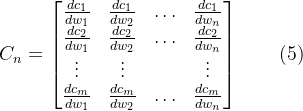2023年的深度学习入门指南(21) - 百川大模型
前面我们用了三节的篇幅介绍了目前最强大的开源模型。这一节我们说一说国产大模型的一个代表,百川大模型。
使用百川大模型
第一步我们先把百川用起来,然后再研究如何训练和其原理如何。
百川的使用非常简单,按照我们前面学习的库的标准用法就可以了。
首先安装依赖库:
pip install transformers
pip install sentencepiece
pip install accelerate
pip install transformers_stream_generator
安装的过程大致是下面这样:
Collecting transformersDownloading transformers-4.31.0-py3-none-any.whl (7.4 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.4/7.4 MB 29.4 MB/s eta 0:00:00
Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from transformers) (3.12.2)
Collecting huggingface-hub<1.0,>=0.14.1 (from transformers)Downloading huggingface_hub-0.16.4-py3-none-any.whl (268 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 268.8/268.8 kB 29.7 MB/s eta 0:00:00
Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.10/dist-packages (from transformers) (1.22.4)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from transformers) (23.1)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.10/dist-packages (from transformers) (6.0.1)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.10/dist-packages (from transformers) (2022.10.31)
Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from transformers) (2.27.1)
Collecting tokenizers!=0.11.3,<0.14,>=0.11.1 (from transformers)Downloading tokenizers-0.13.3-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (7.8 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.8/7.8 MB 65.4 MB/s eta 0:00:00
Collecting safetensors>=0.3.1 (from transformers)Downloading safetensors-0.3.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.3 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.3/1.3 MB 77.2 MB/s eta 0:00:00
Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.10/dist-packages (from transformers) (4.65.0)
Requirement already satisfied: fsspec in /usr/local/lib/python3.10/dist-packages (from huggingface-hub<1.0,>=0.14.1->transformers) (2023.6.0)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.10/dist-packages (from huggingface-hub<1.0,>=0.14.1->transformers) (4.7.1)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (1.26.16)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (2023.5.7)
Requirement already satisfied: charset-normalizer~=2.0.0 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (2.0.12)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (3.4)
Installing collected packages: tokenizers, safetensors, huggingface-hub, transformers
Successfully installed huggingface-hub-0.16.4 safetensors-0.3.1 tokenizers-0.13.3 transformers-4.31.0
Collecting sentencepieceDownloading sentencepiece-0.1.99-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.3 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.3/1.3 MB 11.3 MB/s eta 0:00:00
Installing collected packages: sentencepiece
Successfully installed sentencepiece-0.1.99
Collecting accelerateDownloading accelerate-0.21.0-py3-none-any.whl (244 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 244.2/244.2 kB 5.3 MB/s eta 0:00:00
Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.10/dist-packages (from accelerate) (1.22.4)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from accelerate) (23.1)
Requirement already satisfied: psutil in /usr/local/lib/python3.10/dist-packages (from accelerate) (5.9.5)
Requirement already satisfied: pyyaml in /usr/local/lib/python3.10/dist-packages (from accelerate) (6.0.1)
Requirement already satisfied: torch>=1.10.0 in /usr/local/lib/python3.10/dist-packages (from accelerate) (2.0.1+cu118)
Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (3.12.2)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (4.7.1)
Requirement already satisfied: sympy in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (1.11.1)
Requirement already satisfied: networkx in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (3.1)
Requirement already satisfied: jinja2 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (3.1.2)
Requirement already satisfied: triton==2.0.0 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (2.0.0)
Requirement already satisfied: cmake in /usr/local/lib/python3.10/dist-packages (from triton==2.0.0->torch>=1.10.0->accelerate) (3.25.2)
Requirement already satisfied: lit in /usr/local/lib/python3.10/dist-packages (from triton==2.0.0->torch>=1.10.0->accelerate) (16.0.6)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.10/dist-packages (from jinja2->torch>=1.10.0->accelerate) (2.1.3)
Requirement already satisfied: mpmath>=0.19 in /usr/local/lib/python3.10/dist-packages (from sympy->torch>=1.10.0->accelerate) (1.3.0)
Installing collected packages: accelerate
Successfully installed accelerate-0.21.0
Collecting transformers_stream_generatorDownloading transformers-stream-generator-0.0.4.tar.gz (12 kB)Preparing metadata (setup.py) ... done
