8.2-无监督学习-线性降维
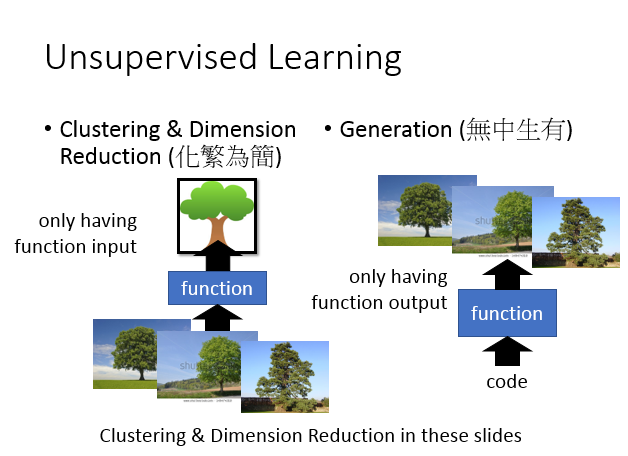
我把 分为两种,一种做的事情叫做“化繁为简”,它可以分为两种:一种是,一种是 。所谓的“化繁为简”的意思:现在有很多种不同的input,比如说:你现在找一个,它可以input看起来像树的东西,都是抽象的树,把本来比较复杂的input变成比较简单的。那在做 的时候,你只会有的其中一边。比如说:我们要找一个要把所有的树都变成抽象的树,但是你所拥有的train data就只有一大堆的image(各种不同的image),你不知道它的应该是要长什么样子。
那另外一个 可以做,也就是无中生有,我们要找一个,你随机给这个一个input(输入一个数字1,然后一棵树;输入数字2,然后另外一棵树)。在这个task里面你要找一个可以画图的,你只有这个的,但是你没有这个的input。你这只有一大堆的image,但是你不知道要输入什么样的code才会得到这些image。这张投影片我们先focus在 这件事上,而且我们只focus在 上。
一、聚类
那我们现在来说,什么是呢?就是说:假设有一大堆的image,然后你就把它们分成一类一类的。之后你就可以说:这边所有的image都属于,这边都属于,这边都属于。有些不同的image用同一个来表示,就可以做到“化繁为简”这件事。那这边的问题是:要到底有几个,这个没有好的方法,就跟 要有几层一样。但是你不能太多,这张有9张image,就有9个 ,这样做跟没做是一样的。把全部的image放在一个里,这跟没做是一样的。要怎样选择适当的,这个你要的来决定它
K-means
那在方法里面,最常用的叫做k-means。我们有一大堆的data,他们都是(x1,…xNx1,…xN),一个xx就代表一张image ,我们要把它做成K个。怎样做呢?我们要先找这些的。(假设这边xx的用来表示的话,这边的也都是一样长度的)有K个就需要有K个。那初始的咋样来呢,你可以从你的train data里面随机找K个xx出来,就是你的k个。
接下里,你要对所有在train data 中的xx,都做以下的事情:你决定说,现在的每一个xx属于1到K中的哪一个。现在假设xx跟第i个class 最接近的话,那xx就属于c^ici,那我们用一个 value(上标n,下标i)b^来代表说第n个xx有没有属于第i个class,如果第n个x属于第i个class的话,它的value就是1,反之就是0.接下来,你要你的,方法也是很直觉的(假设你要第i个 ,你就把所有属于第i个的x通通拿出来做平均,你就得到第i个的,然后你要反复的做)
只所以在 的时候,你会想到直接从你的里面去挑K个xx做,有一个很重要的原因是假设你是纯粹随机的(不是从里面挑的),你很有可能在第一次这个xx的时候,就没有任何一个x和某一个很像,或者某个没有一个xx,
然后你的时候纯粹就是无用功,所以最好从里面选取K个xx作为 。
层次聚类( )
那有另外一种方法叫做 (HAC)(层级聚合聚类),那这个方法是先建一个tree。假设你现在有5个,你想要把它做,那你先做一个tree ,咋样来建这个tree 呢?你把这5个两两去算它的相似度,然后挑最相似的那个pair出来。假设最相似的那个pair是第一个和第二个 merge起来再平均,得到一个新的,这个代表第一个和第二个。现在只剩下四笔data了,然后两两再算相似度,发现说最后两笔是最像的,再把他们merge 起来。得到另外一笔data。现在只剩下三笔data了,然后两两算他们的,发现黄色这个和中间这个最像,然后再把他们平均起来,最后发现只剩红色跟绿色,在把它们平均起来,得到这个tree 的root。你就根据这五笔data他们之间的相似度,就建立出一个tree ,这只是建立一个tree ,这个tree 告诉我们说:哪些是比较像的。比较早分枝代表比较不像的。
接下来你要做,你要决定在这个tree 上面切一刀(切在图上蓝色的线),你如果切这个地方的时候,那你就把你的五笔data变成是三个。如果你这一刀切在红色的那部分,就变成了二个,如果你这一刀切在绿色这一部分,就变成了四个。这个就是HAC的做法
HAC跟刚才K-means最大的差别就是:你如果决定你的的数目,在k-means里面你要决定K value是多少,有时候你不知道有多少不容易想,你可以换成HAC,好处就是你现在不决定有多少,而是决定你要切在这个 tree 的哪里。
