搞懂机器视觉 Transformer 神经网络的原理和代码详解(图文详解)。
来源于:
是 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 。 模型使用了 Self- 机制,不采用RNN顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。本文将对 的原理和代码进行非常全面的解读。考虑到每篇文章字数的限制,每一篇文章将按照目录的编排包含三个小节,而且这个系列会随着 的发展而长期更新。
目录
(每篇文章对应一个,目录持续更新。)
1 一切从Self-开始
1.1 处理数据的模型
1.2 Self-
1.3 Multi-head Self-
1.4
2 的实现和代码解读 ()
(来自 , Brain Team)
2.1 原理分析
2.2 代码解读
3 +:引入视觉领域的首创DETR ()
(来自 AI)
3.1 DETR原理分析
3.2 DETR代码解读
4 +: DETR:可变形的 ()
(来自商汤代季峰老师组)
4.1 DETR原理分析
4.2 DETR代码解读
5 +:用于分类任务的 **
()**
(来自 , Brain Team)
5.1 ViT原理分析
5.2 ViT代码解读
6 +Image :IPT:用于底层视觉任务的
(来自北京华为诺亚方舟实验室)
6.1 IPT原理分析
7 +:SETR:基于 的语义分割
(来自复旦大学,腾讯优图等)
7.1 SETR原理分析
8 +GAN:VQGAN:实现高分辨率的图像生成
(来自德国海德堡大学)
8.1 VQGAN原理分析
8.2 VQGAN代码解读
9 +:DeiT:高效图像
(来自 AI)
9.1 DeiT原理分析
是 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 。 模型使用了 Self- 机制,不采用 RNN 的**
顺序结构**,使得模型可以并行化训练,而且能够拥有全局信息。
1 一切从Self-开始
是一个 to model,特别之处在于它大量用到了self-。
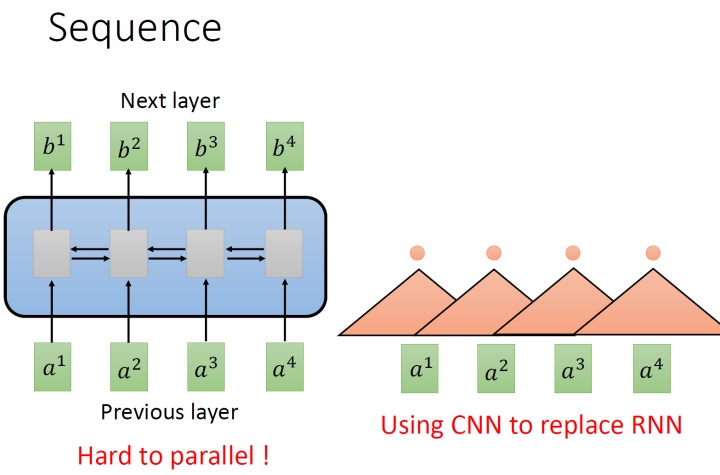
要处理一个,最常想到的就是使用RNN,它的输入是一串 ,输出是另一串 ,如下图1左所示。
如果假设是一个 的RNN,那当输出 b4 时,默认 a1,a2,a3,a4 都已经看过了。如果假设是一个bi-的RNN,那当输出 b任意 时,默认 a1,a2,a3,a4 都已经看过了。RNN非常擅长于处理input是一个的状况。
那RNN有什么样的问题呢?它的问题就在于:RNN很不容易并行化 (hard to )。
为什么说RNN很不容易并行化呢?假设在 的RNN的情形下,你今天要算出 b4 ,就必须要先看 a1 再看 a2 再看 a3 再看 a4 ,所以这个过程很难平行处理。
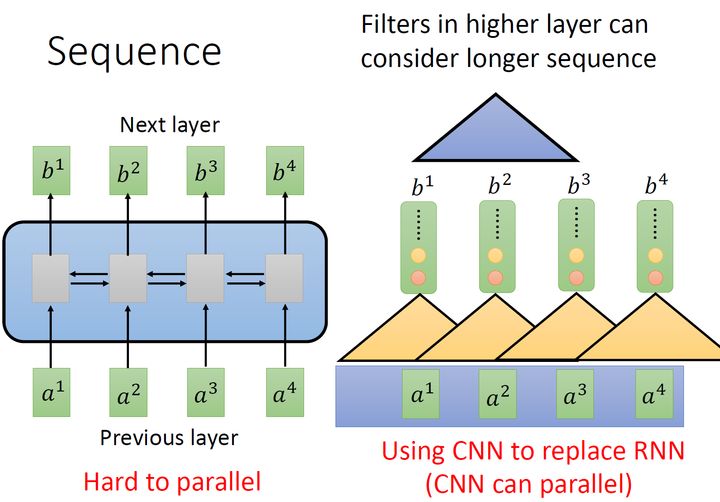
所以今天就有人提出把CNN拿来取代RNN,如下图1右所示。其中,橘色的三角形表示一个,每次扫过3个向量 a ,扫过一轮以后,就输出了一排结果,使用橘色的小圆点表示。
这是第一个橘色的的过程,还有其他的,比如图2中的黄色的,它经历着与橘色的相似的过程,又输出一排结果,使用黄色的小圆点表示。
所以,用CNN,你确实也可以做到跟RNN的输入输出类似的关系,也可以做到输入是一个,输出是另外一个。
但是,表面上CNN和RNN可以做到相同的输入和输出,但是CNN只能考虑非常有限的内容。比如在我们右侧的图中CNN的只考虑了3个,不像RNN可以考虑之前的所有。但是CNN也不是没有办法考虑很长时间的的,你只需要堆叠,多堆叠几层,上层的就可以考虑比较多的资讯,比如,第二层的 (蓝色的三角形)看了6个,所以,只要叠很多层,就能够看很长时间的资讯。
而CNN的一个好处是:它是可以并行化的 (can ),不需要等待红色的算完,再算黄色的。但是必须要叠很多层,才可以看到长时的资讯。所以今天有一个想法:self-,如下图3所示,目的是使用self- layer取代RNN所做的事情。
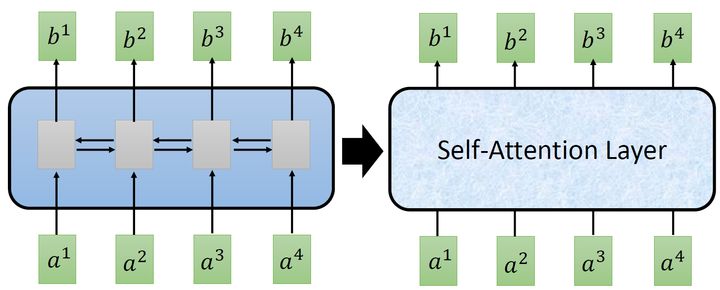
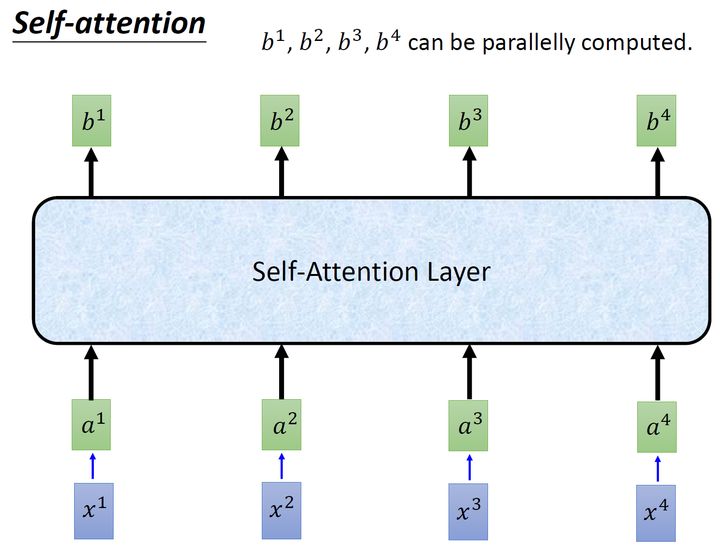
所以重点是:我们有一种新的layer,叫self-,它的输入和输出和RNN是一模一样的,输入一个,输出一个,它的每一个输出 b1−b4 都看过了整个的输入,这一点与bi- RNN相同。但是神奇的地方是:它的每一个输出 b1−b4可以并行化计算。
那么self-具体是怎么做的呢?
