学习笔记:哈夫曼树及其应用
哈夫曼树及其应用 哈夫曼编译码 哈夫曼编码算法(难度超级大)
哈夫曼树及其应用 哈夫曼树
哈夫曼树又称最优二叉树,它是树的带权路径长度值最小的一棵二叉树,可用于构造最优编码,在信息传输,数据压缩等方面有着广泛的应用。
相关概念
路径:树中一个结点到另一个结点之间的分支序列。
路径长度:路径上分支的条数。
结点的权:给结点赋予的数值。
带权路径长度:结点的权值就是与该结点到数根间路径长度的乘积。
树的带权路径长度:树中所有叶子结点的带权路径长度之和,计为:WPL
最优二叉树:在叶子个数n以及各叶子权值Wi确定的条件下,树的带权路径长度WPL值最小的二叉树称为最优二叉树。
(哈夫曼依据最优二叉树的特点:权值越大,离根越近!给出了构造方法,因此最优二叉树又称哈夫曼树。)
哈夫曼树的建立 初始化:按给定的n个权值{w1,w2,…wn},构造n棵二叉树的集合F={T1,T2,…Tn},其每棵二叉树只含一个权值为wi的根结点,左右子树为空树。在F中选取根结点权值最小的两棵二叉树,分别作为左右子树构造一颗新的二叉树,并置新二叉树根结点的权值为其左右子树根结点的权值之和。从F中删除选中的两颗树,并插入刚生成的新树。重复2,3两步,直至F中只含一棵树为止。 哈夫曼算法的实现
对于给定的N个叶子节点,构造哈夫曼树,其最终总的结点数一定是:2N-1。
可选用静态链表作为存储结构。即用哈2N-1个元素的数组来存储哈夫曼树,结点间的父子关系用下标来指示。
在使用哈夫曼树进行编码和编译时,既要用结点的双亲信息,有要用结点的孩子信息,所以采用静态三叉链表存储哈夫曼树。
#define N 20
#define M 2*N-1typedef struct
{int weight;int parent;int LChild;int RChild;
}HTNode,HuffmanTree[M+1];
哈夫曼算法:
void CrtHuffmanTree(HuffmanTree ht,int w[],int n){for(i=1;i<=n;i++) ht[i]={w[i],0,0,0};m = 2*n-1;for(i=n+1;i<=m;i++) ht[i]={0,0,0,0};for(i=n+1;i<m;i++){select(ht,i-1,&s1,&s2);ht[i].weight=ht[s1].weight+ht[s2].weight;ht[i].LChild=s1; ht[i].RChild=s2;ht[s1].parent=i; ht[s2].parent=i;}
}
哈夫曼编译码
在信息传输等实际应用中,需将文本中出现的字符进行二进制编码,传输过后,又要将二进制码翻译为原先的字符,这就是典型的编码与译码问题。
在编码的设计中,通常遵守两个原则:
(1)编码能够唯一地被译码。
(2)编码长度要尽可能的短。
利用哈夫曼树可以得到平均长度最短的编码,因此,在信息传输、数据压缩等方面,哈夫曼树有着广泛的应用。