二、分布式表示( )
光只做是非常卡的,在做的时候,我们就是"以偏概全"这个就好像说:“念能力”有分成六大类,每一个人都要被成这其中的一类。要咋样决定它是属于哪一类呢?拿一杯水看看它有什么反应,就成哪一类。比如说:水满出来了就是强化系,所以小傑是强化系。这样子把每一个人都某一个系是不够的,太过粗糙的。像就有说:小傑其实是接近放出系的强化系能力的念能力者。如果你只是说它是强化系的,这是loss掉很多的,你应该这样表示小傑,应该说:强化系是0.7,放出系是0.25,强化系是跟变化系是比较接近的,所以有强化系就有一部分的变化系的能力,其他系的能力为0。所以你应该要用一个来表示你的xx,那这个每一个就代表了某一种特值,那这件事就叫做: 。
如果原来你的xx是一个非常high 的东西,比如说image,你现在用它的特值来描述,它就会从比较高维的空间变成比较低维的空间。那这件事情就被叫做: 。这是一样的事情,只是不同的称呼而已。
三、降维( )
3.1 降维样例
那从另外一个角度来看:为什么 可能是有用的。举例来说:假设你的data分布是这样的(在3D里面像螺旋的样子),但是用3D空间来描述这些data其实是很浪费的,其实你从资源就可以说:你把这个类似地毯卷起来的东西把它摊开就变成这样(右边的图)。所以你只需要在2D的空间就可以描述这个3D的,你根本不需要把这个问题放到这个3D来解,这是把问题复杂化,其实你可以在2D就可以做这个task
我们来举一个具体的例子:比如说我们考虑MNIST,在MNIST里面,每一个input digit都是用28*来描述它。但是多数28 *的你把它转成一个image看起来不像一个数字。你 一个28 *转成一个image,可以是这样的(数字旁边的图),它看起来根本就不不像数字。所以在这28 *28维空间里面 。digit这个其实是很少的,所以你要描述一个digit,你根本就不需要用到28 *28维,你要描述一个digit,你要的远比28 *28维少。
我们举一个很极端的例子:比如说这里有一堆3,这堆3如果你是从pixel来看待的话,你要用28*28维来描述一个image,然后实际上这些3只需要一个维度就可以来表示了。为什么呢?因为这些3就只是说:把原来的3放在这就是中间这张image,右转10度就是这张,右转2度变它,左转10、20度。所以你唯一要记录的只有今天这张image它是左转多少度右转多少度,你就可以知道说它在维的空间里面应该长什么样子。你只需要抓重这个重点(角度的变化),你就可以知道28维空间中的变化,所以你只需要一维就可以描述这些image
那怎么做 呢?在做 的时候,我们要做的事情就是找一个,这个的input是一个 x,是另外一个 z。但是因为是 ,所以你这个 z这个要比input这个x还要小,这样才是在做 。
3.2 特征选择( )
在做 里面最简单是 ,这个方法是:你把你的data分布拿出来看一下,本来在二维的平面上,但是你发现都集中在这里,这个没什么用,把它拿掉就只有,你就等于做到 这件事了。这个方法不见得有用,因为有很多时候,你的case是:你任何一个都不能拿掉。
3.3 主成分分析( )
另外一个常见的方法叫做 (PCA),PCA做的事情就是:这个是一个很简单的 ,这个input x跟这个 z之间的关系就是一个 ,你把这个x乘上一个 w,你就得到它的 z。现在要做的事情就是:根据一大堆的x(我们现在不知道z长什么样子)我们要把w找出来
接下来我们来介绍一下PCA,我们刚才讲过PCA要做的事情就是找这个W(z=Wx),这个W咋样找呢?假设我们现在考虑一个比较简单的case,我们考虑一个one 的case。我们现在假设只要把我们的data 到一维的空间上,也就是z是一个scale,w其实就是一个row。那我们就用w1w1来表示W的第一个row,把x跟w1w1做内积就得到了z_1z1。接下来我们要问的问题是:我们要找的这个W1W1,应该要长什么样子。我们先假设w1w1的长度是1(这个假设是有必要的,等下你会更清楚我们为什么要这个假设)如果的长度是1的话,那w1w1跟x做内积得到的z_1z1意味着:w跟x是高维空间中的一个点,w1w1是高维空间中的,z_1z1就是x在w1w1上的投影。所以我们现在做的事情就是把一堆x通过w1w1变成z_1z1(得到一堆z_1z1,每个x都变成z_1z1)那现在的问题就是这个w1w1应该长什么样子呢,怎么选取这个w1w1呢?
