python获取登录后的cookie_Python爬虫教程-12
爬虫教程-12-爬虫使用(上)
爬虫关于和,由于http协议无记忆性,比如说登录淘宝网站的浏览记录,下次打开是不能直接记忆下来的,后来就有了和机制
爬虫爬取登录后的页面
所以怎样让爬虫使用验证用户身份信息的呢,换句话说,怎样在使用爬虫的时候爬取已经登录的页面呢,这就是本篇的重点
和介绍
是发给用户的(即http浏览器)的一段信息
是保存在服务器上的对应的另一半信息,用来记录记录用户信息
和区别和联系:
1.存放位置不同:保存在本地,保存在服务器
2.不安全
为什么不安全,因为是保存在本地的,也就是说用户可以就本地找到后进行修改
所以一般用来存放用户身份信息,常用来识别用户身份,比如用户名+登录密码(站点也就不怕被修改了)
当我们关闭浏览器后,再次打开一些网站,不用再次登录,也正是因为使用了保存在本地浏览器的
3.会保存在服务器上有过期时间,也有
4.单个保存数据不超过4k,部分浏览器会限制一个站点最多保存20个
5.保存在服务器
一般情况下,是放在内存中或者数据库中
使用登录的网站
例如人人网:
第一步:打开登录
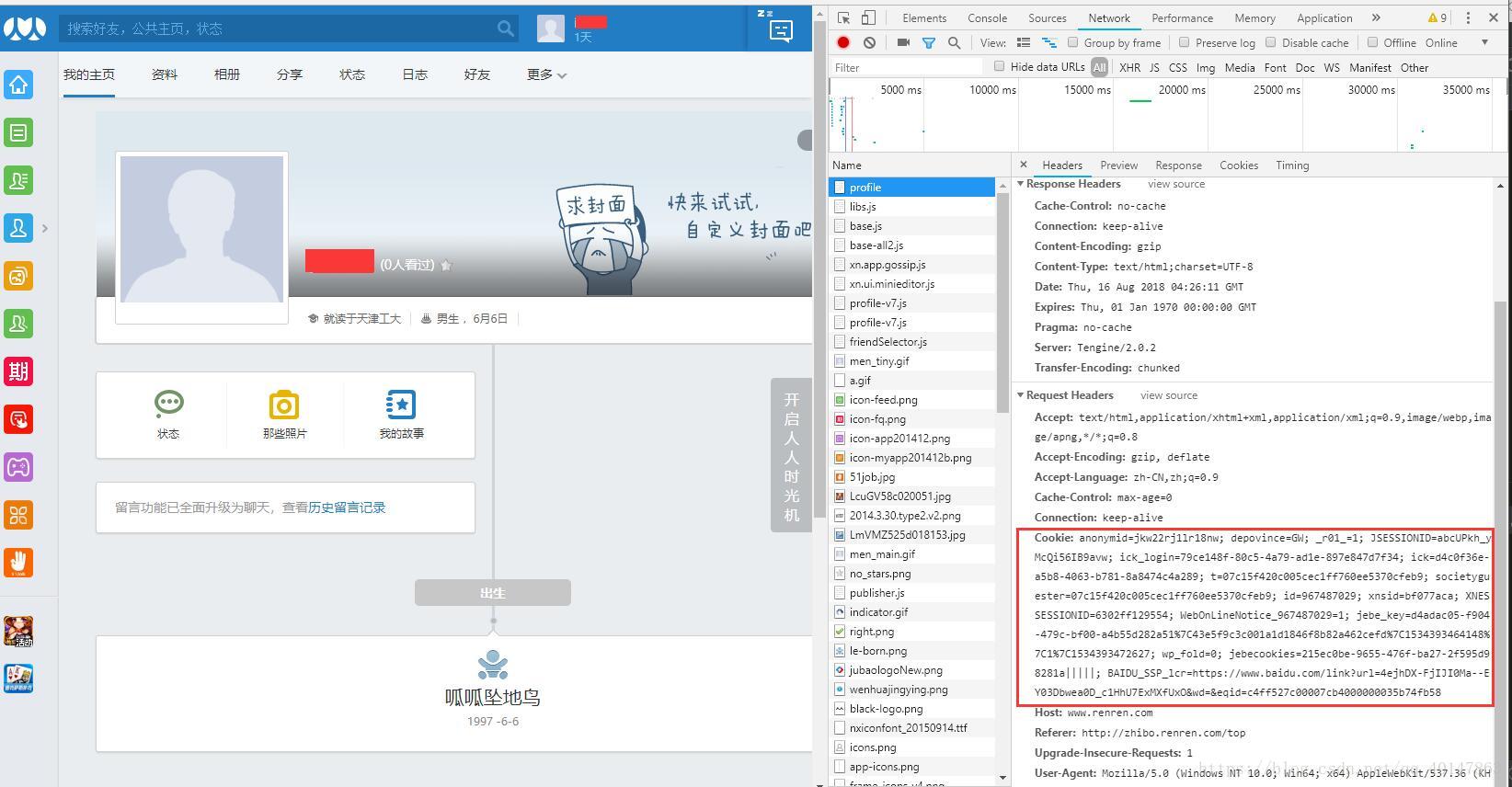
第二步:拷贝登录后的地址,使用火狐浏览器打开
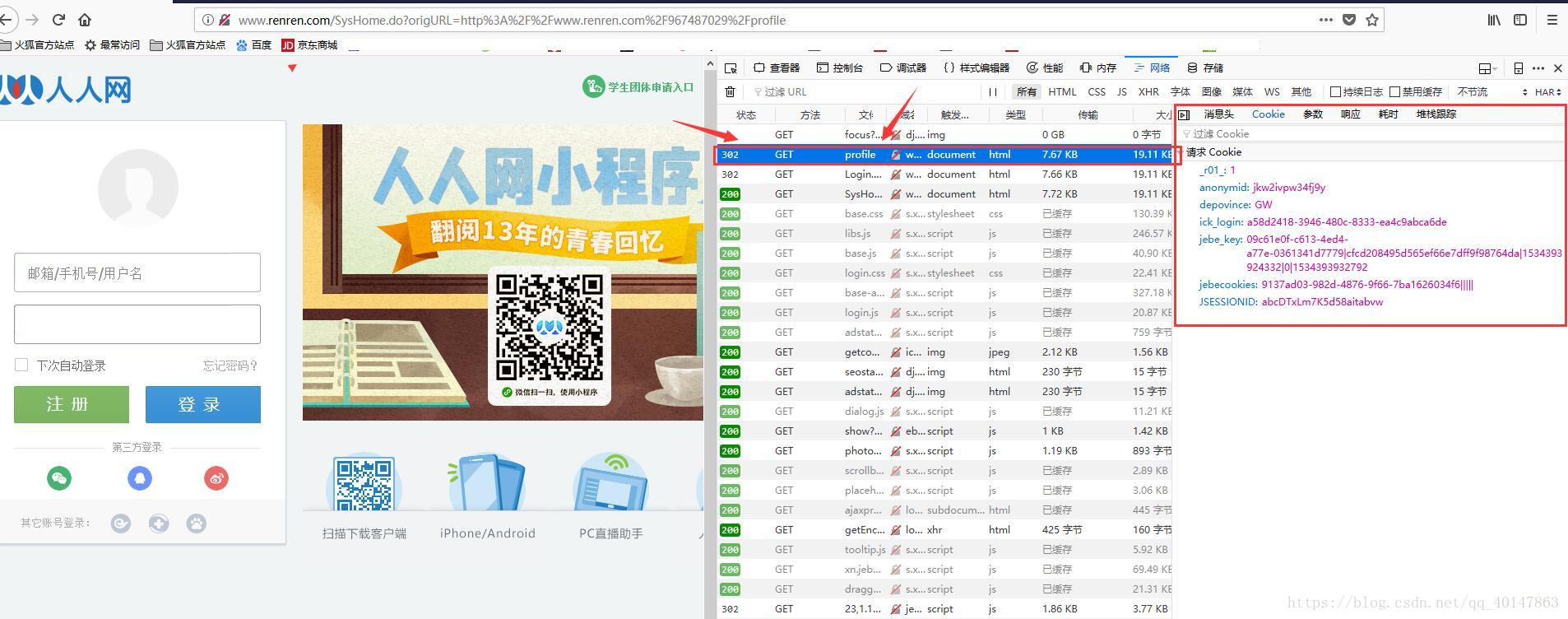
这可以看到报错302
原因就是火狐浏览器的和保存的不一样,站点判断用户身份改变,所以不允许登录,另一方面,也就说明我们使用 验证身份是成功的
主角登场-爬虫使用
既然其他浏览器不能直接访问网站,我们的爬虫就更不能了,所以怎样让爬虫使用验证用户身份信息的呢?马上揭晓:
编写爬虫代码
# 爬虫使用
from
if == '':