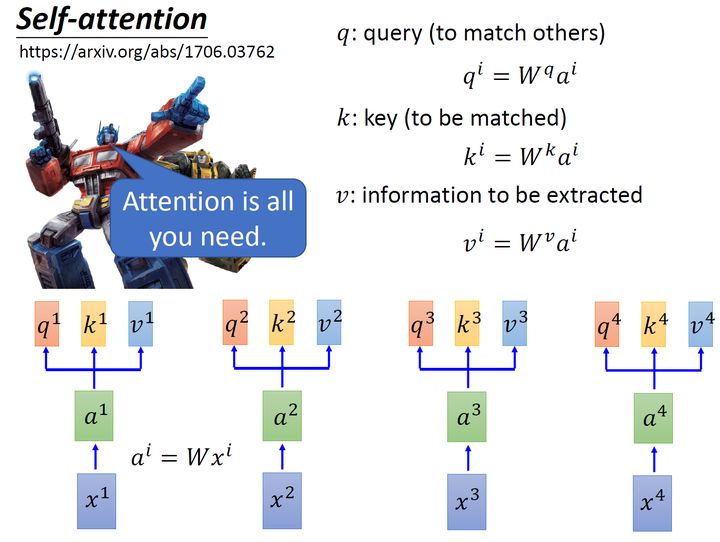
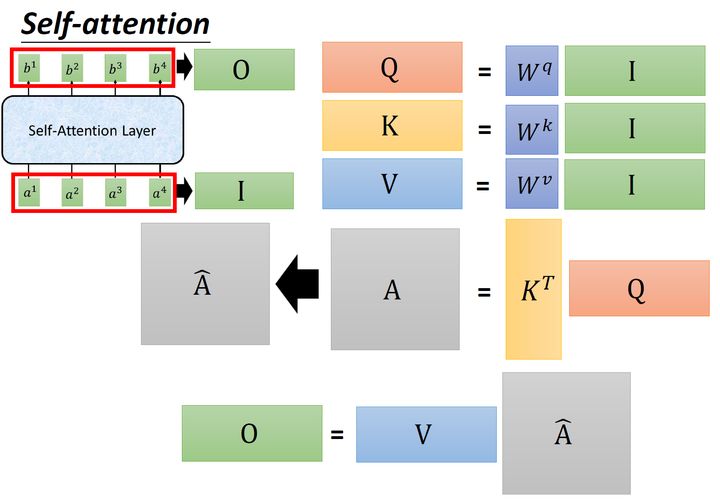
首先假设我们的input是图4的 x1−x4 ,是一个,每一个input ()先乘上一个矩阵 W 得到,即向量 a1−a4 。接着这个进入self-层,每一个向量 a1−a4 分别乘上3个不同的 Wq,Wk,Wv ,以向量 a1 为例,分别得到3个不同的向量 q1,k1,v1 。
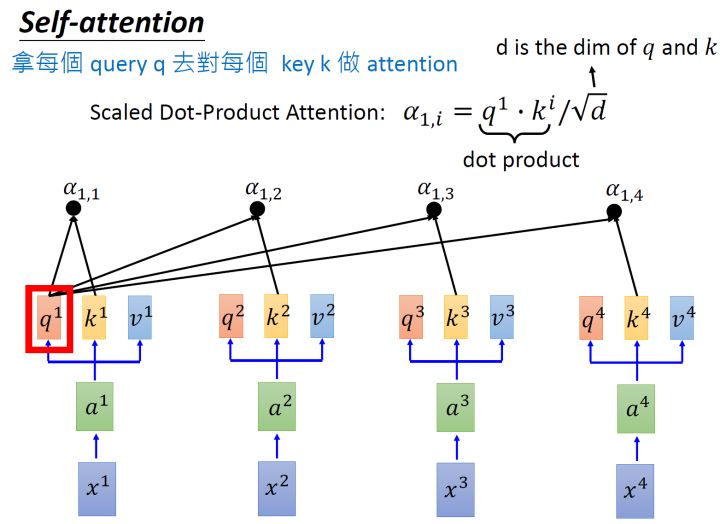
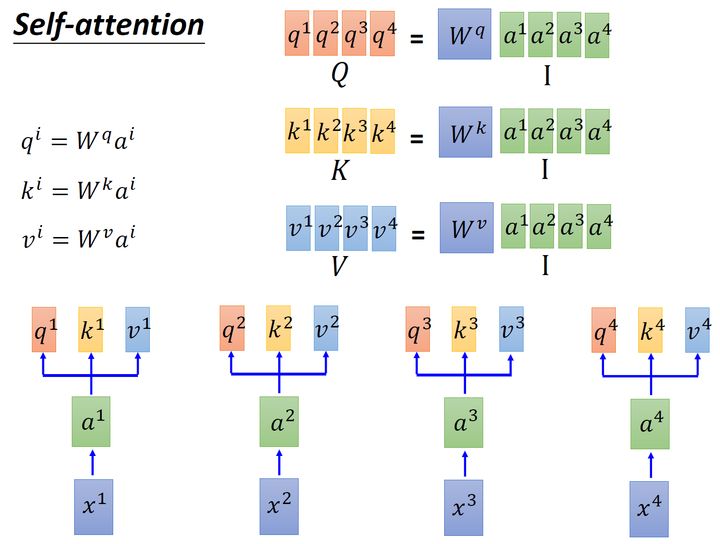
接下来使用每个query q 去对每个key k 做,就是匹配这2个向量有多接近,比如我现在要对 q1 和 k1 做,我就可以把这2个向量做 inner ,得到 α1,1 。接下来你再拿 q1 和 k2 做,得到 α1,2 ,你再拿 q1 和 k3 做,得到 α1,3 ,你再拿 q1 和 k4 做,得到 α1,4 。那这个 inner 具体是怎么计算的呢?