举例来说,这个x的分布(图中蓝色的点,每一个点代表宝可梦),这个分布的横坐标是攻击力,纵坐标是防御力。那今天我要把二维投影到一维,我应该要选什么样的w1w1呢?我可以选w1w1指向这个方向(红色的箭头),也可以选w1w1指向那个方向(橙色的箭头),我选不同的方向得到的结果会是不一样的。那你总得给我们一个目标,我们才能知道要选咋样的w1w1。我们的目标是这样的:我们希望选一个w^1w1,它经过以后得到这些z_1z1的分布是越大越好,也就是我们不希望说通过这个以后所有的点通通挤在一起,把本来的data point跟data point之间的奇异度拿掉了。我们是希望说:经过以后,不同的data point他们之间的区别我们仍然是可以看的出来,所以找一个方向它可以让后的是越大越好。如果我们看这个例子的话,你就会觉得说:如果是选这个方向的话(红色箭头),经过以后,可能会分布在这个range(large );如果选这个方向的话(橙色箭头),那么你的点可以是这个range(small )。所以你要选择w1w1的时候,你可能会选择w1w1的方向是large 这个方向。从这个图上,你可以看出w^1w1其实是代表宝可梦的强度,宝可梦可能有一个代表它的强度,这个隐藏的同时影响了它的防御力跟攻击力,所以防御力跟攻击力是会同时上升的。
数学推导
那我们要用来表示的话,你就会说:我们现在要去的对象是z_1z1的,z_1z1的就是 over所有的z_1z1,然后z_1z1减去(\bar z_1)^2(zˉ1)2。
假设你知道咋样来做(等一下来讲怎么做),你找到一个w1w1,你就可以让z_1z1最大,然后就结束了。你现在不只是想要投影到一维,你想要投影到更多维(二维)。现在你想要投影到二维的平面的时候,这时候你就把x跟另外一个w2w2做内积,w1,w2w1,w2就是W的第一个row和第二个row。那我们咋样来找w2w2呢?跟刚才找z_1z1一样,首先假设w2w2的长度为1,z_2z2的分布也是越大越好,但是你只是要让z_2z2的越大越好,这样你找出不就 是w1w1吗,但是你w1w1刚才已经找过了,这样的话你就等于什么事都没有做。所以你要再加一个,刚才已经找到w1w1了,这次要w2w2跟w^1w1是垂直的(w1 * w2=0w1∗w2=0)。你先把w1w1,再找w2w2,等等,这就看你要到几维了。(要几维是你自己要决定的)。把w1,w^2,…w1,w2,…排起来成W就结束了。
这个W是一个 (正交矩阵),这时候,你看它的row(w1,w2w1,w2)是,w1,w2w1,w2的长度都是1,所以它是一个 。
接下里的问题就是怎样来找w1,w2w1,w2(咋样来解这个问题),这个解法是蛮容易的。经典的方法:z_1z1等于w^1xw1x,z_1z1的平均值 (公式里面少除n),也就是 ,w1w1跟data point无关,可以提出来变为先 over x在w^1 \sum xw1∑x得到w^1w1跟\bar{x}xˉ。接下来我们要的对象是z_1z1的(\sum_{z_1} (z_1-\bar{z_1})^2∑z1(z1−z1ˉ)2)公式整理为\sum( w1(x-\bar{x}))2∑(w1(x−xˉ))2。可以把这个式子做一个转化:w^1w1是一个,x- \bar{x}x−xˉ是一个。假设w^1w1是a,x-\bar{x}x−xˉ是b,可以写成a的乘 b的平方,可以写成a的 乘以b再乘以a的乘以b,可以写成a的乘以b再乘以a的乘以b的(a的乘以b是一个scale):找一个w1w1,它可以(w1)TSw1(w1)TSw1(S=Cov(x)S=Cov(x))。但这个是要有,如果没有的话,这个问题会有无聊的,把每个值都变无穷大,这样就结束了,所以这个问题是要有。这个问题是:w^2w2的L-Norm等于1
有了这些以后呢,我们要解这个问题。S是 ,又是半正定。也就是说所有的**(特征值)**都是non-(比较困惑的话,可以去看李老师的现代课)。这个问题的就是:w^1w1是 的。它不只是一个,它是对应到最大的\λ那一个。这个就是结论
中间的过程是:首先我要用 ( ),式子是:g(w1)=(w1)TSw1-\alpha ((w1)Tw1-1)g(w1)=(w1)TSw1−α((w1)Tw1−1),接下来你把这个g对所有的w做偏微分(w是一个,有很多的),令这个式子通通等于0(偏微分),整理一下你会得到这个式子:Sw1-\alpha w1=0Sw1−αw1=0。这个式子告诉我们说:是满足这个式子,如果写成Sw1=\alpha w1Sw1=αw1的话,w1w1就是S的一个。但是S的有很多,而且你还可以找到的长度等于1。所以你接下来要做的事情是,看哪一个带到这个式子里面((w1)TSw1(w1)TSw1)可以(w1)TSw1(w1)TSw1。整理一下变为\alpha (w1)Tw1α(w1)Tw1,得到结果为\alphaα,谁可以让这个\alphaα最大呢?答案是:w1w1是对应到 的时最大,这个\alphaα是最大的 \ _1λ1.