Requirement already satisfied: transformers>=4.26.1 in /usr/local/lib/python3.10/dist-packages (from transformers_stream_generator) (4.31.0)
Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from transformers>=4.26.1->transformers_stream_generator) (3.12.2)
Requirement already satisfied: huggingface-hub<1.0,>=0.14.1 in /usr/local/lib/python3.10/dist-packages (from transformers>=4.26.1->transformers_stream_generator) (0.16.4)
Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.10/dist-packages (from transformers>=4.26.1->transformers_stream_generator) (1.22.4)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from transformers>=4.26.1->transformers_stream_generator) (23.1)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.10/dist-packages (from transformers>=4.26.1->transformers_stream_generator) (6.0.1)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.10/dist-packages (from transformers>=4.26.1->transformers_stream_generator) (2022.10.31)
Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from transformers>=4.26.1->transformers_stream_generator) (2.27.1)
Requirement already satisfied: tokenizers!=0.11.3,<0.14,>=0.11.1 in /usr/local/lib/python3.10/dist-packages (from transformers>=4.26.1->transformers_stream_generator) (0.13.3)
Requirement already satisfied: safetensors>=0.3.1 in /usr/local/lib/python3.10/dist-packages (from transformers>=4.26.1->transformers_stream_generator) (0.3.1)
Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.10/dist-packages (from transformers>=4.26.1->transformers_stream_generator) (4.65.0)
Requirement already satisfied: fsspec in /usr/local/lib/python3.10/dist-packages (from huggingface-hub<1.0,>=0.14.1->transformers>=4.26.1->transformers_stream_generator) (2023.6.0)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.10/dist-packages (from huggingface-hub<1.0,>=0.14.1->transformers>=4.26.1->transformers_stream_generator) (4.7.1)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->transformers>=4.26.1->transformers_stream_generator) (1.26.16)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->transformers>=4.26.1->transformers_stream_generator) (2023.5.7)
Requirement already satisfied: charset-normalizer~=2.0.0 in /usr/local/lib/python3.10/dist-packages (from requests->transformers>=4.26.1->transformers_stream_generator) (2.0.12)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->transformers>=4.26.1->transformers_stream_generator) (3.4)
Building wheels for collected packages: transformers_stream_generatorBuilding wheel for transformers_stream_generator (setup.py) ... doneCreated wheel for transformers_stream_generator: filename=transformers_stream_generator-0.0.4-py3-none-any.whl size=12321 sha256=b5b47ad5379c157830d2c3508d20acedd5856f0dd3f88ac3151727d67e3bd8a6Stored in directory: /root/.cache/pip/wheels/47/1d/3c/92d88493ed40c0d9be60a391eb76c9a56e9f9b7542cb789401
Successfully built transformers_stream_generator
Installing collected packages: transformers_stream_generator
Successfully installed transformers_stream_generator-0.0.4
我们先看一个使用7b参数模型的例子。
from transformers import AutoModelForCausalLM, AutoTokenizertokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-7B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-7B", device_map="auto", trust_remote_code=True)
inputs = tokenizer('备周则意怠,常见则不疑', return_tensors='pt')
inputs = inputs.to('cuda:0')
pred = model.generate(**inputs, max_new_tokens=64,repetition_penalty=1.1)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
输出结果如下:
备周则意怠,常见则不疑。阴在阳之内,不在阳之对。太阳,太阴。
《道德经》第五十二章:有物混成,先天地生。寂兮寥兮,独立而不改,周行而不殆,可以为天下母。吾不知其名,字之曰道,强
看来百川是懂三十六计的。
当第一次运行的时候,我们可以看到加载模型的过程输出:
Downloading (…)okenizer_config.json: 100%
802/802 [00:00<00:00, 57.5kB/s]
Downloading (…)nization_baichuan.py: 100%
9.57k/9.57k [00:00<00:00, 818kB/s]
A new version of the following files was downloaded from https://huggingface.co/baichuan-inc/Baichuan-7B:
- tokenization_baichuan.py
. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision.
Downloading tokenizer.model: 100%
1.14M/1.14M [00:00<00:00, 53.3MB/s]
Downloading (…)cial_tokens_map.json: 100%
411/411 [00:00<00:00, 36.2kB/s]
Downloading (…)lve/main/config.json: 100%
656/656 [00:00<00:00, 62.4kB/s]
Downloading (…)guration_baichuan.py: 100%
2.35k/2.35k [00:00<00:00, 221kB/s]
A new version of the following files was downloaded from https://huggingface.co/baichuan-inc/Baichuan-7B:
- configuration_baichuan.py
. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision.
Downloading (…)modeling_baichuan.py: 100%
28.6k/28.6k [00:00<00:00, 2.32MB/s]
A new version of the following files was downloaded from https://huggingface.co/baichuan-inc/Baichuan-7B:
- modeling_baichuan.py
. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision.