α1,i=q1⋅ki/d(1)
式中, d 是 q 跟 k 的维度。因为 q⋅k 的数值会随着的增大而增大,所以要除以 的值,相当于归一化的效果。
接下来要做的事如图6所示,把计算得到的所有 α1,i 值取 操作。
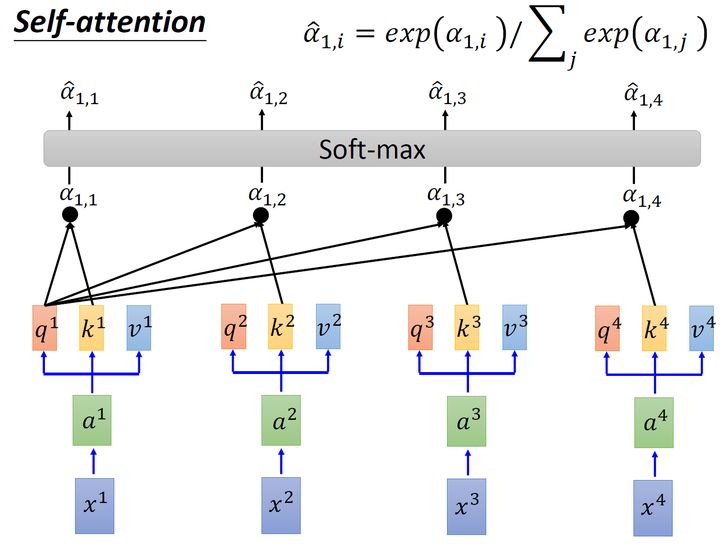
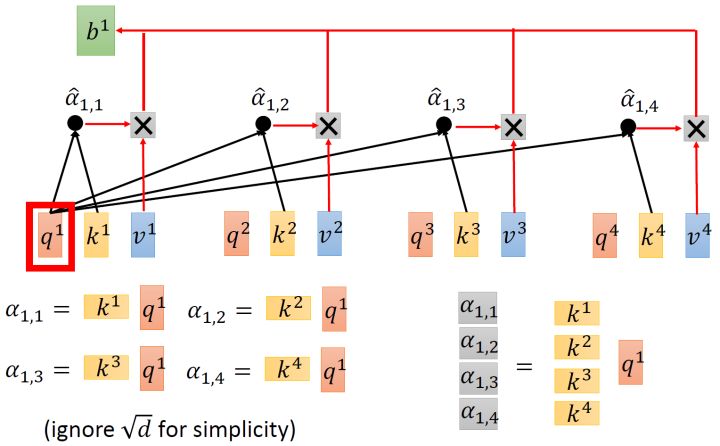
取完 操作以后,我们得到了 α^1,i ,我们用它和所有的 vi 值进行相乘。具体来讲,把 α^1,1 乘上 v1 ,把 α^1,2 乘上 v2 ,把 α^1,3 乘上 v3 ,把 α^1,4 乘上 v4 ,把结果通通加起来得到 b1 ,所以,今天在产生 b1 的过程中用了整个的资讯 ( the whole )。如果要考虑local的,则只需要学习出相应的 α^1,i=0 , b1 就不再带有那个对应分支的信息了;如果要考虑的,则只需要学习出相应的 α^1,i=0 , b1 就带有全部的对应分支的信息了。
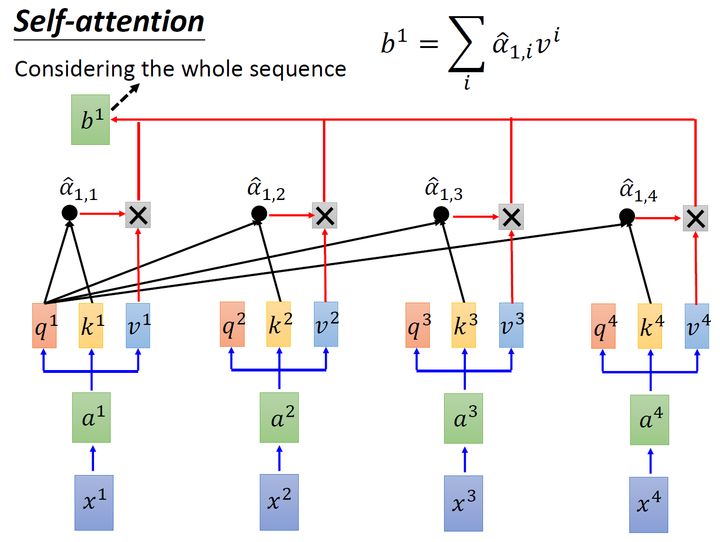
同样的方法,也可以计算出 b2,b3,b4 ,如下图8所示, b2 就是拿query q2去对其他的 k 做,得到 α^2,i ,再与value值 vi 相乘取 sum得到的。
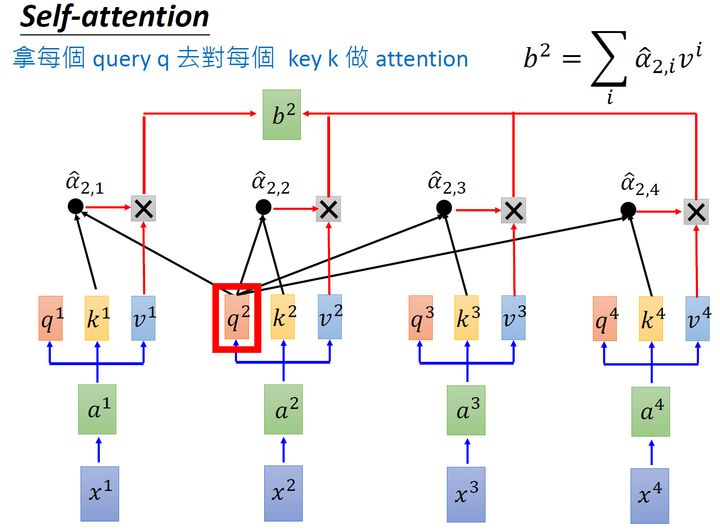
经过了以上一连串计算,self- layer做的事情跟RNN是一样的,只是它可以并行的得到layer输出的结果,如图9所示。现在我们要用矩阵表示上述的计算过程。
首先输入的是 I=[a1,a2,a3,a4] ,然后用 I 乘以 Wq 得到 Q=[q1,q2,q3,q4] ,它的每一列代表着一个 q 。同理,用 I 乘以 Wk 得到 K=[k1,k2,k3,k4] ,它的每一列代表着一个 k 。用 I 乘以 Wv 得到 Q=[v1,v2,v3,v4] ,它的每一列代表着一个 v 。
