信用卡风控——梯度提升树方法Python实现
本文是一个用户按时还款的预测模型,利用台湾地区一些信用卡客户的信用额度、教育程度、婚姻状况、过去的还款状态、账单等信息对客户进行评分,采用GBDT(梯度提升树)模型对数据进行分类,预测其是否会产生逾期偿还,数据来源于的一个比赛,可在此处下载。
数据介绍
此数据集包含有关2005年4月至2005年9月台湾地区信用卡客户的缺失付款,人口统计因素,信用数据,付款历史和账单的信息。
有25个变量:
描述性统计
观察连续变量的大致分布和离散变量的统计值。
#描述性统计分析
data.info()
data.describe()
data['default.payment.next.month'].value_counts()
class_column = [ 'SEX', 'EDUCATION', 'MARRIAGE', 'PAY_0','PAY_2', 'PAY_3', 'PAY_4', 'PAY_5', 'PAY_6', 'default.payment.next.month'] #离散变量
for column in data.columns:plt.hist(data[column])plt.title(column)plt.show()if column in class_column:print('统计值:',data[column].value_counts())
变量很多,这里不一一列出,大家可以观察每个变量的分布情况进行分析,可以总结出有如下几个特点:
其中目标变量的分布如下:
特征意义数量
按时还款
23364
逾期还款
6636
两类变量并不均衡。
数据预处理
由于数据中没有缺失值,不需要进行缺失值处理。
下面进行特征筛选。
特征筛选的方法有很多,总体来说可以分为三类:过滤式、包裹式和嵌入式。本例中主要使用了基于IV值和基于皮尔森相关系数的特征筛选方法。
首先删除没有意义的ID变量值,再计算各个变量的皮尔森相关系数。
del data['ID'] #删除无意义的ID变量
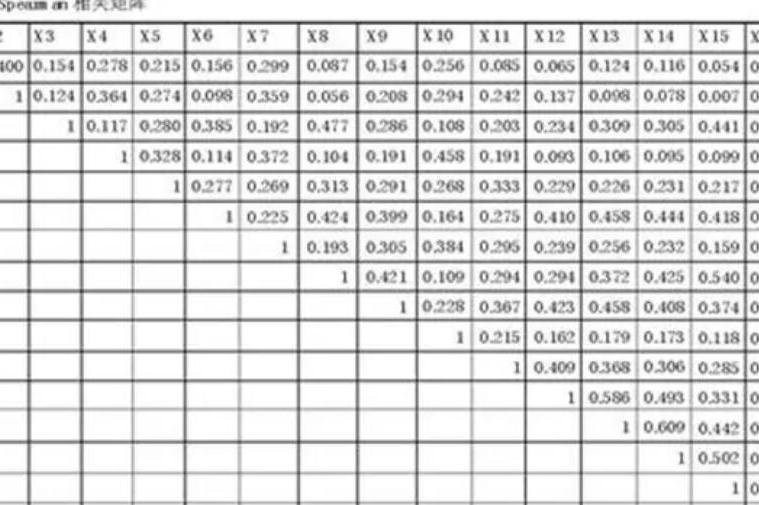
###绘出皮尔森相关系数图谱
def plot_pearson(data):'''小于0.4显著弱相关,0.4-0.75中等相关,大于0.75强相关'''colormap = plt.cm.viridisplt.figure(figsize=(70,70))plt.title('Pearson Correlation of Features', y=1.05, size=15)pearson_coef = data.corr()sns.heatmap(pearson_coef,linewidths=0.1,vmax=1.0, square=True, cmap=colormap, linecolor='white', annot=True)return pearson_coef
pc = plot_pearson(data)
其中黄色块属于相关系数比较大的变量,从上图中可以看到,相关系数大于0.75的变量有PAY_3和PAY_2,PAY_4和PAY_3,PAY_5和PAY_4,PAY_6和PAY_5,-的两两变量之间。
相关性过高的变量不适合建模,需要进行剔除,下面使用IV值来进行进一步筛选。
IV值就是特征的信息量,其主要作用就是当我们在用决策树或逻辑回归构建分类模型时对变量进行筛选。IV值就是衡量自变量的预测能力的大小,与其相似的还有信息增益、基尼系数等。
由于各个变量的量纲和取值区间存在很大的差别,通常会对变量的取值进行分箱并计算证据权重 WOE值( of ) ,从而降低变量属性的个数,并且平滑的变量的变化趋势。在此基础上计算信息价值IV( value) ,一般我们选择 IV值大于0.02的那些变量进入模型。
分箱方法有很多种,下面计算IV值和分箱的方法参考 基于决策树的最优分箱与IV值计算的方法。
利用决策树,er的.tree_属性获得决策树的节点划分值;基于上述得到的划分值,利用.cut函数对变量进行分箱;计算各个分箱的WOE、IV值。
其中WOE值计算方法如下:
W O E i = ln ( B a d i B a d T / G o o d i G o o d T ) \ WOE_{i}=\ln(\frac{Bad_{i}}{Bad_{T}}/\frac{Good_{i}}{Good_{T}}) WOEi=ln(BadTBadi/GoodTGoodi)
其中 i \ i i 指的是特征的第 i \ i i 个取值, B a d i \ Bad_{i} Badi 指该特征区间内“坏”样本的个数, B a d T \ Bad_{T} BadT 指该特征中所有“坏”样本的个数,同理 G o o d i \ Good_{i} Goodi 指该特征区间内“好”样本的个数, G o o d T \ Good_{T} GoodT 指该特征中所有“好”样本的个数。
WOE值有如下功能:
下面三个函数分别定义了获取边界列表的函数、分箱函数、IV值计算函数。
#获取边界值列表函数
from sklearn.tree import DecisionTreeClassifier
