通过递归的矩阵向量空间预测组合语义
-
摘要
单字矢量空间模型已经在学习词汇信息方面非常成功。但是,它们无法捕捉到更长的短语的位置意义,这样就阻碍了它们对语言的深入理解。我们介绍一种递归神经网络(RNN)模型,该模型学习任意句法类型和长度的短语和句子的组合向量表示。我们的模型为解析树中的每个节点分配向量和矩阵:向量捕获组成部分的固有含义,而矩阵捕获它如何改变相邻单词或短语的含义。这种矩阵向量RNN可以学习命题逻辑的运算符和自然语言的含义。该模型在三个不同的实验中获得最显著的表现:预测副词形容词对的细粒度情感分布;对电影评论的情感标签进行分类,并使用他们之间的句法路径对名词之间的因果关系或主题信息进行分类。
简介
语义词向量空间是许多有用的自然语言应用的核心,例如搜索查询扩展(Jones et al。2006),信息检索的事实提取(Pas¸caet al。2006)和消歧的文本自动注释带有的维基百科链接( et al。2011)等等(和。2010)。在这些模型中,单词的含义被编码为从单词及其相邻单词的共现统计中计算出的向量。这些向量已经表明它们与人类对词相似性的判断有很好的相关性( et al。2007)。
方法
方法.png
二分法解析树
二分法解析树.png
The song was by as
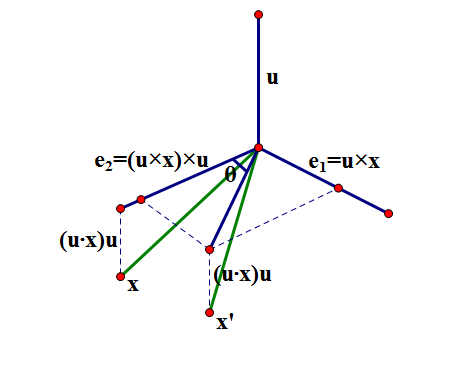
递归矩阵向量模型
递归矩阵向量模型.png
初始化 组合
组合.png
训练
我们通过在每个父节点顶部添加一个分类器来训练向量表示,以一种情感分类或一些关系分类
.png
其中W label∈R K×n是权重矩阵。如果有K个标签,则d∈RK是K维多项式分布
我们将t(x)∈RK×1表示为节点x处的目标分布向量,t(x)具有0-1编码:t(x)处的条目为1,其余条目为0.后计算d(x)和t(x)之间的交叉熵误差。
交叉熵.png
并将目标函数定义为所有训练数据上的E(x)之和:
QQ截图229.png
其中θ=(W,W M,W label,L,L M)是我们应该学习的模型参数的集合。 λ是正则化参数的向量.L和L M分别是字矢量和字矩阵的集合。
语义关系分类
语义关系分类.png
结果
我们对以下数据集进行了实验:
与其他办法的对比
对比.png
结果的改善也是由于其他方法的一些常见缺点。 例如:
•许多方法用无序的单词列表来表示文本,而情绪不仅取决于单词的含义,而且还取决于它们的顺序。
•使用的功能是手动开发的,不一定会捕获该单词的所有功能。
结论