接下来是 k 与 q 的过程,我们可以把 k 横过来变成行向量,与列向量 q 做内积,这里省略了 d 。这样, α 就成为了 4×4 的矩阵,它由4个行向量拼成的矩阵和4个列向量拼成的矩阵做内积得到,如图11所示。
在得到 A^ 以后,如上文所述,要得到 b1, 就要使用 α^1,i 分别与 bi 相乘再求和得到,所以 A^ 要再左乘 V 矩阵。

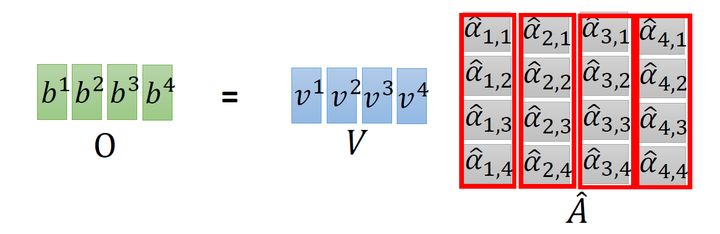
到这里你会发现这个过程可以被表示为,如图12所示:输入矩阵 I∈R(d,N) 分别乘上3个不同的矩阵 Wq,Wk,Wv∈R(d,d) 得到3个中间矩阵 Q,K,V∈R(d,N) 。它们的维度是相同的。把 K 转置之后与 Q 相乘得到矩阵 A∈R(N,N) ,代表每一个位置两两之间的。再将它取 操作得到 A^∈R(N,N) ,最后将它乘以 V 矩阵得到输出 O∈R(d,N) 。
A^=(A)=KT⋅Q(2)
O=V⋅A^(3)
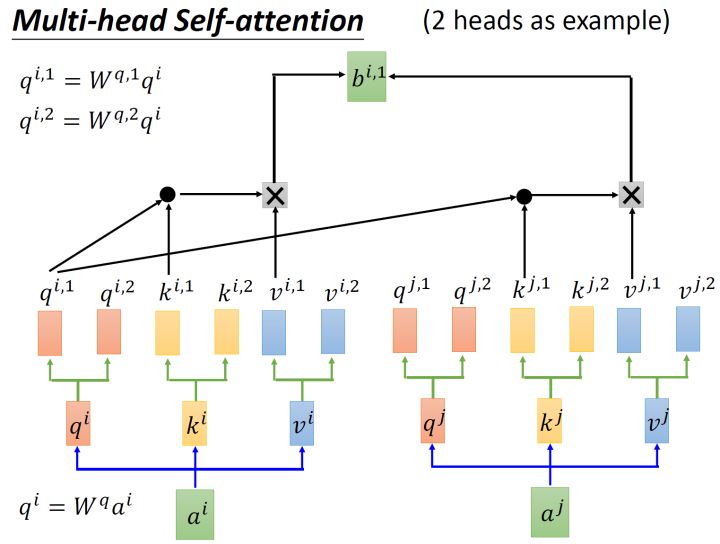
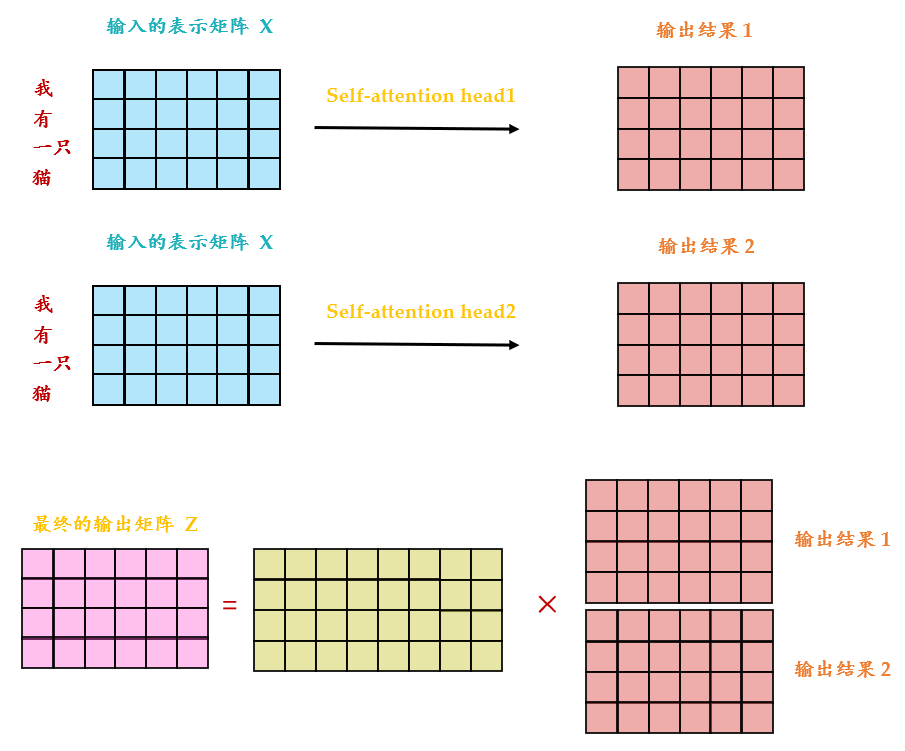
还有一种multi-head的self-,以2个head的情况为例:由 ai 生成的 qi 进一步乘以2个转移矩阵变为 qi,1 和 qi,2 ,同理由 ai 生成的 ki 进一步乘以2个转移矩阵变为 ki,1 和 ki,2 ,由 ai 生成的 vi 进一步乘以2个转移矩阵变为 vi,1 和 vi,2 。接下来 qi,1 再与 ki,1 做,得到 sum的权重 α ,再与 vi,1 做 sum得到最终的 bi,1(i=1,2,...,N) 。同理得到 bi,2(i=1,2,...,N) 。现在我们有了 bi,1(i=1,2,...,N)∈R(d,1) 和 bi,2(i=1,2,...,N)∈R(d,1) ,可以把它们起来,再通过一个 调整维度,使之与刚才的 bi(i=1,2,...,N)∈R(d,1) 维度一致(这步如图13所示)。