def optimal_binning_boundary(x: pd.Series, y: pd.Series, nan: float = -999.) -> list:'''利用决策树获得最优分箱的边界值列表'''boundary = [] # 待return的分箱边界值列表x = x.valuesy = y.values#决策树框架clf = DecisionTreeClassifier(criterion='entropy', #“信息熵”最小化准则划分max_leaf_nodes=6, # 最大叶子节点数min_samples_leaf=0.05) # 叶子节点样本数量最小占比#使用需要分箱的数据进行决策树训练clf.fit(x.reshape(-1, 1), y) # 训练决策树n_nodes = clf.tree_.node_count #树的节点数children_left = clf.tree_.children_left #左子树children_right = clf.tree_.children_right #右子树threshold = clf.tree_.threshold #切分点for i in range(n_nodes):if children_left[i] != children_right[i]: # 获得决策树节点上的划分边界值boundary.append(threshold[i])boundary.sort()min_x = x.min()max_x = x.max() + 0.1 # +0.1是为了考虑后续groupby操作时,能包含特征最大值的样本boundary = [min_x] + boundary + [max_x]print(boundary) #将边界列表打印出来return boundary
#分箱函数
def get_bin(x: pd.Series, y: pd.Series, nan: float = -999.) -> pd.DataFrame:'''利用边界值列表对数据进行分箱'''boundary = optimal_binning_boundary(x, y, nan) # 获得最优分箱边界值列表df = pd.concat([x, y], axis=1) # 合并x、y为一个DataFrame,方便后续计算df.columns = ['x', 'y'] # 特征变量、目标变量字段的重命名df['bins'] = pd.cut(x=x, bins=boundary, right=False,labels=range(6)) # 获得每个x值所在的分箱区间,用0-6标识return df
#计算woe值和IV值
def feature_woe_iv(df: pd.DataFrame, nan: float = -999.) -> pd.DataFrame:'''计算变量各个分箱的WOE、IV值,返回一个DataFrame'''
# boundary = optimal_binning_boundary(x, y, nan) # 获得最优分箱边界值列表
# df = pd.concat([x, y], axis=1) # 合并x、y为一个DataFrame,方便后续计算
# df.columns = ['x', 'y'] # 特征变量、目标变量字段的重命名
# df['bins'] = pd.cut(x=x, bins=boundary, right=False) # 获得每个x值所在的分箱区间grouped = df.groupby('bins')['y'] # 统计各分箱区间的好、坏、总客户数量result_df = grouped.agg([('good', lambda y: (y == 0).sum()), ('bad', lambda y: (y == 1).sum()),('total', 'count')])result_df['good_pct'] = result_df['good'] / result_df['good'].sum() # 好客户占比result_df['bad_pct'] = result_df['bad'] / result_df['bad'].sum() # 坏客户占比result_df['total_pct'] = result_df['total'] / result_df['total'].sum() # 总客户占比result_df['bad_rate'] = result_df['bad'] / result_df['total'] # 坏比率result_df['woe'] = np.log(result_df['good_pct'] / result_df['bad_pct']) # WOEresult_df.loc[result_df['woe'] == np.inf ,'woe'] = 0result_df.loc[result_df['woe'] == -np.inf ,'woe'] = 0result_df['iv'] = (result_df['good_pct'] - result_df['bad_pct']) * result_df['woe'] # IVprint(f"该变量IV = {result_df['iv'].sum()}")return result_df
下面是将各个变量按照离散变量和连续变量分别进行IV值计算,对于离散变量可直接计算IV值,而对于离散值则进行分箱后计算IV值。
#定义连续变量
continuous_v = ['LIMIT_BAL','AGE','BILL_AMT1', 'BILL_AMT2','BILL_AMT3', 'BILL_AMT4', 'BILL_AMT5', 'BILL_AMT6', 'PAY_AMT1','PAY_AMT2', 'PAY_AMT3', 'PAY_AMT4', 'PAY_AMT5', 'PAY_AMT6']
#定义离散变量
discret_v = ['SEX', 'EDUCATION', 'MARRIAGE','PAY_0','PAY_2', 'PAY_3', 'PAY_4', 'PAY_5', 'PAY_6']
#输出连续变量的iv
for column1 in continuous_v:df = get_bin(data[column1],data['default.payment.next.month'])print(feature_woe_iv(df))
