php电影爬虫,CrawlerMovies
具体的电影详情页面例子
最新电影的列表页面例子
二、功能
1. 获取单个电影详情
在浏览器上运行index.html,然后输入框输入某个具体的电影天堂的电影页面即可输出
如图:
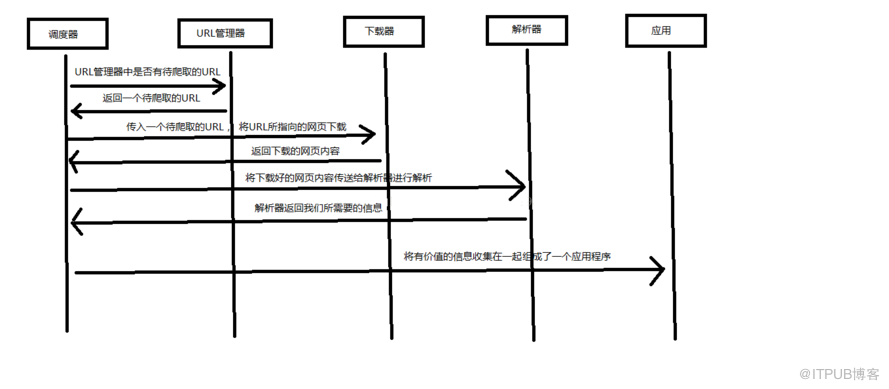
2. 批量获取所有的电影
分析
后来发现走不通,因为里面多了一个日期参数,即日期参数也是动态的,所以得改变思路,从列表页面url入手,获取所有的列表url,然后遍历列表url,获取当前列表页面的所有电影,即可获取所有的电影链接,然后对每个链接进行获取电影信息并且保存到数据库
第一步:获取所有列表页的url
列表页的url里面只有一个动态参数,比如: ,只有最后的15是动态的,所以只要获取最后的列表页的id,然后就可以生成所有的列表url
第二步:获取所有的电影url
这一步也是比较简单,列表页里面的电影url的形式是比较固定的,通过正则匹配就可以获取到当前页的所有电影url,需要注意的是,获取的电影url是相对地址,需要加上域名使之成为绝对地址
第三步:获取电影信息
这一步虽然不难,但是获取的电影信息元素比较多,而且是使用正则来匹配关键字的,有一些页面的关键字有所变更会导致抓取不到某些元素
另外,这一步需要注意的地方比较多
页面的编码问题,由于页面的格式的,所以需要转换为UTF8
中文空格问题,页面大量使用了中文空格,即全角空格,最好是先进行替换再正则匹配
404页面,有一些电影url是不存在的,需要剔除掉404页面,这一步可以通过判断响应头的- 的值,是否是 即可
第四步:保存到数据库
这一步我是使用Medoo这个ORM来进行数据库的CURD操作的,避免了原生的SQL操作
插入到数据库前,需要先判断数据库中是否存在该条电影记录,不然的话,多线程操作可能多导致重复插入的问题
前提
需要先创建好数据库和数据表,数据表的创建可以使用movie.sql来创建,并且把数据库配置到.php中
用法
在命令行中运行main.php即可,可以带列表页面url参数,比如:php main.php -url url,可能需要等待一段时间,成功之后会保存到数据库中
注意:这个命令行所需要输入的url,是任意一个列表页面的url
注意:由于我是采用正则来抓取电影天堂的电影详情页面的电影信息的,而且页面里面的有关电影信息都没有使用ID以及name这些属性,导致只能通过上下文的关键字来抓取,故会存在少部分页面关键字不一样导致抓取不到某些电影信息的
三、TODO
1. 多线程/多进程
由于目前并没有使用多线程/多进程,并且获取电影的数量又比较大,所以执行下来需要等待较长时间,后续会改成使用多线程/多进程来加快速度
更新:
多线程/多进程的话可以考虑使用/这个扩展来实现,但是呢,需要考虑的问题是,由于批量获取电影信息的步骤有4步,前两步的话用多线程/多进程的话需要考虑到同步的问题,另外前两步并不会消耗太大的时间,所以可以不对前两步进行多线程/多进程,主要是后面的第三步和第四步,而且这两步不需要考虑同步的问题,因为写入到数据库的时候会进行数据库是否存在该条电影的判断,这就需要将前两步和后两步进行分离,目前想到的方法是,将前两步生成的所有的电影url,都存放到文件中,然后单独执行第三步和第四步,即读取文件来进行后面的操作
2. 存储
可以配置存储为文件比如说cvs等格式
3. 事务(已完成)
一旦有了报错可以回滚
4. 命名空间
使用命名空间
5. 爬虫框架
如果都完成的话,可以使用爬虫框架比如来实现爬虫功能,很方便的实现了读写数据库、网络请求、html选择器、多线程等