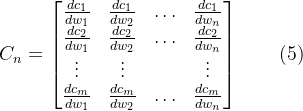自动驾驶的算力(TOPS)谎言
原文链接
当前,自动驾驶运算系统正在进入一场算力的竞赛中,特斯拉刚以自研的达到算力、业内最强的FSD/HW3.0升级HW2.5不久,英伟达最新推出的芯片系统达到了的惊人算力。然而,自动驾驶首要确保的安全性和算力并没有直接关系,即便1000E(T的百万倍)OPS也达不到L4级别,这只是硬件厂家的数字游戏而已,内行人从不当真。
这些所谓高算力实际针对乘积累加运算的高算力。乘积累加运算(英语:, MAC)。这种运算的操作,是将乘法的乘积结果和累加器 A 的值相加,再存入累加器:
若没有使用 MAC 指令,上述的程序需要二个指令,但 MAC 指令可以使用一个指令完成。而许多运算(例如卷积运算、点积运算、矩阵运算、数字滤波器运算、乃至多项式的求值运算,基本上全部的深度学习类型都可以对应)都可以分解为数个 MAC 指令,因此可以提高上述运算的效率。
之所以说自动驾驶的安全性和TOPS算力并没有直接关系基于三点。
一、这些所谓的高算力实际都只是乘积累加矩阵运算算力,只是对应深度学习算法的,只对应向量。深度学习是一种非确定性算法,而车辆安全需要确定性算法来保障。人工智能只是锦上添花,最终还是需要确定性算法把守安全底线。而确定性算法不靠乘积累加运算算力,它通常是标量运算,也就是更多依赖CPU的运算,那些所谓的高TOPS算力毫无意义。
二、深度学习视觉感知中目标分类与探测()是一体的,无法分割。也就是说,如果无法将目标分类(,也可以通俗地说是识别)就无法探测。换句话说,如果无法识别目标就认为目标不存在。车辆会认为前方无障碍物,会不减速直接撞上去。训练数据集无法完全覆盖真实世界的全部目标,能覆盖50%都已经是很神奇的了,更何况真实世界每时每刻都在产生着新的不规则目标。特斯拉多次事故都是如此,比如在中国两次在高速公路上追尾扫地车(第一次致人死亡),在美国多次追尾消防车。还有无法识别车辆侧面(大部分数据集都只采集车辆尾部图像没有车辆侧面图像)以及无法识别比较小的目标。TOPS算力高只是缩短能识别目标的识别时间,如果无法识别,还是毫无价值。
三,高TOPS都是运算单元(PE)的理论值,而非整个硬件系统的真实值。真实值更多取决于内部的SRAM、外部DRAM、指令集和模型优化程度。最糟糕的情况下,真实值是理论值的1/10算力甚至更低。
深度学习的不确定性
深度学习分为训练和推理两部分,训练就好比我们在学校的学习,但神经网络的训练和我们人类接受教育的过程之间存在相当大的不同。神经网络对我们人脑的生物学——神经元之间的所有互连——只有一点点拙劣的模仿。我们的大脑中的神经元可以连接到特定物理距离内任何其它神经元,而深度学习却不是这样——它分为很多不同的层(layer)、连接()和数据传播(data )的方向,因为多层,又有众多连接,所以称其为神经网络。
训练神经网络的时候,训练数据被输入到网络的第一层。然后所有的神经元,都会根据任务执行的情况,根据其正确或者错误的程度如何,分配一个权重参数(权重值)。在一个用于图像识别的网络中,第一层可能是用来寻找图像的边。第二层可能是寻找这些边所构成的形状——矩形或圆形。第三层可能是寻找特定的特征——比如闪亮的眼睛或按钮式的鼻子。每一层都会将图像传递给下一层,直到最后一层;最后的输出由该网络所产生的所有这些权重总体决定。
经过初步(是初步,这个是隐藏的)训练后得到全部权重模型后,我们就开始考试它,比如注入神经网络几万张含有猫的图片(每张图片都需要在猫的地方标注猫,这个过程一般是手工标注,也有自动标注,但准确度肯定不如手工),然后拿一张图片让神经网络识别图片里的是不是猫。如果答对了,这个正确会反向传播到该权重层,给予奖励就是保留,如果答错了,这个错误会回传到网络各层,让网络再猜一下,给出一个不同的论断这个错误会反向地传播通过该网络的层,该网络也必须做出其它猜测,网络并不知道自己错在哪里,也无需知道。在每一次尝试中,它都必须考虑其它属性——在我们的例子中是「猫」的属性——并为每一层所检查的属性赋予更高或更低的权重。然后它再次做出猜测,一次又一次,无数次尝试……直到其得到正确的权重配置,从而在几乎所有的考试中都能得到正确的答案。
得到正确的权重配置,这是一个巨大的数据库,显然无法实际应用,特别是嵌入式应用,于是我们要对其修剪,让其瘦身。首先去掉神经网络中训练之后就不再激活的部件。这些部分已不再被需要,可以被「修剪」掉。其次是压缩,这和我们常用的图像和视频压缩类似,保留最重要的部分,如今模拟视频几乎不存在,都是压缩视频的天下,但我们并未感觉到压缩视频与原始视频有区别。
深度学习的关键理论是线性代数和概率论,因为深度学习的根本思想就是把任何事物转化成高维空间的向量,强大无比的神经网络,说来就是无数的矩阵运算和简单的非线性变换的结合。在19世纪中期,矩阵理论就已经成熟。概率论在18世纪中期就有贝叶斯,在1900年俄罗斯的马尔科夫发表概率演算,概率论完全成熟。优化理论主要来自微积分,包括拉格朗日乘子法及其延伸的KKT,而拉格朗日是18世纪中叶的法国数学家。RNN则和非线性动力学关联甚密,其基础在20世纪初已经完备。至于GAN网络,则离不开19世纪末伟大的奥地利物理学家波尔兹曼。强化学习的理论基础是1906年俄罗斯数学家马尔科夫发表的弱大数定律(weak law of large )和中心极限定理( limit ),也就是马尔科夫链。
可以说深度学习所需要的理论基础在100年前已经基本齐全(概率和信息论略微不足,在20世纪60年代补齐),现在的深度学习只是从理论走向实用,这当中最关键的推手就是GPU的高TOPS算力,是英伟达的GPU造就了深度学习时代的到来,深度学习没有理论上的突破,只是应用上的扩展。经过压缩后,多个神经网络层被合为一个单一的计算。最后得到的这个就是推理用模型或者说算法模型。
实际深度学习就是靠蛮力计算(当然也有1X1卷积、池化等操作降低参数量和维度)代替了精妙的科学。深度学习没有数学算法那般有智慧,它知其然,不知其所以然,它只是概率预测,它无法具备确定性。所以在目前的深度学习方法中,参数的调节方法依然是一门“艺术”,而非“科学”。深度学习方法深刻地转变了人类几乎所有学科的研究方法。以前学者们所采用的观察现象,提炼规律,数学建模,模拟解析,实验检验,修正模型的研究套路被彻底颠覆,被数据科学的方法所取代:收集数据,训练网络,实验检验,加强训练。这也使得算力需求越来越高。机械定理证明验证了命题的真伪,但是无法明确地提出新的概念和方法,实质上背离了数学的真正目的。这是一种“相关性”而非“因果性”的科学。历史上,人类积累科学知识,在初期总是得到“经验公式”,但是最终还是寻求更为深刻本质的理解。例如从炼丹术到化学、量子力学的发展历程。
深度学习的理论基础已经不可能出现大的突破,因为目前人类的数学特别是非确定性数学已经走火入魔了,有一本书叫《数学:确定性的丧失》说得非常好。
书中的一个比喻:在莱茵河畔,一座美丽的城堡(暗指德国哥廷根大学,曾经在200年里是全球数学研究中心,数学的圣地,非线性动力学圣地。希特勒执政后全球数学圣地转移至美国的普林斯顿大学)已经矗立了许多个世纪。在城堡的地下室中生活着一群蜘蛛,突然一阵大风吹散了它们辛辛苦苦编织的一张繁复的蛛网,于是它们慌乱地加以修补,因为它们认为,正是蛛网支撑着整个城堡。小至四元数、负数、复数、矩阵,大至微积分、非欧几何,经验算术及其延展代数背后隐藏着深深困扰数学家的逻辑问题。然而,数学家们是在贡献概念而不是从现实世界中抽象出思想,这些概念却被证明越来越实用,数学家们变得越来越肆无忌惮。通过应用经验来修正理论逻辑,数学逐步失去了其先验性,变得越来越像哲学甚至玄学。
宝马L3/L4智能驾驶软件架构
宝马L3/L4主系统计算路径,系统监督主系统,当得知主系统计算的路径会发生事故或碰撞时,系统会切换为主系统,主系统使用人工智能的非确定性算法,系统使用经典的确定性算法来保证安全。
真假TOPS
推理领域,算力理论值取决于运算精度、MAC的数量和运行频率。大概可以简化为这样子,INT8精度下的MAC数量在FP16精度下等于减少了一半。FP32再减少一半,依次类推。其计算相当简单,假设有512个MAC运算单元,运行频率为1GHz,INT8的数据结构和精度(自动驾驶推理领域常见精度),算力为512 x 2 x 1 = 1000 / = 1 TOPS(Tera-/)。如果是FP16精度那么就是0.5TOPS。例如英伟达的Tesla V100有640个核,每核有64个MAC运算单元,运行频率大约1.,那么INT8下算力为640*64*2*1.=。但是Tesla V100的训练就使用CUDA核,有5120个CUDA核,双精度(FP64)下算力是另一种算法了。这个月刚发布的A100,有432个三代核,每个核包含512个MAC运算单元(等同于64个双精度MAC),运行频率为1.,INT8下算力为432*512*2*1.=。特斯拉的FSD是9216个MAC运算单元,运行频率是2GHz,INT8算力为9216*2*2GHz=36.。
真实值和理论值差异极大。决定算力真实值最主要因素是内存( SRAM和DRAM)带宽,还有实际运行频率(即供电电压或温度),还有算法的batch尺寸。例如谷歌第一代TPU,理论值为算力,最差真实值只有1/9,也就是算力,因为第一代内存带宽仅34GB/s。而第二代TPU下血本使用了HBM内存,带宽提升到600GB/s(单一芯片,TPU V2板内存总带宽/s)。最新的英伟达的A100使用40GB的2代HBM,带宽提升到/s,比V100提升大约73%。特斯拉是128 -4266 ,那么内存的带宽就是:*2DDR*/8/1000=68.256GB/s。比第一代TPU略好(这些都是理论上的最大峰值带宽)其性能最差真实值估计是2/9。也就是大约8TOPS。16GB版本的内存峰值带宽是137GB/s。
为什么会这样?这就牵涉到MAC计算效率问题。如果你的算法或者说CNN卷积需要的算力是1TOPS,而运算平台的算力是4TOPS,那么利用效率只有25%,运算单元大部分时候都在等待数据传送,特别是batch尺寸较小时候,这时候存储带宽不足会严重限制性能。但如果超出平台的运算能力,延迟会大幅度增加,存储瓶颈一样很要命。效率在90-95%情况下,存储瓶颈影响最小,但这并不意味着不影响了,影响依然存在。然而平台不会只运算一种算法,运算利用效率很难稳定在90-95%。这就是为何大部分人工智能算法公司都想定制或自制计算平台的主要原因,计算平台厂家也需要推出与之配套的算法,软硬一体,实难分开。
比如业内大名鼎鼎的-50,其需要MAC大约为每秒70亿次运算,英伟达运行-50每秒可处理3920张224*224的图像,3920 / x 7 /image = 27,440 / = 27.4 / = 27.4 TOPS。而英伟达Tesla T4的理论算力是。实际只有27.4TOPS。
也有些软件改善内存瓶颈的方法,比如修改指令集,让权重值快速加载,提高数据复用率,减少频繁读取,例如华为曾经用过的寒武纪的IP。但最简单有效的解决方法还是提高内存带宽。
提高内存带宽有三种方法,一是缩短运算单元与存储器之间的物理距离,二是使用高带宽内存即HBM,三加大内存容量。注意上文所说的内存带宽都是理论上的带宽,实际带宽跟物理距离关系极为密切,物理距离远会让内存实际带宽下降不少,但具体数值还未有详细资料。
第一种方法最有效。物理距离最近的自然把存储器与运算单元制作在一个die里(一一级缓存和二级缓存),线宽可能只有1-2微米,但是存储器所占晶圆面积很大,工艺与运算单元也有比较大的差异,这样做会大幅度提高成本,因此大部分厂家的in-die内存容量都很小。退一步,把存储器与运算单元制作在一个里,目前台积电的CoWos工艺大约可以做到55微米( Micro-bump)。这是目前所有主流厂家的选择,毕竟计算是针对数据中心的芯片也要优先考虑价格。最差的就是特斯拉和谷歌第一代TPU使用PCB板上的内存( BGA),这样线宽大约1100-1500微米。缩短距离不仅能提高存储带宽,同时还能降低内存功耗。
HBM最早由AMD和SK Hynix提出,但是三星几乎垄断HBM市场,目前已经发展到HBM2代,HBM2可以做到最高12颗TSV堆叠3.6TB/s的带宽,传统DRAM最顶级的GDDR6是768GB/s。HBM的缺点是太贵,针对消费类市场的产品没人敢用,也缺乏应用场景,只有数据中心才用。除此之外还有一个缺点,用HBM就意味着必须用台积电的CoWos工艺,这样才能尽量缩短与运算单元的物理距离,最大限度发挥HBM的性能。英特尔的EMIB工艺可以抗衡台积电的CoWos工艺,但英特尔不做代工。因此全球高性能AI芯片无一例外都在台积电生产,市场占有率100%。
再来说运行频率。在设计集成电路时,仿真或EDA会给出常见的三种状态分析。
WCS (Worst Case Slow) : slow , high ,
TYP () : , ,
BCF (Best Case Fast ) : fast , ,
假设一个AI芯片,运行频率2GHz,一般温度25°,电压0.8V,算力为2TOPS。在WCS下,温度为125度,电压0.72V,此时频率会降低到1GHz,算力就会降为1TOPS。
那么每瓦TOPS有没意义呢?抱歉,也没多大意义的。首先是因为算力值本身就有很多种可能,厂家肯定只选数值最大的那个给你看。其次这只是运算单元芯片本身的功耗与算力比,没有考虑DRAM。在深度学习计算中,数据频繁存取,极端情况下,功耗可能不低于运算单元。
结论
不必纠结于数字游戏,深度学习只是锦上添花,确定性算法把守安全底线才是最重要的。当然业界风气使然,数字游戏还会继续,还会更加热闹,但业内人士都心知肚明,完全无人驾驶落地还是遥遥无期。