51信用卡金融风控场景下实时计算引擎的设计与实践(转)
个人博客:
51信用卡金融风控场景下实时计算引擎的设计与实践 1.业务背景与痛点
51信用卡是中国最大的线上信用卡管理平台, 业务涵盖个人负债管理、信用卡科技服务、线上信贷撮合及投资理财服务。目前在51人品贷借贷场景,用户需要先导入个人资料,主要包括信用卡账单、运营商、通讯录等数据,然后触发一系列风控模型计算,包括实时的授信出额、A卡信用评分准入(要求秒级完成),以及近线的反欺诈审核流程(要求30分钟内完成)。风控模型依托大量变量,这些变量从开发到上线在以前的研发流程如下:
这个过程中主要存在两个问题,严重影响了模型的交付速度与质量:
在2018年初为了上线一版全新的风控主模型,前后花了将近3个月时间,其中大部分时间耗在修复数据偏差上,开发同学苦不堪言,所以对于风控计算能力以及效率的提升,迫在眉睫。
2.技术目标与方案选型
2018下半年,CTO启动了"光锥"风控平台项目,旨在从根本上提升金融风控整体迭代效率(范围包括但不限于变量计算、策略模型部署、变量快速分析、策略仿真实验、变量/策略/模型监控等)。
光锥首先完成了在线/离线数据源的统一,对借贷用户下单时刻的主要风控数据源做关联快照,业务人员基于快照做离线挖掘,离线数据源标准向在线数据源看齐,保持一致。在变量计算方面,为了复用模型人员提供的,减少代码翻译,我们在反欺诈审核环节引入了基于的近线计算引擎(基本兼容),在单机Local模式下创建多个并行处理微批订单,与微服务无缝融合,基本上分钟级别可以完成任务。但是对于实时性要求较高的授信以及订单准入场景,Spark处理性能达不到要求,我们需要一个实时的高性能SQL计算引擎,而且最好能在一定程度上兼容。
在方案调研上,首先想到的是内存数据库如H2、 , 随便拿几个业务SQL做了测试,发现稍微复杂点有嵌套的SQL语句就解析失败,直接放弃。然后重点放在了目前火热的流计算框架上,、Flink。不管是Spark还是Flink,在对流计算的SQL支持上都比较弱(当时.4版本的 SQL连LEFT OUTER JOIN也不支持)。虽然我们已经在一些风控指标计算场景上线了和Flink任务,但是主要的风控变量计算任务并不是一个典型的场景,业务上用户可以先导入信用卡账单进行管理,等1个月后再来下单触发风控计算,如果实时拉取数据再加载到系统节点显得多余。另外在计算过程中通过外部接口获取数据后可以直接进行内存计算,并不需要中间存储,如果单机计算足够快,也不需要引入分布式计算,避免产生额外开销。
后来我们分别调研了Flink和 Beam在Batch模式下的单机本地SQL执行框架,Flink里是+t,Beam里是+,两者都能将Java集合数据直接映射为表,然后联合多表进行SQL查询。由于解析完SQL就生成执行代码直接运行,没有Job生成调度逻辑,也没有像Spark里的Stage划分,回收清理等操作,执行效率较高,在我们的真实业务数据集上性能表现非常不错。Flink和Beam都使用了热门的SQL引擎项目 进行SQL解析和逻辑计划生成,然后实现自己的物理计划以及生成执行代码运行(在分布式模式下,Beam会将计划适配代理给指定执行)。也被多个其他项目使用,其中Hive和阿里的单独使用来做基于代价的优化,Hive对的使用方式如下:
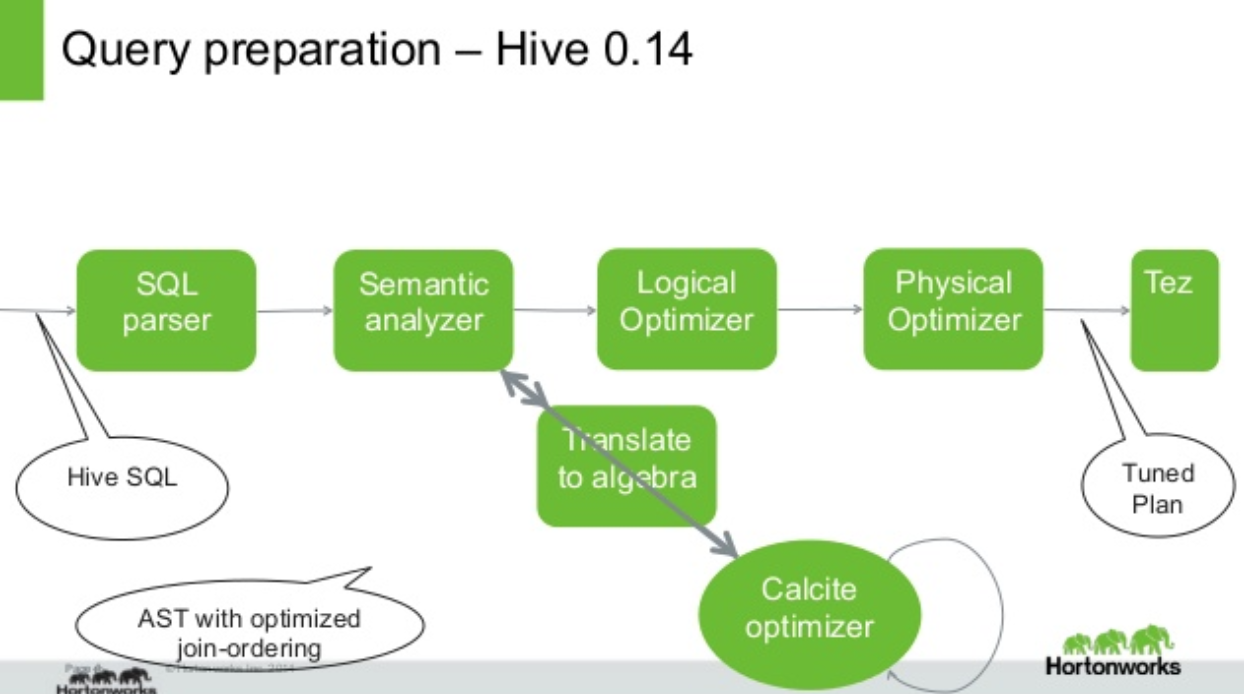
Hive通过Antlr解析SQL生成抽象语法树(),然后翻译成的逻辑计划(),基于代价优化完成等价转换,再翻译回Hive能处理的 。实际上的SQL语法并不兼容,在数据类型和操作符()支持上也有很大不同。但是在关系代数( )层面是相同的,所以可以完成上述转换。当然Hive也有Local运行模式,由于生成的执行计划面向MR任务,在低延时高性能计算场景,无法满足要求。
虽然并不兼容,但它对工业级的SQL高级特性有较好的支持(如复杂类型、窗口函数、表函数等OLAP特性),同时它默认内置了一套基于的本地SQL执行框架,用于执行代码生成和运行。我们的目标是计算引擎要在业务上兼容,不管是选择Flink还是Beam都需要对做二次改造和者扩展,考虑到本身的简洁设计以及较强的扩展性,我们决定直接基于二次开发,实现一套在业务上兼容的本地实时SQL计算引擎。
3.方案设计与实现
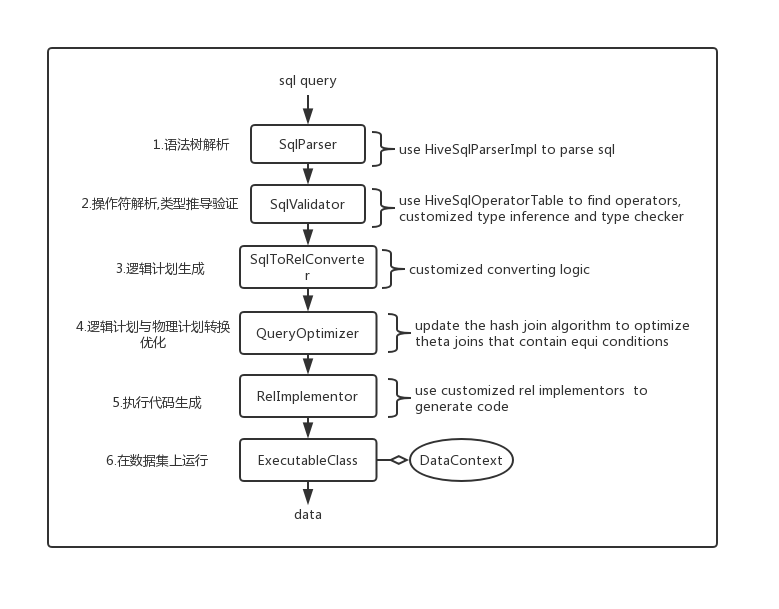
先简单介绍下的架构和SQL处理流程:
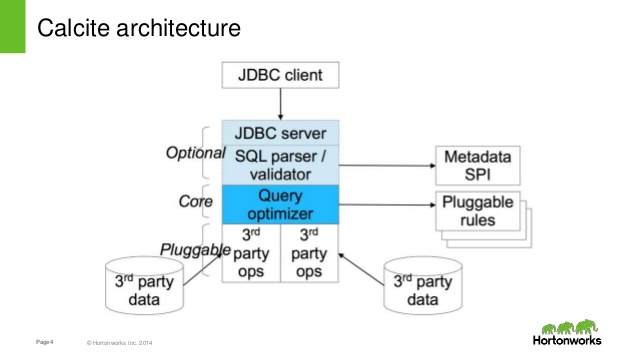
对于一次Sql查询,一般经过以下流程:
受益于的可插拔架构,大多数项目会使用先生成,然后添加一系列rules来完成第三方物理计划转换与执行代码生成。考虑到研发成本,我们希望尽可能重用默认的物理计划和执行代码生成逻辑。为了支持的语法和操作符,我们主要做了以下改造和扩展:
select * from t where c1 rlike '^\\d+$'
add_months(start_date,add_months)
可以是date类型,也可以是。
我们需要先将数据类型转换为Hive的数据类型,然后桥接Hive实现动态类型推导验证,再将Hive函数返回类型转换回类型。这部分类似 连接Hive的处理方式,主要数据类型的映射关系如下:
Long
Int
rs
r
DATE
Int
Long
ctor
ARRAY
List
…
…
…
对于复杂类型,目前我们只按需支持了Array;
select split('a,b,c',',')[0]
默认索引从[1]开始,而Hive是从[0]开始,我们为代码实现器的注册表添加了扩展机制,允许在初始化注册后为操作符覆盖或者添加新的实现器。对于UDF、UDAF、UDTF等分别实现了通用的代码实现器,可以生成相应的执行代码;
select t1.*,t2.* from t1 join t2 on t1.intVal=t2.stringVal
我们参考Hive规则对算法的Key进行了隐式转换。另外在强制转换的过程中遇到无法转换的情况,如cast(’’ as int) ,会报错,而Hive会转换成null;
在功能基本满足后,我们做了相应的对比测试,在性能优化上主要做了几点:
SELECT t1.*,t2.* FROM item1 t1 LEFT OUTER JOIN item2
t2 ON t1.i_item_sk=t2.i_item_sk and t1.i_item_sk <15000
由于包含了谓语条件t1. ,对这类Join采用(嵌套循环)算法实现,没有做优化。而Flink和Spark在后数据会自然排序好,所以采用了更高效的Sort-Merge-Join算法实现。在我们优化了相应的转换rule以及算法后,此类Join性能提升了几十倍(已提交patch给社区)。在真实的业务场景里,SQL往往较复杂,有多层嵌套,由于可以复用完整的执行实例,我们的计算性能表现比Flink的Local模式更优。
在SQL处理流程图里,我们的主要扩展点如下:
4.业务实践与平台化
使用方面,我们参考Flink实现了一套简洁的Table API:
TableEnv tableEnv = HiveTableEnv.getTableEnv();
DataTable t1 = tableEnv.fromJavaPojoList(pojoList);
DataTable t2 = tableEnv.fromJdbcResultSet(resultSet);
tableEnv.addSubSchema("test");
tableEnv.registerTable("test","t1",t1);
tableEnv.registerTable("test","t2", t2);
DataTable queryResult = tableEnv.sqlQuery("select * from test.t1 join test.t2 on t1.id=t2.id");
那么在真实的业务系统里,我们如何利用这个内存SQL计算引擎?
在金融风控场景,大多数用户的单数据域的数据量一般在千到万级,所以单条查询的性能基本在百毫秒级或者以内,但是有两类典型场景无法使用纯内存计算:
isHitBlackMobileList("t1",500)
在运行时会将t1临时表的数据传入函数,然后以500行每批并行调用外部接口,将匹配到的黑名单merge后返回成一个虚拟表,这样做的好处是,名单存储匹配可以由业务方灵活控制,背后可能采用HBase或者其他基于布隆过滤器的方案;
为了方便业务人员快速开发变量,我们沉淀了数据源管理和变量计算平台,提供了用于在线开发调试的SQL IDE, 业务人员能方便地自主部署自己的SQL任务,并基于历史数据完成数据校验比对。当SQL任务审批发布上线后,配套的变量监控任务也会启动,包括T+1的在线/离线一致性比对,PSI以及缺失率等指标监控。
在任务运行时,计算引擎会根据SQL提取表名,解析表与表的依赖形成执行DAG,对于一个SQL节点,只要上游依赖表的任务完成,就会被提交到线程池执行。
部署方面,在51信用卡,是通常的应用部署方式,对这类计算型应用,我们开启HPA功能进行自动伸缩容,并使用CPU 特性来保证性能优先的调度策略,这样可以避免因单个任务耗时而引发的排队等待。
经过一段时间试运行和验证,我们于2019年初在主业务的A卡全新模型上全面使用了自主研发的实时计算引擎,并逐步将其他模型的变量往新的计算平台迁移。在性能表现上,除开数据源拉取,完成一次订单请求的所有变量的计算平均耗时稳定在1s以内,而在线/离线数据的一致率达到99%以上。过去长达2个月的一版主模型的迭代周期,现在能缩短到2周以内,这从根本上提高了风控模型的迭代效率与质量。
5.项目开源
为了进一步丰富计算引擎的功能以及适用更多业务场景,我们决定将核心库开源,另外也提交了部分issue和patch给社区,有兴趣的同学可以关注。
作者介绍:
周来,负责51信用卡风控计算引擎以及风控数据智能分析产品等研发。