那我要找w2w2的话,我们要解是这样的:max((w2)TSw2)max((w2)TSw2)其中 $(w2)Tw^2=1 $ (w2)Ts1=0(w2)Ts1=0。我们要根据w2w2投影以后的。结论是:w^2w2也是 S的一个,然后它对应到2^{nd}2nd \ _2λ2。那我们现在来解它:你先写一个 g,里包括了你要的对象,还包括了两个,分别乘以\alpha,\betaα,β。接下来你对所有的参数做偏微分(w2w2所有的)。做完以后你得到这个式子(Sw2-\alpha w^2-\beta w1=0Sw2−αw2−βw1=0),然后坐左同时乘以w1w1的(乘以w1w1的以后,会出现(w1)Tw1(w1)Tw1会等于1,(w1)TW2(w1)TW2等于0),整理一下等于((w1)TSw2)T((w1)TSw2)T(scale),在整理一下得到(w{2})TSw1(w2)TSw1。我们已经知道w^1w1是S的,而且它对应到最大的 λ 1 ( ( S w 1 = λ w 1 ) 。从这边我们得到 ) 。从这边我们得到 β 等于 0 ,所以剩下的等于 0 ,所以剩下的 S w 2 − α w 2 = 0 ,然后得出,然后得出 S w 2 = α w 2 。。 w 2 \ ((Sw^1=\ w^1)。从这边我们得到)。从这边我们得到\beta等于0,所以剩下的等于0,所以剩下的Sw^2- \alpha w^2=0,然后得出,然后得出Sw^2=\alpha w^2。。w^2 λ1((Sw1=λw1)。从这边我们得到)。从这边我们得到β等于0,所以剩下的等于0,所以剩下的Sw2−αw2=0,然后得出,然后得出Sw2=αw2。。w2是一个,但是它是哪一个呢?它是第二大。
z =Wx,这里神奇的地方就是:z的是 (对角矩阵),也就是说如果我们今天做PCA,你原来的data 可能是左边这张图,做完PCA以后,你会做(解相关),你会让你不同的间的是0.也就是说你算z这个 的话,会发现它是( ),这样做是有好处的。假设你PCA得到的(z),这个新的是要其他的model用的,你的model假设说是一个 model,你用来描述某一个class的,而你在做假设的时候,你假设说input data它的是,你假设不同的之间没有,这样可以减少你的参数量。
你把原来的input data做PCA以后,再丢给其他的model,其它的model就可以假设现在的input data它的之间没有。所以它就可以用简单的model处理你的input data,这样就可以避免的情形。
这件事情怎么说明呢?z的是z-\bar{z}z−zˉ乘以(z-\bar{z})T=WSWT(z−zˉ)T=WSWT,s=Cov(x),把S乘进w1,…wkw1,…wk变成[Sw1,Sw2,…Swk][Sw1,Sw2,…Swk],w1w1是S的,\λ是,所以[Sw1,Sw2,…Swk][Sw1,Sw2,…Swk],w1w1变成[\ w^1,\ w^2,…\ w^k,][λw1,λw2,…λwk,],然后把W乘进去,然后就变成了[\ W w^1,\ Ww^2,…\ Wwk,][λWw1,λWw2,…λWwk,]。(w1w1是W的第一个row)W乘以w^1w1等于e_1e1(w_1,…,w_nw1,…,wn是相互正交),e_1e1就是第一维是1,其它都是0,这个东西就是 。
PCA,第一个找出的w^1w1是 对应到最大的,然后找出的w^2w2就是对应到第二大的,以此类推。有一个证明告诉你说:这么做的话,每次投影的时候都可以让最大。
主成分分析的另一个角度
我们从更清楚的角度来看PCA,你就会知道PCA到底在做什么。假设我们考虑的是手写的数字,我们知道这些数字其实是一些basic 所组成的。这些basic 可能就代表笔画。举例来说:人类所手写的数字就是这些basic 所组成的,有斜的直线,横的直线,有比较长的直线,然后还有小圈,大圈等等,这些basic 加起来就可以得到一个数字。这些basic 写做u1,u2,…u^5u1,u2,…u5,这些basic 其实就是一个一个的。假设我们现在考虑的是mnist,mnist一张*,也就是28 *28维的。这些其实就是28 *28维的,把这些加起来以后,你所得到的就代表了一个。如果把它写成的话就是:x\ c_1u1+c_2u2+…c_kuk+\bar{x}x≈c1u1+c2u2+…ckuk+xˉ,x代表一张image里面的pixel,x等于加上这个,一直加到,再加上\bar{x}xˉ,\bar{x}xˉ是所有image的平均。所以每一张image就是有一堆的 再加上它平均所组成的。
举例来说:7是这三个加起来的结果,假设7就是x的话,c_1=1,c_2=0,c_3=1,c_4=0,c_5=1c1=1,c2=0,c3=1,c4=0,c5=1,你可以用c_1,c_2,…c_kc1,c2,…ck来表示一张image。假设比pixel的数目少的话,那么这个描述是比较有效的。7是1倍的u1u1,1倍u2u2,1倍的u^5u5所组成的,所以7是一个,它的第一维,第三维,第5维是1.
