MapReduce和并行数据库,朋友还是敌人?
文/何伟平
在2010年1月的ACM上,有两篇文章非常吸引人注意。一篇文章是的、发表的标题为《:一个灵活的数据库处理工具》,另一篇文章是、、.、、、、、Rasin等人发表的《和并行数据库:是朋友还是敌人?》。这两篇文章让我想起去年初等人就发表的一些评论而导致了一次和数据库系统的大辩论。那篇文章的标题是《:一个巨大的倒退》。这次辩论双方则准备了丰富的实践和实验案例。看上去更加有趣也更加有说服力。
以下“正方”代表坚持并行数据库解决方案的、等,而反方则是的(下文简称MR)的拥趸、等。
正方抛出观点
2009年等人发表了一篇标题为《大规模数据分析的方法对比》()的文章,里面对比了数据库和MR两种大规模数据分析方法的对比。通过对比流行的MR软件和一种并行数据库之间的架设、使用和性能等方面的异同,指出MR并不是解决大规模数据分析的好方法,其在性能、易用性等方面有诸多问题:
一、MR没法用索引,总是对数据进行完全扫描;
二、MR输入和输出,总是文件系统中的简单文件;
三、MR需要使用不高效的文本数据格式。
反方接招
对于正方第一个观点,反方如此应对:“错了!MR的输入本身可以是数据库的输出,所以,我们是可以用索引的。另外一个例子是MR从里面读取数据,如果数据落在一个行范畴里面,当然是可以用索引的。而且,在很多需要处理的数据里头,比如的日志,经过轮转之后天然就有索引(文件名包含时间戳)。”
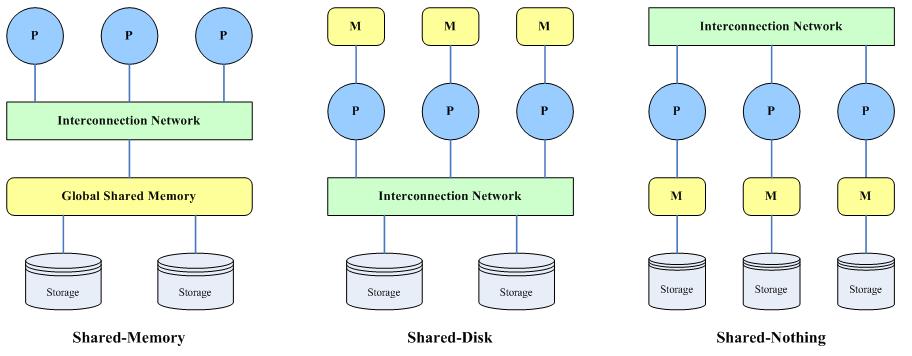
对于第二个观点,反方认为:“现存的很多MR系统,本身就是一个异构环境,用户的数据可能存储在关系数据库里头,而其处理结果可能会记录在文件系统里头。而且,这样的环境可能会进化,用户的数据会迁移到新的系统里。而MR可以非常便利地在这些环境上运行。更进一步,用户可以扩展这些存储,比如分布文件系统、数据库查询结果,存储在里面的数据,结构化的数据(B-tree文件等)。对于这些场合,单个MR处理就可以很容易地捏合它们。”
对于第三个观点,反方认为:“这点的确很精辟。很到位,不过这个因素是取决于具体的实现的,比如在的MR实现里,有个层,可以对输入的数据进行格式定义,因此就可以直接适用二进制类型,而不用有额外的格式转换的开销,在我们的测试里,原来要花的一个格式分析,用预定义之后,只要20几ns。所以,如果实现得足够好,我们认为MR系统不会只能处理文本格式的数据,而是可以处理二进制数据,因此效率还可以极大提升。”除了这些之外,反方还抛出了几块大砖头,等着正方接招:
MR与存储系统无关,而且可以不用把数据装载到数据库就直接处理之,在很多场合下,在数据库系统把数据装载到数据库里头并且完成一次分析所花的时间,用MR的方式都能完成50次分析运算了。
用MR可以表现更复杂的数据变换规则,很多反方的意见都是实现相关的,是针对一些不好的MR的实现做出来的,因此站不住脚。
反方的最有力的证据就是,在里头跑得很好的一万多各种MR应用,从网页分析到索引建立,从日志分析到网图计算等等。
正方的回应
作为正方,教授等人在同一期杂志上发表了另外一篇文章,很有趣的是刚好排在反方的文章之前。这篇文章以批评与自我批评的方式提出了若干有趣的观点,其中有些刚好是对反方的一个回应:
MR系统可以用于(注意:不是胜出)下列场合:
正方认为,把适合于数据库的工作交给MR去做结果其实并不好。在正方的试验里,证实了MR更加适用于做数据转换和装载的(ETL)工作,在这些场合,MR可以成为并行数据库的良好补充,而不是替代品。为了证明上述论点,正方做了一些有趣的试验,试验对比的双方是并行数据库集群和集群,试验的主要内容有:
针对上面的结果,正方做了一些分析,认为这些差距的来源主要来自于具体实现,而非并行数据库模型和MR模型之间的差异。比如,MR可以使用并行数据库为低层的存储,所以所有分析都针对现实中两种模式的具体实现。正方分析了导致差距的几个实现相关的架构原因:
正方经过试验得出的结论是:MR和并行数据库结合是最好的方案,MR负责数据装载、转换等工作,并行数据库负责查询密集型的任务。正方最后发出的振聋发聩的呼吁是:很多事情并行数据库系统已经做得很好了,我们为什么不站在这个巨人的肩膀上?
作者结语
对于商业社会,这种争论的背后往往带着巨大的经济利益:MR和并行数据库在一定程度上重叠的使用范畴会导致不小的市场冲突,而在这种潜在冲突的情况下,把握好理论制高点是很重要的一个指导措施。
而对于学术界,避免重新发明轮子以及因为片面的适用范畴导致的学术资源不合理配置,相信也是各位大大争论的缘由。这个争论让人想起十几年前老头和之间在上的争论。十多年后来看那场辩论,站住了学术和技术方向的脚跟,而Linus成就了项目的辉煌。没有对错,留给我们的是极为丰富的经验,Linus站在了肩膀上,而我们站在了Linus的肩膀上。可能看完这篇对比之后,大多数同学的反应都会是:该干吗干吗,在哪好使就使啥。绝对没错,不过,我们也要从历史中学会更多经验啊!可别因为手里攥着锤子,就满世界都是钉子。虽说各有各的好处和适用范围,可事实呢?人们还是经常会因为某些新发现而被头脑发热冲击得失去了判断力:满世界都是钉子!可不是吗?想想这些年流行的种种,人们总是易于认为一个新技术可以搞定天下所有问题。
做为一个数据库用户,我多少倾向数据库大大们的意见。结合自己的实际,在很多场合下,自己会利用系统工具,如Awk、Perl等做数据并行装载的事情,不知不觉用了MR的概念,很自然也很方便。而真正的数据查询,还是喜欢高级而简单的SQL,让我去写一堆Map/过程而放弃手边的SQL工具,感觉很痛苦。感觉自己还是应该把一个东西用到极致,结合新的工具来站的更高,而不是盲目放弃。所以尽管自己经常被冠以“手拿锤子,满世界都是钉子”的头衔,但实际工作中却发现很多同学却是在实际行动中打的是MR的旗号,行的是革数据库的命之行动,在重新发明轮子的道路上越行越远,却兴致勃勃。不能不令人扼腕。在这个大讨论里,正反双方最后几乎异口同声地说出了“实现相关”的结论,貌似这个争论已经可以画上句号了。几乎可以肯定的是,MR会以各种方式越来越像数据库系统,而数据库系统会以各种方式集成MR的优点,变成前置的ETL系统/或后置的数据再处理系统。不管怎样,争论中留下的一个个闪光的要点,相信会对我们了解事物,做出判断有着巨大的帮助。
作者简介:
何伟平,-SQL中文版文档维护者,《Perl编程》第三版译者,Linux集群管理员及数据库研究员和软件开发人员。有近十年的软件开发经验,在金融、工业和互联网等行业有着较长的经历。现供职于某互联网公司,从事大型集群管理以及技术指导方面的工作。
(本文来自《程序员》杂志10年06期)
《程序员》9月刊最新上市: