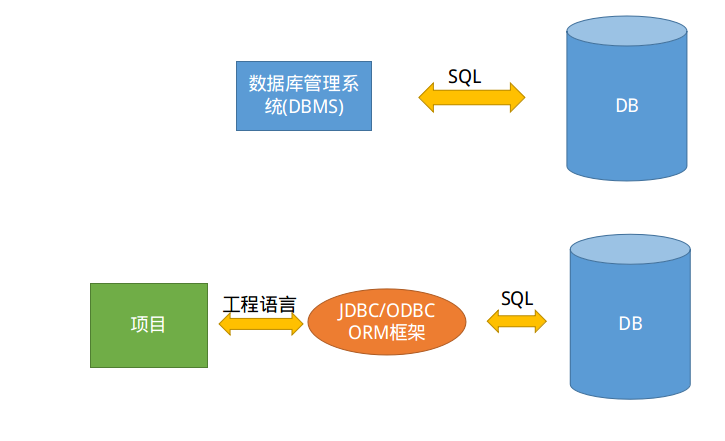
什么是关系型数据库和非关系型数据库(简介两者定义及优劣势)
目前主流的关系型数据库包括 DB2、 SQL 、 MySQL 等。
非关系型数据库包括 NoSql、.
Nosql和关系数据库比较?
优势:
1)成本:nosql数据库简单易部署。它基本上是一个开源软件。它不需要花很多钱购买和使用它。它比关系数据库便宜。
2)查询速度:nosql数据库将数据存储在缓存中,关系数据库将数据存储在硬盘中,自然查询速度远低于nosql数据库。
3)存储数据的格式:nosql的存储格式有key、value形式、形式、image形式等,所以可以存储基本类型和对象或集合等多种格式,而数据库只支持基本类型。
4)可扩展性:关系型数据库在join等多表查询机制上存在局限性,难以扩展。
缺点:
1)维护的工具和材料是有限的,因为nosql是一个新技术,10多年都无法和关系型数据库的技术相比。
2)不提供对sql的支持,如果不支持sql等行业标准,用户学习使用会产生一定的成本。
3)不提供关系数据库处理事物。
非关系型数据库的优点:1.性能NOSQL是基于键值对的,可以想象成表中主键和值的对应关系,不需要SQL解析层,所以性能非常高。2. 可扩展性也是基于键值对,数据之间没有耦合,所以很容易横向扩展。
关系型数据库的优点:1.复杂的查询可以使用SQL语句轻松的在一张表和多张表之间进行非常复杂的数据查询。2. 事务支持实现了具有高安全性能的数据访问要求。对于这两种类型的数据库,彼此的长处就是它们的短处,反之亦然。
关系数据库以行和列的二进制表示形式表示所有数据。
关系数据库的优点:
1. 保持数据一致(事务)
2.由于标准化的前提,数据更新的开销很小(同一个字段基本只有一个地方)
3. 可以执行Join等复杂查询
保持数据一致性的能力是关系数据库的最大优势。
关系数据库的缺点:
处理不当
1. 大量数据的写处理
2. 对有数据更新的表进行索引或表结构 () 更改
3. 适用于字段不固定时
4. 处理需要快速返回结果的简单查询
--大量数据的写入处理
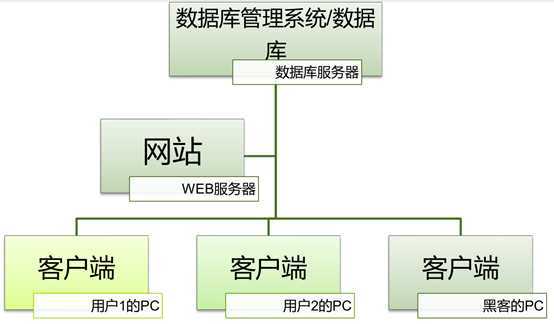
读写集中在一个数据库上,使数据库不堪重负。大多数网站都采用了主从复制技术来实现读写分离,以提高读写性能和读取数据库的可扩展性。
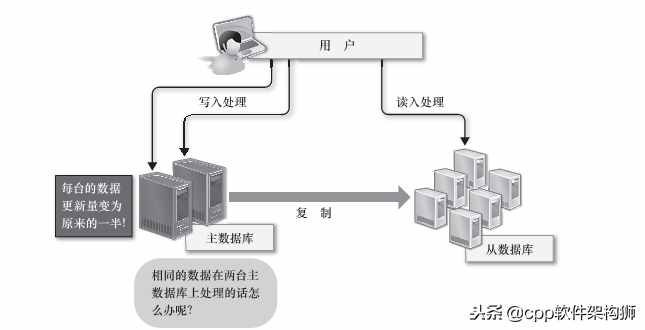
因此,在进行大量数据操作时,会采用数据库主从模式。主库负责数据写入,从库负责数据读取。增加二级数据库实现规模化比较简单,但是写入数据时没有简单的办法解决规模化问题。
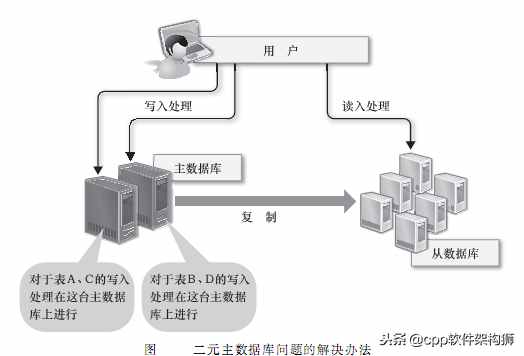
首先,如果要扩展数据写入,可以考虑将主数据库的数量从一个增加到两个,并将它们用作相互复制的二进制主数据库。实际上,这可以将每个主数据库的负载减少一半。但是在更新处理过程中会出现冲突,可能会导致数据不一致。为了避免此类问题,需要将每张表的请求分配给相应的主数据库进行处理。
其次,可以考虑对数据库进行划分,放在不同的数据库服务器上,比如把不同的表放在不同的数据库服务器上。数据库切分可以减少每个数据库服务器上的数据量,从而减少硬盘IO,可以实现对内存的高速处理。但是,由于无法在单独存储单词的不同服务器上的表之间进行join处理,所以在分库时需要提前考虑这些问题。分库后,如果要进行join处理,必须在程序中进行关联。这是非常困难的。
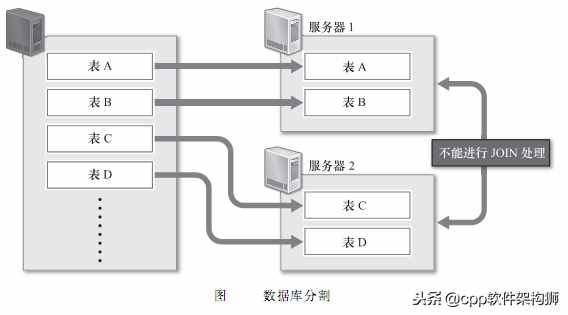
--对有数据更新的表做索引或表结构变化
使用关系型数据库时,为了加快查询速度,需要创建索引,而为了增加必要的字段,必须改变表结构。是不可能的。如果需要进行一些耗时的操作,比如为数据量大的表创建索引或者改变表结构等,需要特别注意,数据可能很长一段时间都不会更新。
--字段不固定时的应用
如果字段不固定,也很难使用关系数据库。有人会说,需要的时候加个字段就够了。这种方法也不是不可能,但在实际应用中,每次都会重复表结构的变化。很痛苦。也可以预先设置大量的初步字段,但是这种情况下,随着时间的推移,很容易丢失字段和数据的对应状态,即哪些字段持有哪些数据。
-- 处理需要快速返回结果的简单查询(这里的“简单”是指没有复杂的查询条件)
这不是缺点,但无论如何,关系型数据库对于简单的查询并不擅长快速返回结果,因为关系型数据库使用一种特殊的 SQL 语言进行数据读取,并且需要解析 SQL 和越南,而且还有额外的开销例如锁定和解锁表。这并不是说关系数据库太慢,只是想告诉你,如果你想高速处理简单的查询,没有必要使用关系数据库。不可能。
--------------------------------------
NoSQL 数据库
关系数据库应用广泛,可以执行复杂的查询,例如事务处理和表连接。相比之下,NoSQL 数据库只用在特定领域,基本不进行复杂的处理,只是弥补了上面列出的关系型数据库的不足。
优势:
易于数据传播
各种数据之间的关系是关系数据库得名的主要原因。关系型数据库为了进行join处理,不得不将数据存储在同一个服务器上,不利于数据的分散,这也是关系型数据库不擅长大数据写入处理的原因卷。相反,NoSQL数据库本来就不支持Join处理,而且每个数据都是独立设计的,所以很容易将数据分布在多台服务器上,从而减少了每台服务器上的数据量。即使要写入大量的数据,也变得更加容易,读取数据当然也一样容易。
典型的 NoSQL 数据库
瞬态键值存储(,Redis),持久键值存储(ROMA,Redis),面向文档的数据库(,),面向列的数据库(,HBase)
一、 键值对存储
它的数据以键值的形式存储。虽然速度很快,但基本上只能通过key的完全一致的查询来获取数据。根据数据的保存方式,可以分为临时的、永久的和两者兼有。带三个。
(1)临时
所谓临时是指数据可能会丢失,所有数据都保存在内存中,所以保存和读取的速度非常快,但是当它停止时,数据就不存在了。由于数据存储在内存中,超出内存容量的数据无法被操作,旧数据会丢失。得出结论:
. 将数据保存在内存中
. 可以进行非常快速的保存和读取处理
. 数据可能会丢失
(2)永久
所谓永久是指数据不会丢失。这里的key-value存储就是将数据保存在硬盘上。与临时相比,由于不可避免的对硬盘的IO操作,在性能上还是有差距的,但数据不会丢失是它最大的优势。得出结论:
. 将数据保存在硬盘上
. 可以进行非常快速的保存和读取处理(但没有可比性)
. 数据不会丢失
(3) 两者
Redis 属于这一类。Redis 有点特别,既有临时的,也有永久的。Redis首先将数据保存在内存中,当满足一定条件时将数据写入硬盘(默认15分钟1次以上,5分钟10次以上,1分钟10000次以上)。既保证了内存中数据的处理速度,又保证了数据写入硬盘的持久性。这种类型的数据库特别适合处理数组类型的数据。得出结论:
. 在内存和硬盘上同时存储数据
. 可以进行非常快速的保存和读取处理
. 保存在硬盘上的数据不会消失(可以恢复)
. 适合处理数组类型的数据
二、面向文档的数据库
,属于这种类型,它们是 NoSQL 数据库,但不同于键值存储。
(1) 没有定义表结构
即使不定义表结构,也可以像定义表结构一样使用,也省去了更改表结构的麻烦。
(2)可以使用复杂的查询条件
与键值存储不同,面向文档的数据库可以通过复杂的查询条件获取数据。虽然它们不具备事务处理、Join等关系型数据库的处理能力,但基本可以实现除初始处理以外的其他处理。.
三、 面向列的数据库
,HBae,属于这种类型。由于近年来数据量的爆炸式增长,这种类型的 NoSQL 数据库尤其具有吸引力。
普通关系型数据库以行为单位存储数据,擅长以行为单位进行读入处理,如特定条件下数据的获取。因此,关系数据库也称为面向行的数据库。相比之下,面向列的数据库按列存储数据,擅长按列读取数据。
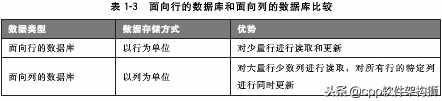
面向列的数据库具有可扩展性,即使数据增加,也不会降低相应的处理速度(尤其是写入速度),所以主要用于需要处理大量数据的时候。此外,它作为批处理程序更新大量数据的内存也非常有用。但是,由于面向列的数据库与目前对数据库存储的思考方式有很大不同,因此应用起来非常困难。
总结:关系型数据库和NoSQL数据库不是对立的而是互补的,即通常使用关系型数据库,适合NoSQL的时候使用NoSQL数据库,这样NoSQL数据库就可以弥补关系型数据库的不足。