#输出离散变量的iv
for column2 in discret_v:df = data[[column2,'default.payment.next.month']]new_columns = pd.core.indexes.base.Index(['bins','y'])df.columns = new_columnsprint(feature_woe_iv(df))
以连续变量为例,追踪其在以上操作中的状态:
首先使用上文提到的方法对该变量确定边界值得到:
[10000.0, 45000.0, 75000.0, 145000.0, 245000.0, 365000.0, 1000000.1]
由于我们的分界采用左闭右开的方式,因此在最后一个边界后加上0.1来保证在区间内。
分箱的区间为:
[10000.0, 45000.0),
[45000.0, 75000.0),
[75000.0, 145000.0),
[145000.0, 245000.0),
[245000.0, 365000.0),
[365000.0, 1000000.1)
上文提到分箱可以达到标准化的目的,具体操作是可以将上面6个区间分别定义label,考虑到其余离散型变量的label范围在0-10之间,这里也采用类似的方法,用0-6的数字代表不同的区间,之后计算各个区间内的WOE和IV值:
good bad total good_pct bad_pct total_pct bad_rate woe iv
bins
0 2756 1555 4311 0.117959 0.234328 0.143700 0.360705 -0.686382 0.079873
1 3593 1328 4921 0.153784 0.200121 0.164033 0.269864 -0.263374 0.012204
2 4619 1439 6058 0.197697 0.216847 0.201933 0.237537 -0.092457 0.001771
3 6317 1326 7643 0.270373 0.199819 0.254767 0.173492 0.302391 0.021335
4 3897 694 4591 0.166795 0.104581 0.153033 0.151165 0.466803 0.029042
5 2182 294 2476 0.093392 0.044304 0.082533 0.118740 0.745730 0.036606
上面的表格可以看到不同的区间内的好坏样本分布情况及其各自的WOE和IV值,计算每个区间IV值的和可以得到该变量的IV值
该变量IV = 0.1808306761199903
下面列出各个变量的IV值如下:
IV值的预测能力准则:
结合之前的相关系数值,可以选择性的留下。
drop_column = ['BILL_AMT1','BILL_AMT2','BILL_AMT3','BILL_AMT4','BILL_AMT6']
for column in drop_column:data = data.drop([column], axis = 1)
x = data.drop(['default.payment.next.month'], axis = 1)
y = data['default.payment.next.month']
建模
本文的主要目的就是根据所给的数据预测最后的欠款情况,采用中GBDT的方法来完成,关于GBDT的理论知识可以参考文章机器学习时代三大神器GBDT、、
GBDT中各个参数的意义如下:
: 最大的弱学习器的个数。: 即每个弱学习器的权重缩减系数νν。: 子采样比例,取值为(0,1],只有一部分样本会去做GBDT的决策树拟合,推荐在[0.5, 0.8]之间。: 划分时考虑的最大特征数,如果是"log2"意味着划分时最多考虑log2N个特征;如果是"sqrt"或者"auto"意味着划分时最多考虑N−−√N个特征。:决策树最大深度。一般取5-8。: 内部节点再划分所需最小样本数,这个值限制了子树继续划分的条件,如果某节点的样本数少于,则不会继续再尝试选择最优特征来进行划分。一般选择总样本数的0.5-1%: 叶子节点最少样本数,这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
在GBDT的预测中,参数的确定很重要但现有的方法中没有比较成熟的算法,本文采用的参数确定方式是使用(网格搜索)方法。
属于自动调参的方法,只要把参数输进去,就能给出最优化的结果和参数。但是这个方法适合于小数据集,一旦数据的量级上去了,很难得出结果。
数据量比较大的时候可以使用一个快速调优的方法——坐标下降。它其实是一种贪心算法:拿当前对模型影响最大的参数调优,直到最优化;再拿下一个影响最大的参数调优,如此下去,直到所有的参数调整完毕。
本例属于二分类作业,最常用也比较科学的评价函数主要是AUC和Gini系数,这里选择AUC作为评价函数。
按照上述方法依次对、、、、进行搜寻,结果如下(过程重复性较高,需要一定的耐心,可参考文章个人信用风险评估模型实例):
变量范围最优结果AUC值
range(40,150,10)
60
0.7836
range(20,401,10)
360
0.7848
range(2,51,2)
40
0.7850
range(2,31,2)
0.7850
[0.02,0.04,0.06,0.08,0.1,0.12]
0.1
0.7850
程序如下:
##GBDT模型
# 导入机器学习包
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import f1_score