所以现在把\bar{x}xˉ移到左边,x减掉所以image的平均等于一堆 ,这些 写作\hat{x}x^,那现在假设我们不知道这些 是什么,不知道u1u1到ukuk的长什么样子。那我们咋样找K 出来呢?我们要做的事情就是:我们要去找K 使得\hat{x}x^跟x-\bar{x}x−xˉ越接近越好,他们的差用 error(重建误差)来描述。接下来我们要做事情就是:找K 个可以这个 error。
在PCA中我们想说:我们要找一个 W,x乘以 W就得到了z,把W的每一个row写出来就是[w_1,w_2,…,w_k][w1,w2,…,wk],x乘上一个[(w_1)T,(w_2)T,…(w_k)^T][(w1)T,(w2)T,…(wk)T],以此类推。那么说:是[w_1,w_2,…,w_k][w1,w2,…,wk]是 的,事实上你要解这个式子L=mi_n(u1,…uk)\sum \left | (x-\bar{x}) -(\sum_{k=1}{k}c_kuk)\right |L=min(u1,…uk)∑∥∥∥∥(x−xˉ)−(∑k=)∥∥∥∥,找出u1,…uku1,…uk。由PCA找出的这个解w1,…wkw1,…wk就是可以让L最小化
我们有一大堆的x,现在假设有一个x_1x1,这个x_1x1减去\bar{x}xˉ等于u^1u1乘以 ,c上标1下标1(下标1代表说:它是u1u1的,上标1代表说:x1x1的u^ ),x^1-\bar{x} \ ++…x1−xˉ≈c11u1+c21u2+…
x-\bar{x}x−xˉ是一个(把这个拿出来),u1,u2…u1,u2…是一排(把它排起来,排起来就是一个),的数目是K个,把这些 排成一排变成一个,乘以变成另一个。我们不只是有一笔data,x2-\bar{x}x2−xˉ是另外一个黄色的,这个(c_12,c_2^2,…c12,c22,…)乘以 u^2u2等于另一个黄色的,依次类推。
那我们把所有的data用这个式子来表示的话,这样就会得到一个,这个的等于data的数目(你有1万笔data,=10000)。现在\left{\begin{} … &… \ u^1 & u^2 \ …& … \end{}\right.⎩⎪⎨⎪⎧…u1…u2…乘以这个 \left{\begin{} c_1^1 &c_1^2 \ c_2^1 & c_2^2 \ …& … \end{}\right.⎩⎪⎨⎪⎧……跟这个越接近越好,所以你要左边两个跟右边这个之间的差距是会被的,也就是说:用SVD提供给我们的拆解方法,拆成这是三个相乘后,跟左边的是最接近的。
奇异值分解
那要咋样来解这个问题呢?加入你有学过大一现代化,你就应该知道该咋样来解(可以参考李宏毅老师现代的课程)。每一个 X,你可以用SVD把它拆成一个 U(m *k)乘上一个 \sum∑(k *k)乘上 V(k *n)。这个 U就是\left{\begin{} … &… \ u^1 & u^2 \ …& … \end{}\right.⎩⎪⎨⎪⎧…u1…u2…,这个\sum∑V就是\left{\begin{} c_1^1 &c_1^2 \ c_2^1 & c_2^2 \ …& … \end{}\right.⎩⎪⎨⎪⎧……。
如果我们今天用SVD将X拆成这三个相乘,那右边三个相乘的结果是最接近左边这个的,那解出来的结果是什么样呢?其中U这个的 K 其实就是一组 ,这组 是XX^TXXT的,U总共有K个 ,这K 个 对应到XX^TXXT最大的k个的。
你会发现,这个XX^TXXT就是 ,PCA之前找出的W就是 的。而我们这边说做SVD,解出来U的每个就是 的,所以这个U得出的解就是PCA得到的解。所以我们说:PCA做的事情就是:你找出来的那些W其实就是。
主成分分析和神经网络
我们现在已经知道从PCA找出的w1,…wKw1,…wK就是k个,…uKu1,…uK。我们现在有一个根据 的结果叫做\hat{x}x`(`\sum_{k=1}{K}c_kwk∑k=)。我们希望\hat{x}x跟x-\bar{x}x−xˉ的差值越小越好,你要 error。那我们现在已经根据SVD找出这个W了,那这个c_kck的值是到底多少呢?这个c_kck是每一个image都有自己的c_kck,这个c_kck就每个image各自找就好。如果现在要用c_1,…ckc1,…ck对wkwk做 。这个c_k=(x-\bar{x})wkck=(x−xˉ)wk,找一组c_kck可以\hat{x},(x-\bar{x})x,(x−xˉ)
做的事情你可以想成用 来表示它,假设我们的x-\bar{x}x−xˉ就是一个(这边写做三维的),假设现在只有2个(k=2),那我们先算出c_1,c_2c1,c2,c_1=(x-\bar{x})c1=(x−xˉ)(x-\bar{x}x−xˉ)的每一个乘上w^1w1的每一个,接下来你就得到了c_1c1。(x-\bar{x}x−xˉ是 的input,c_1c1是一个( ),w1_1,w1_2,w^,w21,w31是,)。c_1c1