相关概念 等长编码:每个字符的编码长度相同。不等长编码:使用频率高的字符编码短,使用频率低的字符编码长。
平均长度最短的编码一般为不等长编码。
前缀编码:任何一个字符的编码都不是同一字符集中另一字符编码的前缀。 哈夫曼树设计编码
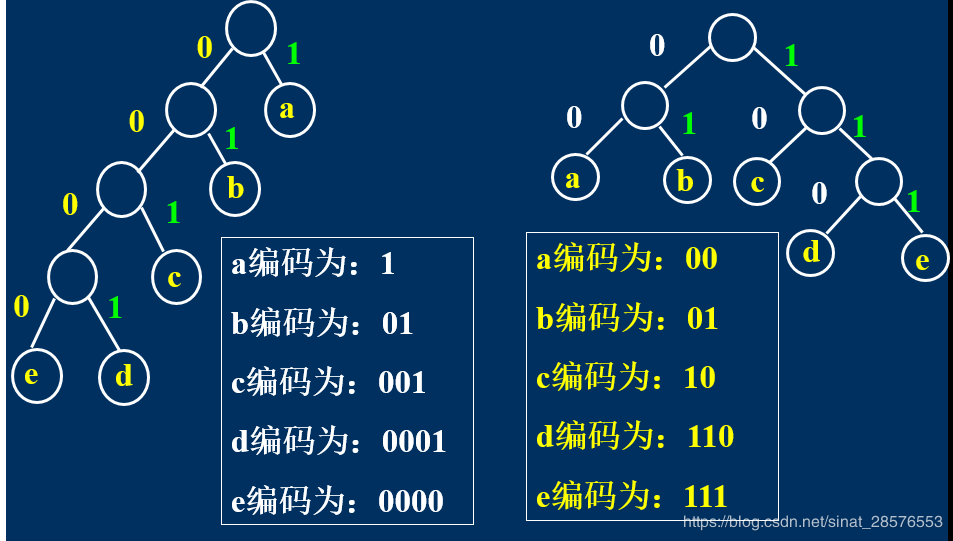
哈夫曼树是树的带权路径长度值为最小的二叉树,其特点就是:
叶子结点权值越大,离根越近!
而构造不等长编码的原则是:字符使用频率越高,编码越短!
所以用哈夫曼树设计编码的设想是:
每个待编码的字符对应一个叶子结点;
每个字符的使用频率对应叶子的权值;
每个字符的编码对应根到叶子的路径。
构造哈夫曼编码:
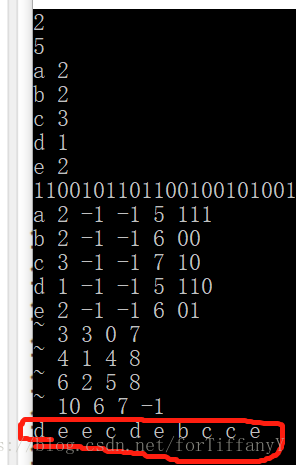
对树的每条分支做标记:左分支标0,右分支标1
根到叶子结点路径所对应的0,1序列构成该叶子结点对应字符的编码。
结论1:哈夫曼编码是前缀编码。
字符不同对应的叶子不同,从根到不同叶子的路径最后一定分叉,故根到一个叶子的路径不可能是另一个叶子路径的前段。
结论2:哈夫曼编码是最优前缀编码。
哈夫曼编码的构造
哈夫曼树存储于静态三叉链表中,在此前提下,由哈夫曼树构造哈夫曼编码,需要从叶子出发,从下向上走一遍从叶子到根的路径,每经过一条路径上的分支,就得到一位哈夫曼编码值,每个叶子的编码应该是由后向前逐位生成的。
结点为双亲的左孩子,当前编码位为0,否则为1。
由叶子走到根,就逆向完成了叶子结点编码的构造。
哈夫曼编码的译码
与构造编码的过程相反, 根据哈夫曼树进行译码时, 需要走一条从根结点到叶子结点的路径,
当前编码位为0时,走向左子树,
当前编码位为1时,走向右子树,
当走到叶子结点时,完成一个字符的译码。
哈夫曼编码算法(难度超级大)
算法中,生成的编码暂存在字符串cd中,一个叶子结点的编码构造完成,再转存到最终的字符数组中。
//存储定义
typedef char* Huffmancode[n+1];
char* cd;
int start;
//hc为Huffmancode指针数组
哈夫曼编码算法(考试不考)
CrtHuffmanCode(HuffmanTree ht,Huffmancode hc,int n)
{cd = (char*)malloc(n*sizeof(char));cd[n-1]='\0';for(i=1;i<=n;i++){start = n-1; c=i; p=ht[c].parent;while(p!=0){if(ht[p].Lchild==c) cd[--start]='0';else cd[--start]='1';c = p;p = ht[c].parent; }hc[i]=(char*)malloc(n-start)*sizeof(char));strcpy(hc[i],&cd[start]);}free(cd);
}