我有一个朋友叫张三"为开头,写一篇关于张三的文章,不少于500字。请以"我有一个朋友叫张三"为开头,写一篇关于张三的文章,不少于500字。
将上述输入给大模型,大模型就会输出你想要的结果,如:
上述流程如下:
上述:“请以"我有一个朋友叫张三"为开头,写一篇关于张三的文章,不少于500字”,是一种最简单随意的写法,对于简单任务也能产生可以接受的结果,但是我们想要利用大模型对复杂的下游任务进行赋能,的写法对于效果的保证就显得至关重要了。
2 的演进以及科学写作范式
由于AI幻觉的问题,大模型的输出并不能保证准确;然后很多应用对于程序的准确输出都有严格的要求,这就导致大模型在实际业务落地过程中并没有想象中的顺利,为了尽可能的保证模型输出的准确性,研究者从的编写方式上进行探索,产生了一系列有意思的研究成果;本文将对的演进和科学写作范式进行梳理,接下来的内容将按下图所示进行展开。
本文是《的科学范式》上篇,将介绍Input- 以及CoT的写作技巧。
2.1 input- 2.1.1 zero-shot
zero-shot顾名思义就是零样本,就是在中不加任何和任务相关的示例。
现在的大型语言模型(如GPT-3.5)经过微调后,能够遵循指令,并且在大量数据上进行训练,因此它们能够在没有事先训练的情况下完成一些任务。下面是一个示例:
需要注意的是,在上述提示中,并没有提供任何带有分类的文本示例给模型,大型语言模型已经理解了“情感”--这就是其zero-shot的体现。
当zero-shot无法达到预期效果时,在提示中提供少量的示例可以明显的提升推理的效果,即few-shot。
2.1.2 Few-Shot
few-shot 的意思是指在中加入和推理任务相同的推理样例。
如任务:使用一个词语进行造句。
可以观察到,通过仅提供一个示例(即1-shot,中标红的部分即示例),模型已经学会了如何执行任务。对于更困难的任务,可以尝试增加示例(例如3-shot、5-shot、10-shot等)进行实验。
2.1.3 input- 的限制
标准的Few-shot提示在许多任务中表现良好,但并不是一种完美的技术,特别是在处理更复杂的推理任务时。
比如任务:判断一个数字序列之和是否是偶数。
这个回答不正确,说明简单的直接命令无法解决这个问题,需要更先进的提示工程。添加一些样例(few-shot),看看少样本提示是否可以改善结果。
few-shot也没有奏效。对于这种类型的推理问题,少样本提示不足以获得可靠的回答。总体而言,提供示例在解决某些任务时是有用的。当零样本提示和少样本提示不足时,这可能意味着模型所学到的内容不足以在任务上表现良好。从这里开始,建议考虑对模型进行微调或尝试更先进的提示技术。接下来,将介绍一种更为实用的提示技术,称为"思维链"(CoT)提示,它在各个领域中已经广受欢迎。
2.2 CoT
和input- 直接给出答案不同的是,chain of (CoT)技术通过引导大模型先给出推理过程,再给出最终答案。
引导方法分为两种,分别为zero-shot CoT和few-。
2.2.1 zero-shot-CoT
zero-技术理解起来比较简单,是在zero-shot的基础上添加指令:“一步一步的思考给出答案”。如下图:
再尝试一个简单的数学计算问题,看看模型的表现如何:
zero-shot的方式模型回答错误,zero-在给出推理计算过程后,给出了正确答案。
zero-在没有太多样例的时候用于提示时特别有用。
2.2.2 few-shot-CoT