乘以w1w1(c_1c1乘上w_1w1的第一维()得到一个value,乘上w_1w1的第二维()得到一个value,乘上w_1w1的第三维()得到一个value)。接下来再算一下c_2c2,c_2c2乘以w2w2的结果和之前的加起来就是最后的,\hat{x_1},\hat{x_2},\hat{x_3}x1,x2,x3就是\hat{x}x^。
接下来就是 error,我们要\hat{x}x跟x-\bar{x}x−xˉ越接近越好(也就是这个跟x-\hat{x}x−x越接近越好),那你可以发现说PCA可以表示成一个 ,这个 只有一个 layer,这个 layer是 。那现在我们train 这个 ,是要input一个东西得到,这个input跟越接近越好。这个东西就叫做
这边就有一个问题,假设我们现在这个,不是用PCA的方法去找出w1,w2,…w^kw1,w2,…wk。而是兜一个 ,我们要 error,然后用 去train得到的,那就觉得你得到的结果会跟PCA得到的结果一样吗?这其实是会一样的( 没有办法保证是垂直的,你会得到另外一组解)。所以在的情况下,或许你就想要用PCA来找这个WW比较快的,你用 是比较麻烦的。但是用 的好处是:可以deep。
缺点
PCA有一些很明显的弱点,一个是:它是,今天加入给它一大堆点没有label。假设你要把它到一维上,PCA可以找一个可以让data 最大的那个,在这个case中,就把它到这一维上(红色箭头))。有一种可能是,这两组data point它们分别代表了两个class,如果你用PCA来做 的话,你就会使得蓝色跟橙色的class被meger在一起,这样就无法分别了。
这时候你要怎么办呢?这时候你要引入label data,LDA是考虑label data考虑降维的方法,不过它是,所以这个不是我们要讲的对象。
另外一个PCA的弱点是,我们刚开始举得例子会说。我们刚开始举的例子说:这边有一堆点的分布是像S型的,我们期待说:做 后可以把这个S型曲面可以把它拉直,这件事情对PCA来说是做不到的。如果这个S型曲面做PCA的话,它是这样子的(如图),就像打扁一样,而不是把它拉开,拉开这件事情PCA是办不到的。等下我们会讲non-
应用实例
接下来,我们把PCA用在一些实际的问题上。比如说:用它来分析宝可梦的data,宝可梦总共有800种宝可梦,每个宝可梦可以用6个来表示,分别是:生命值,攻击力,防御力,特殊攻击力,特殊防御力,速度。所以每一个宝可梦就是一个6维的,我们现在用PCA来分析它。
在PCA中有个常问的问题:我需要有多少个,要把它到一维,二维还是三维…。要多少个就好像是 要几个layer,每个layer要有几个一样,所以这是你要自己决定的。
那一个常见的方法是这样的:我们去计算每一个 的\λ(每一个 就是一个,一个对应到一个 \λ)。这个代表 去做 的时候,在 的那个上它的有多大(就是\λ)。
今天这个宝可梦的data总共有6维,所以 是有6维。你可以找出6个,找出6个。现在我们来计算一下每个的ratio(每个除以6个的总和),得到的结果如图。
可以从这个结果看出来说:第五个和第六个 的作用是比较小的,你用这两个来做的时候出来的是很小的,代表说:现在宝可梦的特性在第五个和第六个 上是没有太多的。所以我们今天要分析宝可梦data的话,感觉只需要前面四个 就好了。
我们实际来分析一下,你做PCA以后得到四个 就是这个样子,每一个 就是一个,每一个宝可梦是用6位的来描述。我们来看每一个 做的事情是什么:如果我们看第一个 ,第一个 每一个都是正的,这个东西其实就代表了宝可梦的强度(如果你要产生一只宝可梦的时候,每一个宝可梦都是由这四个做 ,每一个宝 可梦可以想成是,这六个做 的结果,在选第一个 的时候,你给它的比较大,那这个宝可梦的六维都是强的,所以这第一个 就代表了这一只宝可梦的强度)。第二个 它在防御力的地方是正值,在速度的地方是负值,也就是说这个防御力跟速度是成反比的,你给第二个 一个的时候,你会增加那只宝可梦的防御力但是会减低它的速度。
我们把第一个和第二个 画出来的话,你会发现是这个样子(图上有800个点,每一个点对应到一只宝可梦),但这样我么很难知道每一只宝可梦是什么。
如果我们看第三个和第四个的话,会发现第三个 的特殊防御力是正的,攻击力和生命值是负的,说明是用生命值和攻击力换取特殊防御力的宝可梦。最后一个是:它的HP是正的,攻击力和防御力是负的,也就是说:它是用攻击力和防御力来换取生命力的宝可梦。

我们拿它来做手写数字辨识的话,我们可以把每一张数字都拆成乘以,加上另外一个乘以,每一张是一张image(28* 28的)。我们现在来画前的话(PCA),你得到的结果是这样子的(如图所示),你用这些做 ,你就得到所有的digit(0-9),所以这些就叫做Eigen (这些其实都是 的)