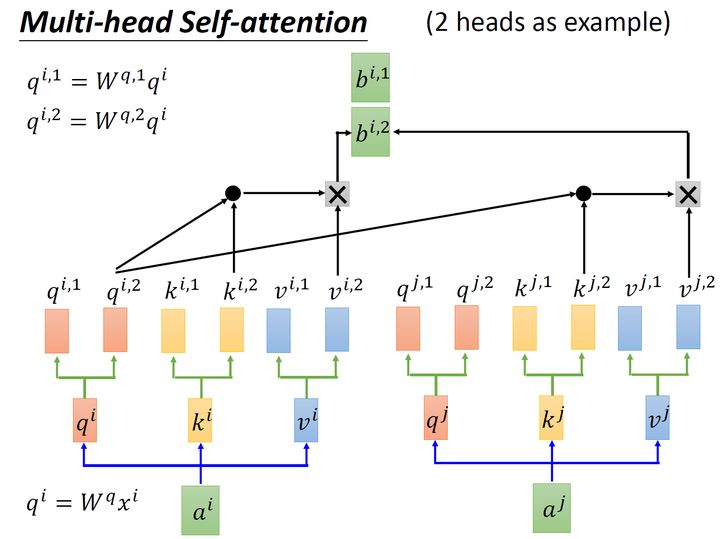
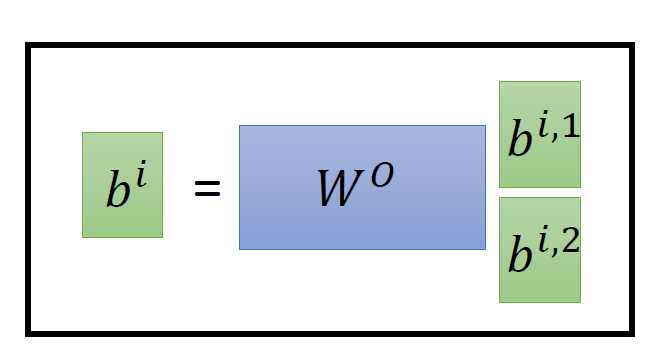
从下图14可以看到 Multi-Head 包含多个 Self- 层,首先将输入 X 分别传递到 2个不同的 Self- 中,计算得到 2 个输出结果。得到2个输出矩阵之后,Multi-Head 将它们拼接在一起 (),然后传入一个层,得到 Multi-Head 最终的输出 Z 。可以看到 Multi-Head 输出的矩阵 Z 与其输入的矩阵 X 的维度是一样的。
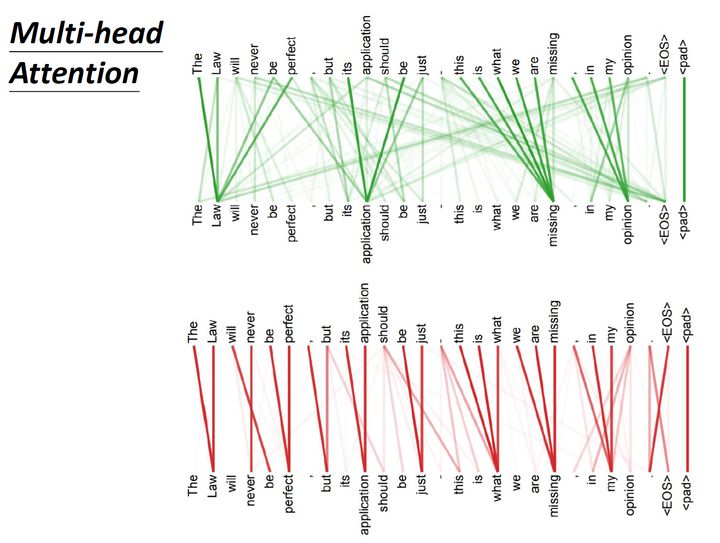
这里有一组Multi-head Self-的解果,其中绿色部分是一组query和key,红色部分是另外一组query和key,可以发现绿色部分其实更关注的信息,而红色部分其实更关注local的信息。
以上是multi-head self-的原理,但是还有一个问题是:现在的self-中没有位置的信息,一个单词向量的“近在咫尺”位置的单词向量和“远在天涯”位置的单词向量效果是一样的,没有表示位置的信息(No in self )。所以你输入"A打了B"或者"B打了A"的效果其实是一样的,因为并没有考虑位置的信息。所以在self-原来的paper中,作者为了解决这个问题所做的事情是如下图16所示:
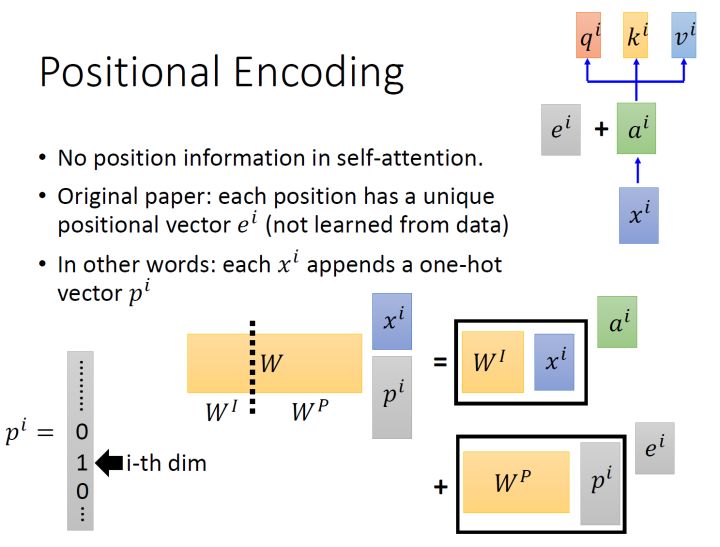
具体的做法是:给每一个位置规定一个表示位置信息的向量 ei ,让它与 ai 加在一起之后作为新的 ai 参与后面的运算过程,但是这个向量 ei 是由人工设定的,而不是神经网络学习出来的。每一个位置都有一个不同的 ei 。
那到这里一个自然而然的问题是:为什么是 ei 与 ai 相加?为什么不是?加起来以后,原来表示位置的资讯不就混到 ai 里面去了吗?不就很难被找到了吗?
这里提供一种解答这个问题的思路:
如图15所示,我们先给每一个位置的 xi∈R(d,1) 一个one-hot编码的向量 pi∈R(N,1) ,得到一个新的输入向量 xpi∈R(d+N,1) ,这个向量作为新的输入,乘以一个 W=[WI,WP]∈R(d,d+N) 。那么:
W⋅xpi=[WI,WP]⋅[xipi]=WI⋅xi+WP⋅pi=ai+ei(4)
所以,ei 与 ai 相加就等同于把原来的输入 xi 一个表示位置的独热编码 pi ,再做。
这个与位置编码乘起来的矩阵 WP 是手工设计的,如图17所示。
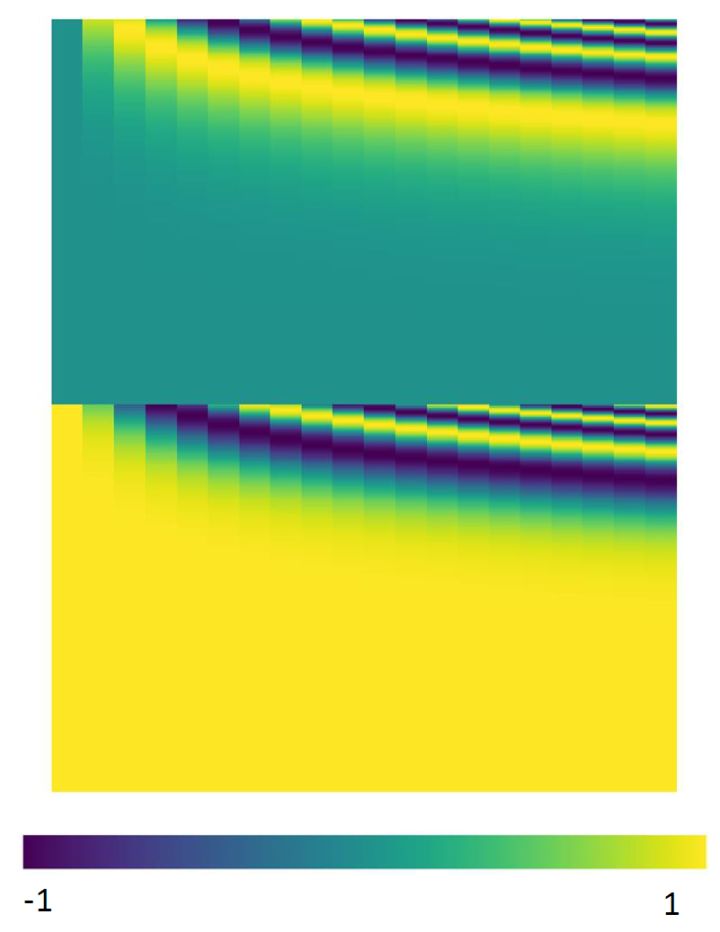
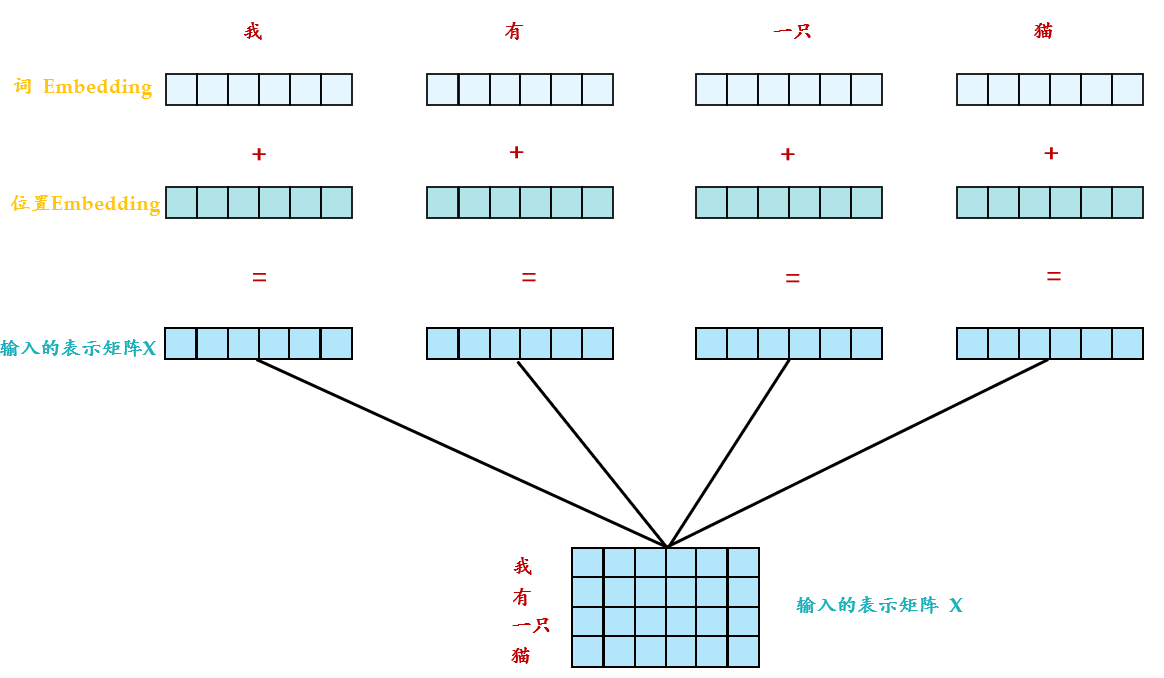
中除了单词的 ,还需要使用位置 表示单词出现在句子中的位置。因为 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以 中使用位置 保存单词在序列中的相对或绝对位置。
位置 用 PE表示,PE 的维度与单词 是一样的。PE 可以通过训练得到,也可以使用某种公式计算得到。在 中采用了后者,计算公式如下:
PE(pos,2i)=sin(pos//)PE(pos,2i+1)=cos(pos//)(5)
式中, pos 表示token在中的位置,例如第一个token "我" 的 pos=0 。
i ,或者准确意义上是 2i 和 2i+1 表示了 的维度,i 的取值范围是: [0,…,/2) 。所以当 pos 为1时,对应的 可以写成:
PE(1)=[sin(1//512),cos(1//512),sin(1//512),cos(1//512),…]
式中, =512。底数是10000。为什么要使用10000呢,这个就类似于玄学了,原论文中完全没有提啊,这里不得不说说论文的的问题,即便是很多高引的文章,最基本的内容都讨论不清楚,所以才出现像上面提问里的讨论,说实话这些论文还远远没有做到easy to 。这里我给出一个假想:/512是一个比较接近1的数(1.018),如果用,则是1.023。这里只是猜想一下,其实大家应该完全可以使用另一个底数。
这个式子的好处是:
cos(α+β)=cos(α)cos(β)−sin(α)sin(β)
sin(α+β)=sin(α)cos(β)+cos(α)sins(β)
接下来我们看看self-在 model里面是怎么使用的,我们可以把-中的RNN用self-取代掉。
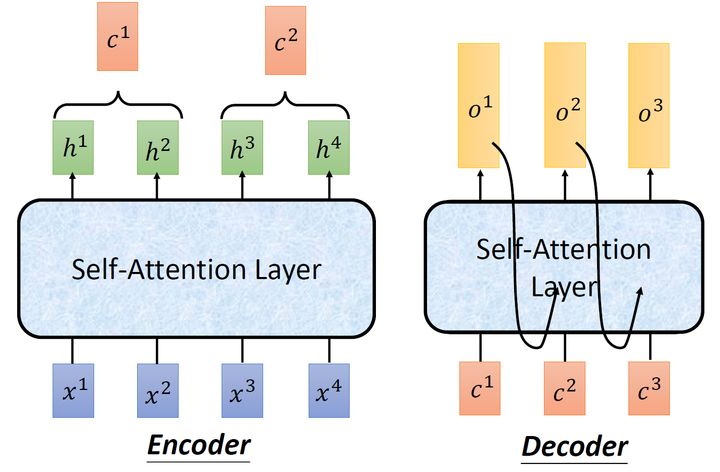
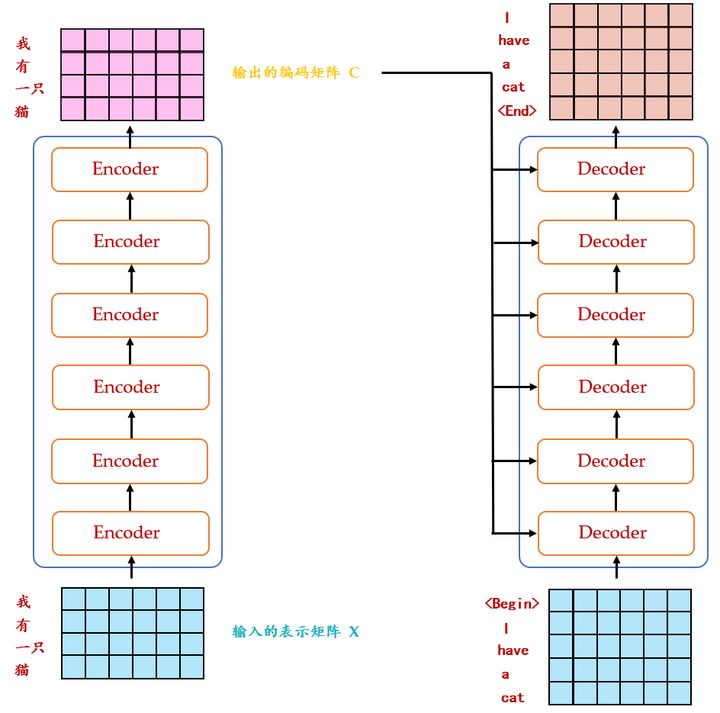
2 的实现和代码解读
:
这个图19讲的是一个的model,左侧为 block,右侧为 block。红色圈中的部分为Multi-Head ,是由多个Self-组成的,可以看到 block 包含一个 Multi-Head ,而 block 包含两个 Multi-Head (其中有一个用到 )。Multi-Head 上方还包括一个 Add & Norm 层,Add 表示残差连接 ( ) 用于防止网络退化,Norm 表示 Layer ,用于对每一层的激活值进行归一化。比如说在 Input处的输入是机器学习,在 Input处的输入是,输出是。再下一个时刻在 Input处的输入是,输出是。不断重复知道输出是句点(.)代表翻译结束。
接下来我们看看这个和里面分别都做了什么事情,先看左半部分的:首先输入 X∈R(nx,N) 通过一个Input 的转移矩阵 WX∈R(d,nx) 变为了一个张量,即上文所述的 I∈R(d,N) ,再加上一个表示位置的 E∈R(d,N) ,得到一个张量,去往后面的操作。
它进入了这个绿色的block,这个绿色的block会重复 N 次。这个绿色的block里面有什么呢?它的第1层是一个上文讲的multi-head的。你现在一个 I∈R(d,N) ,经过一个multi-head的,你会得到另外一个 O∈R(d,N) 。
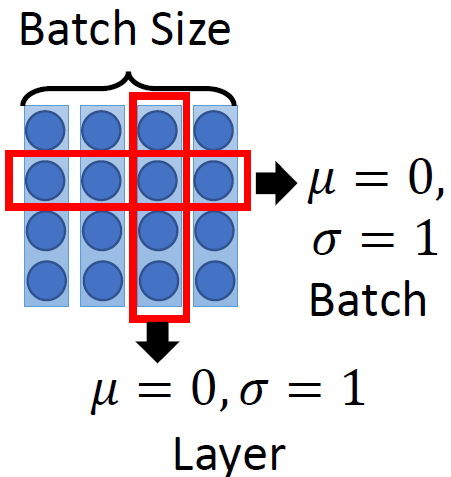
下一个Layer是Add & Norm,这个意思是说:把multi-head的的layer的输入 I∈R(d,N) 和输出 O∈R(d,N) 进行相加以后,再做Layer ,至于Layer 和我们熟悉的Batch 的区别是什么,请参考图20和21。
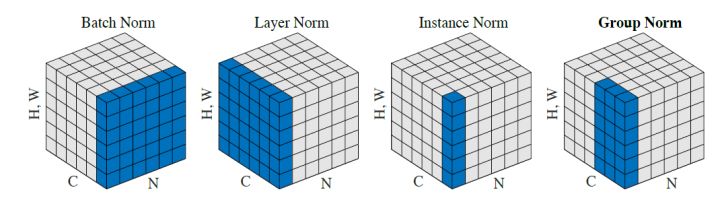
其中,Batch 和Layer 的对比可以概括为图20,Batch 强行让一个batch的数据的某个的 μ=0,σ=1 ,而Layer 让一个数据的所有的 μ=0,σ=1 。
接着是一个Feed 的前馈网络和一个Add & Norm Layer。
所以,这一个绿色的block的前2个Layer操作的表达式为:
O1=(I+Multi--(I))(6)
这一个绿色的block的后2个Layer操作的表达式为:
O2=(O1+(O1))(7)
Block(I)=O2(8)
所以的的整体操作为:
(I)=Block(...Block(Block)(I))(9)
:
现在来看的部分,输入包括2部分,下方是前一个time step的输出的,即上文所述的 I∈R(d,N) ,再加上一个表示位置的 E∈R(d,N) ,得到一个张量,去往后面的操作。它进入了这个绿色的block,这个绿色的block会重复 N 次。这个绿色的block里面有什么呢?
首先是 Multi-Head Self-,的意思是使只会 on已经产生的,这个很合理,因为还没有产生出来的东西不存在,就无法做。
输出是: 对应 i 位置的输出词的概率分布。
输入是: **
的输出** 和 **
对应** i−1 **
位置的输出**。所以中间的不是self-,它的Key和Value来自,Query来自上一位置 的输出。
解码:这里要特别注意一下,编码可以并行计算,一次性全部出来,但解码不是一次把所有序列解出来的,而是像 RNN **
一样一个一个解出来的**,因为要用上一个位置的输入当作的query。
明确了解码过程之后最上面的图就很好懂了,这里主要的不同就是新加的另外要说一下新加的多加了一个mask,因为训练时的都是 Truth,这样可以确保预测第 i 个位置时不会接触到未来的信息。
下面详细介绍下 Multi-Head Self-的具体操作,在Scale操作之后,操作之前。

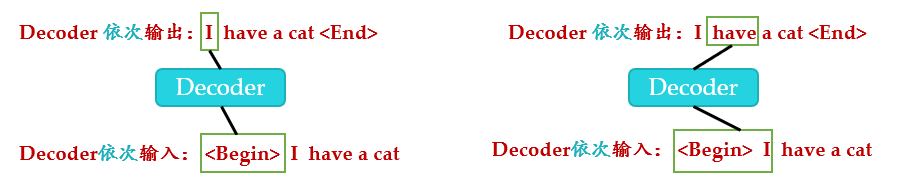
因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 操作可以防止第 i 个单词知道第 i+1 个单词之后的信息。下面以 "我有一只猫" 翻译成 "I have a cat" 为例,了解一下 操作。在 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入 "" 预测出第一个单词为 "I",然后根据输入 " I" 预测下一个单词 "have"。
可以在训练的过程中使用 并且并行化训练,即将正确的单词序列 ( I have a cat) 和对应输出 (I have a cat ) 传递到 。那么在预测第 i **
个输出时,就要将第** i+1 **
之后的单词掩盖住,**注意 Mask 操作是在 Self- 的 之前使用的,下面用 0 1 2 3 4 5 分别表示 " I have a cat "。
注意这里模型训练和测试的方法不同:
测试时:
输入,解码器输出 I 。输入前面已经解码的和 I,解码器输出have。输入已经解码的,I, have, a, cat,解码器输出解码结束标志位,每次解码都会利用前面已经解码输出的所有单词嵌入信息。
测试时的解码过程:
训练时:
不采用上述类似RNN的方法 一个一个目标单词嵌入向量顺序输入训练,想采用**
类似编码器中的矩阵并行算法,一步就把所有目标单词预测出来**。要实现这个功能就可以参考编码器的操作,把目标单词嵌入向量组成矩阵一次输入即可。即:并行化训练。
但是在解码have时候,不能利用到后面单词a和cat的目标单词嵌入向量信息,否则这就是作弊(测试时候不可能能未卜先知)。为此引入mask。具体是:在解码器中,self-层只被允许处理输出序列中更靠前的那些位置,在步骤前,它会把后面的位置给隐去。
Multi-Head Self-的具体操作 如图24所示。
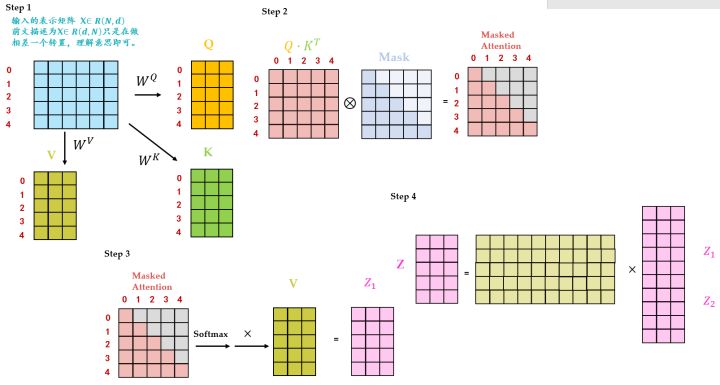
Step1: 输入矩阵包含 " I have a cat" (0, 1, 2, 3, 4) 五个单词的表示向量,Mask是一个 5×5 的矩阵。在Mask可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息。输入矩阵 X∈RN,dx 经过 变为3个矩阵:Query Q∈RN,d ,Key K∈RN,d 和Value V∈RN,d 。
Step2: QT⋅K 得到 矩阵 A∈RN,N ,此时先不急于做的操作,而是先于一个 Mask∈RN,N 矩阵相乘,使得矩阵的有些位置 归0,得到 矩阵 ∈RN,N 。 Mask∈RN,N 矩阵是个下三角矩阵,为什么这样设计?是因为想在计算 Z 矩阵的某一行时,只考虑它前面token的作用。即:在计算 Z 的第一行时,刻意地把 矩阵第一行的后面几个元素屏蔽掉,只考虑 ,0 。在产生have这个单词时,只考虑 I,不考虑之后的have a cat,即只会 on已经产生的,这个很合理,因为还没有产生出来的东西不存在,就无法做。
Step3: 矩阵进行 ,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 score 都为 0。得到的结果再与 V 矩阵相乘得到最终的self-层的输出结果 Z1∈RN,d 。
Step4: Z1∈RN,d 只是某一个head的结果,将多个head的结果在一起之后再最后进行 得到最终的 Multi-Head Self-的输出结果 Z∈RN,d 。
第1个** Multi-Head Self-**
的 Query,Key,Value 均来自 。
第2个** Multi-Head Self-**
的 Query 来自第1个Self- layer的输出, Key,Value 来自的输出。
为什么这么设计? 这里提供一种个人的理解:
Key,Value 来自 的输出,所以可以看做句子()/图片(image)的内容信息(,比如句意是:"我有一只猫",图片内容是:"有几辆车,几个人等等")。
Query 表达了一种诉求:希望得到什么,可以看做引导信息(guide)。
通过Multi-Head Self-结合在一起的过程就相当于是把我们需要的内容信息指导表达出来。
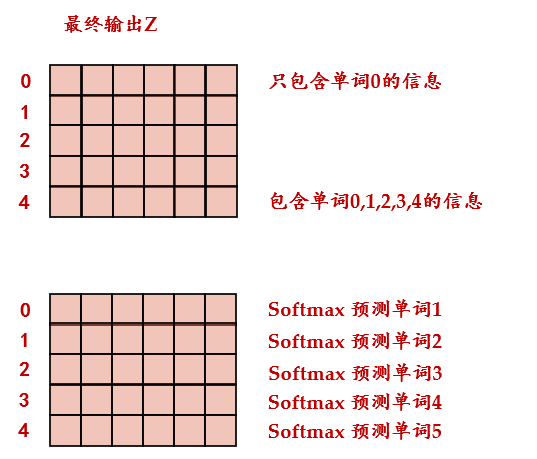
的最后是 预测输出单词。因为 Mask 的存在,使得单词 0 的输出 Z(0,) 只包含单词 0 的信息。 根据输出矩阵的每一行预测下一个单词,如下图25所示。
如下图26所示为的整体结构。
代码来自:
ntion:
实现的是图22的操作,先令 Q⋅KT ,再对结果按位乘以 Mask 矩阵,再做 操作,最后的结果与 V 相乘,得到self-的输出。
class ScaledDotProductAttention(nn.Module):''' Scaled Dot-Product Attention '''def __init__(self, temperature, attn_dropout=0.1):super().__init__()self.temperature = temperatureself.dropout = nn.Dropout(attn_dropout)def forward(self, q, k, v, mask=None):attn = torch.matmul(q / self.temperature, k.transpose(2, 3))if mask is not None:attn = attn.masked_fill(mask == 0, -1e9)attn = self.dropout(F.softmax(attn, dim=-1))output = torch.matmul(attn, v)return output, attn