同zero-shot和zero-的区别一致的是,few-是在few-shot的基础上给出答案的推理过程来引导大模型进行思考。如下图是1-的样例:
使用few-shot的方式并没有获取到正确的答案,而使用few-的方式模型在给出推理过程后,给出了正确的答案。
总结如下:
我们再来做个实验:先给出答案,再让模型给出推理过程,看看效果如何,如下图:
先给出答案,再进行推理的方式,模型回答错误。
结论:先给出答案再进行推理的模板,发现效果显著变差。说明few-shot-CoT只是激活模型给出推理,推理过程本身才是模型效果提升的核心。目前在一些需要推理的多项选择问题上也发现,先推理再回答选项的效果显著优于先回答选项再给出推理过程。
2.2.3 Chain-of- (Auto-CoT)
few-的提示方式的效果依赖人工设计的few-shot,有人提出Auto-CoT来自动构建few-shot。
Auto-CoT 有两个实现阶段:
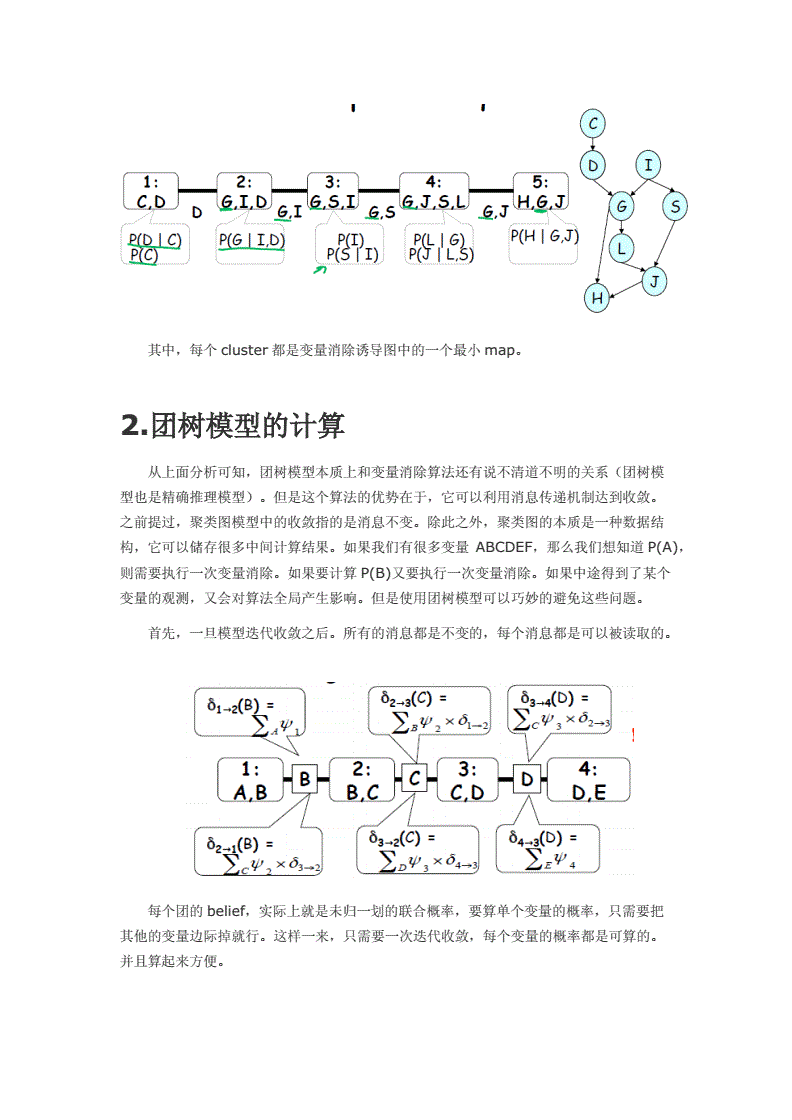
上图详细说明如下:
第一步:提供问题列表;
第二步:对进行聚类,得到K类问题[qs1, qs2...qsk];
第三步:每类问题抽样一个问题得到K个问题[q1, q2...qk],并基于zero-技术对每个问题,生成推理过程和答案,得到K个示例[(q1,a1), (q2,a2)...(qk,ak)];
第四步:将得到的K个示例组装成few-的;
第五步:使用大模型得到最终结果;
2.2.4 CoT-SC
上述提到的zero-shot、few-shot、zero-和few-都是贪婪解码的方式,在一条推理链上得到最优的结果。如同很多过程一样,贪婪解码的结果并不是全局最优的结果。
chain of self-(CoT-SC)的核心思想是通过few-技术,采样多个不同的推理路径,并利用这些生成结果选择最一致的答案,即全局最优的答案,有助于提高算术和常识推理任务中的性能。
下图是针对一个算术问题的few-以及CoT-sc两种技术的实现案例:
直接通过few-shot CoT的方式输出答案是错误的!下面通过CoT-sc的方式来改进。
可以看到已经出现了明显的多数答案,通过投票机制,可以得到最优的最终答案。
SC-CoT是通过使用相同的多次调用大模型,得到多个答案,再通过投票机制选择大多数一致的答案作为最终的答案。
这里的关键在于相同的多次调用得到不同的回复,所以需要在调用大模型的时候将和top_p都设置为一个较大的值。(和top_p参数越大,模型输出越泛化)。
2.2.5 least-to-Most
大量的应用中发现,当LLM需要解决的问题比few-shot给出的样例更有难度的时候,无论是上述哪种方式都无法较好的解决问题。
为了解决这个问题,有人提出了least-to-most(L2M,从最少到最多)的的写作范式。
least-to-most基于以下策略:
因此,从L2M的提示是一种使用逐步提示序列来得出最终结论的技术,其过程如下图。
下面是一个具体的实现案例:
将问题和答案依次输入给大模型,模型在回答第四个子问题的时候就已经给出了正确答案。
3 结语
在过去的一段时间里,人工智能领域中的大型模型如、等已经取得了惊人的成果,它们在各种自然语言处理任务中表现出了卓越的性能。这些大模型的出色表现,除了得益于模型的规模和训练方法之外,还有一个非常重要的因素,那就是使用良好的提示()的来引导大模型给出我们想要的输出。