如果我们做人脸辨识的话,得到的结果是这样子的。找它们前30的pixel ,叫做Eigen-face。你把这些脸做 以后就可以得到所有的脸。但是这边跟我们预期的有些是不一样的,这是不是有bug啊。因为我们PCA找出来的是,我们把很多 做 以后它会变成face。但是现在我们找出来的不是,我们找出来的每一个图都几乎是完整的脸。
为什么会这样呢?其实你仔细想PCA的特性,你会发现说,会得到这个结果是可能的。因为在PCA里面,它可以是任何值(可以是正的,也可以是负的),所以当我们用pixel 组成一张image的时候,你可以把这个相加,也可以相减。所以这会导致你找出的不见得是一个图的basic的东西。
假设我要画一个9,那我可以先画一个8,把下面的圈圈减掉,然后把一杠加上去(你可以先画一个复杂的图,再把多于的减掉)。这些其实不见得是笔画的东西,若你要得到类似笔画的东西,你要用Non- (NMF)。在Non- 里面,我们刚才说:PCA它可以看做是对 X做SVD,SVD是 的技术,它分解出来的两个的值可以是正的,也可以是负的。那现在你要用NMF的话,我们会强迫所有的 都是正的。是正的好处就是,现在一张image必须由叠加得到(你不能说:我先画一个很复杂的东西,再把一些东西去掉,得到一个digit)。如果你用PCA的话,你的每一回都不见得是正的,会有一些负值,负值你是不知道要该怎么处理的。
用NMF的话值都是正的,那些自然会形成一张image。
在MNIST用NMF的话,你找出来的那些piexl 它就会清楚很多,你会发现你找出来的每个东西都是笔画了。
如果你要看脸的话,你就会发现说:它长的是这个样子,它比较像是脸的一些部分。
3.4 矩阵分解( )
假设我们现在做一个调查,调查每个人买公仔的数目。ABCDE代表五个人,A有5个春日,B有4个,C有1个,D有1个,E有0个。A有炮姐3个,B有3个,C有1个,D有1个,E有1个。A有姐寺0个,B有0个,C有0个,D有4个,E有5个。A有小唯1个,B有1个,C有5个,D有4个,E有4个。你会发现说:在这个上面,每一个table里面的block并不是随机出现的。如果有两个公仔的人,那是因为每个人跟角色的背后是有一些特性的(有一些来操控这些特性)
这些动漫仔会分为两种,有一种是萌傲娇的,有一种是萌天然呆的,每个人就是在萌傲娇和萌天然这个平面上一个点。那么A可能是偏萌傲娇的,每一个角色有傲娇属性也可能有呆萌属性,所以每个角色就是就是平面上的一个点,所以每个角色都可以用来描述它。如果某一个人萌的属性跟某一个角色它本身所具有的属性是match的话(它们背后的很像),那这个人就会买这个公仔。
A,B,C它们的是左边这样子的,A是萌傲娇的,B也是萌傲娇的(没有A那么强),C是萌天然呆的,每一个动漫人物角色后面也都有傲娇,天然呆这两种属性。如果它们背后属性是match的话,那这个人就会买这个公仔。世界操控的逻辑是这样子的,但是这些(萌傲娇还是萌天然呆)这些是没有办法直接被观察的。
但是这些(萌傲娇还是萌天然呆)这些是没有办法直接被观察的,因为没有人去关心他心里是想什么,你也没有办法说:每一个动漫人物它背后的属性是什么,这个是没有办法直接观察到的。
我们有的是动漫人物跟手上有的公仔的数目,我们要根据这个关系论出每一个人跟每一个动漫人物背后的(每个人背后都有一个二维的,代表他萌傲娇,萌天然呆的程度),每个人物的背后也都有一个,代表他傲娇的属性和天然呆的属性。我们知道每个人手上有公仔的数目,把它合起来看做是一个 X。这个 X的row的数目是的数目,它的的数目是动漫角色的数目。
那我们现在做一个假设,这个里面的它都来自于两个的inner 。为什么A有5个春日的公仔呢?是因为rArA跟r1r1的inner 很大(它的inner 是5,所以有5个春日的公仔),如 果rArA跟r1r1的inner 是4,那B就会有4个炮姐的公仔,以此类推。
如果这件事你用数学来表示的话,我们可以写成这样子。把rArA跟rBrB排成一排,把r1r1到r4r4排起来。这个K是 的数目,这个东西我们是没有办法知道的(我们把人分成萌傲娇萌天然呆,这样是不精确的分析方式。如果我们有更多data的话,我们应该更准确的知道有多少,要多少这些必须是试出来,这个就行 或者 的层数一样,你要事先决定好)我们就假设说现在 的数目是K,你把它当成 row,就是一个M*K的。如果你把r1r1到r4r4当做,就是K *N 的。如果你这个M *K跟K *N的乘起来就是M *N的。那它的每一个就是(最上角的就是rArA乘以r1r1,第一个row第二个是rArA乘以r2r2,以此类推) X。那这样的话,我们做的事情就是找一组rArA到rErE,找一组r1r1到r4r4,把这两个相乘以后,跟左边这个 X越接近越好( error)。
这个就可以用刚才的SVD来解,你可能说SVD不是有三个解吗?这时候你看你是要把\sum∑并到左边还是右边,把这个 X拆成两个,然后 error。
FM推荐系统中的应用
但是有时候你会遇到这个问题,就是一些是的(不知道这个)。比如说:你不直道ABC手上有没有小叶撕的公仔,有可能在他所在的地区没有发行,那这个table只能写?