from sklearn.cross_validation import train_test_split
from sklearn.model_selection import GridSearchCV# 数据集分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42)model = GradientBoostingClassifier(n_estimators = 20,learning_rate = 0.5,max_depth = 2,random_state = 0)
param ={'n_estimators':[60],'learning_rate':[0.1],'min_samples_split':[360],'min_samples_leaf':[40],'max_depth':[6],'subsample':[0.8],'max_features':['sqrt']}
rsearch = GridSearchCV(estimator = model,param_grid = param,scoring = 'roc_auc',cv = 5,n_jobs = 2)
rsearch.fit(x_train,y_train)
print(rsearch)
print(rsearch.best_score_)
print(rsearch.best_params_)
下面是最终的GBDT模型及其参数,将模型在训练集上训练,并在测试集上验证其效果。
# 最终模型
model = GradientBoostingClassifier(n_estimators = 60,learning_rate = 0.1,min_samples_split = 360,min_samples_leaf=40,max_depth=6,subsample=0.8, max_features='sqrt')
model.fit(x_train,y_train)
y_predprob = model.predict_proba(x_test)[:,1]
本文的问题是一个二分类问题,二分类问题一般采用混淆矩阵、及ROC曲线等评价指标,关于这方面问题可以参考文章二分类评价指标,下面将列出精准率、召回率、真正率、假正率、AUC和KS值、准确率等几个指标。
# 评价指标
from sklearn import metrics
precision, recall, _thresholds = metrics.precision_recall_curve(y_test, y_predprob) #精准率、召回率
TPR,FPR,_thresholds = metrics.roc_curve(y_test,y_predprob)#真正率、假正率
auc = metrics.roc_auc_score(y_test, y_predprob) #AUC
ks = FPR-TPR #KS
下面对一些指标进行画图解释,使得结果更加直观。
# 可视化
#ROC曲线
plt.plot(TPR,FPR,label = 'AUC = {0:.2f}'.format(auc))
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate') # 可以使用中文,但需要导入一些库即字体
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
以上是ROC曲线,是不同阈值下TPR和FPR的曲线,曲线下方的面积就是AUC值,事实上,曲线越靠近左上角表示分类的效果越好,这里显示在测试集上的AUC值大约在0.77。
plt.plot(_thresholds, TPR, color='cadetblue', label='TPR')
plt.plot(_thresholds, FPR, 'seagreen', label='FPR')
plt.fill_between(_thresholds, 0, ks, facecolor='green', alpha=0.3)
plt.legend() #显示上面的label
plt.xlabel('thresholds')
plt.ylabel('TPR and FPR')
plt.show()
上面的图片则显示了不同阈值下的TPR和FPR的值,下方绿色的阴影部分代表KS值,可以看到在大约0.3的位置KS值达到最大值。我们可以取预测的阈值为0.3,也就是说概率大于0.3最终预测为1,否则预测为0。下面则是取阈值为0.3的情况下各个指标的值。
y_test = pd.DataFrame(y_test)
y_test['y_predprob'] = y_predprob
y_test['y_pred'] = np.zeros(9000)
y_test.loc[y_test['y_predprob'] > 0.3,'y_pred'] = 1
print(metrics.confusion_matrix(y_test['default.payment.next.month'], y_test['y_pred'], labels=None, sample_weight=None))
可以看到各个指标的值如下:
指标值
TPR
85.78%
FPR
39.96%
90.05%
85.78%
准确率
80.85%
F1
0.8786
AUC
0.77
KS
0.42
经验及总结 参数的优化可以尝试更佳有效的方式。文章中的阈值选择是依靠最大KS值的方式完成的,然而实际工作中往往发生违约的代价更大,也就是说人们可能更倾向于更低的阈值。针对GBM算法,如果对于计算性能没有要求,通常不推荐删除变量,更推荐增加一些衍生变量。因为GBM算法本身会自动调整不同变量的权重,对变量之间的相关性等也不敏感。