假设在table上有一些是问号的话,怎么办呢?你用刚才SVD的方法就会有点卡。那在这个上有的value的话,我们还是可以做的,我们就用 的方法来做。我们来写一个loss L=\sum {(i,j)}(ri*rj-n{ij})^2L=∑(i,j)(ri∗rj−nij)2(你要i这个人乘以j这个角色的inner 跟它购买的数量n_{ij}nij是越接近越好)重点是说:我们在 over这些的时候,我可以避开这些 data(我们在 overi,j的时候,如果值没有,我就不算它,我们只算有定义值的部分)
那我们就用 来实际做一下 ,我们假设 的数目为2。那A到E都会对应到二维的,那每一个角色都会对应到一个(属性)。所以我们把它在两个维度里面比较大的维度挑出来的话,你就会发现说:A,B是萌同一种属性,C,D,E是萌同一种属性,1,2有同样的属性,3,4有同样的属性。你没有办法说每一个属性分别都代表着什么(不知道那个维度代表着天然呆或者傲娇)。
你需要先找出这些 去分析它的结果,你就可以知道说(因为我们事先已经知道姐寺跟小唯是有天然呆属性)第一个维度代表天然呆的属性,第二个维度是傲娇的属性。有了这些data以后,你就可以预测你的 value。
如果我们已经知道r3r3,rArA,我们知道一个会购买公仔的数量其实是动漫角色背后的 跟人背后的 做inner 的结果。那我们把r3r3跟rArA做inner 之后,你就可以预测说这个人会买多少公仔。
刚才那个model可以做的更精致一点,我们刚才说:A背后的 r^ArA跟1背后的 得到的结果就是table上面的数值。但是事实上可能还会有别的因素会操控它的数值,所以更精确的写法是:rArA跟r^1r1的inner 加上某一个跟A有关的,再加上跟1有关的scale b_1b1其实才等于5。b_AbA代表说:A本身有多喜欢买工仔,b_1b1代表说:这个角色它本身会有多想让别人购买(这件事情跟属性是无关的)
所以改一下的式子,改为riri跟rjrj的inner 加上b_ibi,b_jbj,然后你希望这个值跟n_{ij}nij越接近越好,用 来解。(你也可以在loss 后面加上)
MF主题分析的应用
、
有很多的应用,可以应用到topic 上面。如果把刚才讲的 的技术用到topic 上面就叫做 (LSA)。就是把刚才的动漫人物换成文章,把刚才的人换成词汇。table里面的值就是term ,把这个term 乘上一个代表说这个term本身有多重要。
怎样一个term重不重要呢?常用的方式是: (计算每一个词汇在整个paper有多少比率的涵盖这个词汇,假如说,每个词汇,每个都有,那它的 就很小,代表着这个词汇的重要性是低的,假设某个词汇只有某一篇有,那它的 就很大,代表这个词汇的重要性是高的。)
在这个task里面,如果你今天把这个做分解的话,你就会找到每一个背后那个 ,那这边的 是什么呢?可能指的是topic(主题),这个topic有多少是跟财经有关的,有多少是跟政治有关的。跟有比较多的“投资,股票”这样的词汇,那跟就有比较高的可能背后的 是比较偏向“财经”的
topic 的方法多如牛毛,基本的精神是差不多的(有很多各种各样的变化)。常见的是 (PLSA)和 (LDA)。这跟之前在 讲的LDA是完全不一样的东西
3.5 未引入的其他相关方法
这些是一些给大家参考,这边是跟PCA比较有关系的。
的方法多如牛毛,比如说MDS,MDS的特别是:它不需要把每一个data都表示成 ,它要知道 跟 之间的,知道这个,你就可以做 。一般教科书举得例子会说:我现在一堆城市,你不知道咋样把城市描述成,但你知道城市跟城市之间的距离(每一笔data之间的距离),那你就可以画在二维的平面上。其实MDS跟PCA是有一些关系的,如果你用某些特定的来衡量两个data point之间的距离的话,你做MDS就等于做PCA。其实PCA有个特性是:它保留了原来在高维空间中的距离(在高维空间的距离是远的,那么在低维空间中的距离也是远的,在高维空间的距离是近的,那么在低维空间中的距离也是近的)
PCA有几率的版本,叫做 PCA。PCA有非线性的版本,叫做 PCA。CCA是说:你有两种不同的,这时候你想要用CCA。假如说你要做语音辨识,两个(一个是声音讯号,有那个人嘴巴的image(可以看到这个人的唇形,可以读他的唇语))把这两种不同的都做 ,那这个就是CCA。