Downloading pytorch_model.bin: 100%
14.0G/14.0G [01:40<00:00, 239MB/s]
Downloading (…)neration_config.json: 100%
132/132 [00:00<00:00, 10.7kB/s]
我们再看一个使用13b参数模型的例子。13b的能力更强,我们就可以使用一样的对话的格式了。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-13B-Chat", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan-13B-Chat")
messages = []
messages.append({"role": "user", "content": "神圣罗马帝国是如何建立的?"})
response = model.chat(tokenizer, messages)
print(response)
输出如下:
神圣罗马帝国(Sacrum Romanum Imperium),又称德意志民族神圣罗马帝国或第一帝国,是962年至1806年间存在于欧洲的历史政治实体。它起源于东法兰克王国,由查理曼大帝的孙子、德意志国王奥托一世在962年被教皇约翰十二世加冕为罗马皇帝时创立。神圣罗马帝国的建立过程可以追溯到公元9世纪末期,当时东法兰克王国逐渐崛起,成为中欧地区的一个强大国家。919年,萨克森公爵亨利一世成为国王,开始了萨利安王朝的统治。亨利一世和他的继任者们加强了中央集权,扩大了领土范围,使东法兰克王国成为了一个强大的政治实体。955年,亨利二世在莱希费尔德战役中击败了马扎尔人,巩固了王国的东部边界。亨利二世还与拜占庭帝国建立了外交关系,引入了许多拜占庭文化元素,如建筑风格和法律制度。这些改革为神圣罗马帝国的建立奠定了基础。962年,教皇约翰十二世为了对抗意大利的诺曼征服者,寻求德意志国王奥托一世的支持。作为回报,教皇约翰十二世将奥托一世加冕为罗马皇帝,从而确立了神圣罗马帝国的地位。从此,神圣罗马帝国成为了基督教世界的精神领袖,同时也是欧洲最强大的国家之一。然而,神圣罗马帝国在实际运作中往往受到诸侯和贵族的掣肘,导致中央集权难以实现。此外,帝国内部的封建制度和领地纷争也削弱了帝国的实力。在13世纪至14世纪期间,神圣罗马帝国陷入了严重的内部分裂和衰落。尽管如此,神圣罗马帝国仍然在欧洲历史上扮演着重要角色。它对文艺复兴时期的欧洲产生了深远影响,同时也为宗教改革和民族国家的兴起提供了舞台。1806年,拿破仑战争结束后,神圣罗马帝国正式宣告解体,取而代之的是一系列独立的国家,如普鲁士、奥地利等。
百川大模型看来相当懂历史,这个回答的结果比gpt4都好。给百川的大佬们点赞。
第一次加裁13b模型的输出如下面这样:
Downloading (…)okenizer_config.json: 100%
954/954 [00:00<00:00, 83.4kB/s]
Downloading (…)nization_baichuan.py: 100%
8.72k/8.72k [00:00<00:00, 787kB/s]
A new version of the following files was downloaded from https://huggingface.co/baichuan-inc/Baichuan-13B-Chat:
- tokenization_baichuan.py
. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision.
Downloading tokenizer.model: 100%
1.14M/1.14M [00:00<00:00, 49.4MB/s]
Downloading (…)cial_tokens_map.json: 100%
544/544 [00:00<00:00, 50.9kB/s]
Downloading (…)lve/main/config.json: 100%
680/680 [00:00<00:00, 61.8kB/s]
Downloading (…)guration_baichuan.py: 100%
1.49k/1.49k [00:00<00:00, 141kB/s]
A new version of the following files was downloaded from https://huggingface.co/baichuan-inc/Baichuan-13B-Chat:
- configuration_baichuan.py
. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision.
Downloading (…)modeling_baichuan.py: 100%
24.5k/24.5k [00:00<00:00, 213kB/s]
Downloading (…)ve/main/quantizer.py: 100%
21.1k/21.1k [00:00<00:00, 1.81MB/s]
A new version of the following files was downloaded from https://huggingface.co/baichuan-inc/Baichuan-13B-Chat:
- quantizer.py
. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision.
A new version of the following files was downloaded from https://huggingface.co/baichuan-inc/Baichuan-13B-Chat:
- modeling_baichuan.py
- quantizer.py
. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision.
Downloading (…)model.bin.index.json: 100%
23.3k/23.3k [00:00<00:00, 2.04MB/s]
Downloading shards: 100%
3/3 [01:58<00:00, 37.32s/it]
Downloading (…)l-00001-of-00003.bin: 100%
9.97G/9.97G [00:36<00:00, 327MB/s]
Downloading (…)l-00002-of-00003.bin: 100%
9.95G/9.95G [00:58<00:00, 209MB/s]
Downloading (…)l-00003-of-00003.bin: 100%
6.61G/6.61G [00:22<00:00, 251MB/s]
Loading checkpoint shards: 100%
3/3 [00:25<00:00, 8.18s/it]
Downloading (…)neration_config.json: 100%
284/284 [00:00<00:00, 25.8kB/s]
百川模型的配置代码
下面我们趁热打铁看下百川模型的代码。
首先是配置类:
from transformers.configuration_utils import PretrainedConfig
from transformers.utils import logginglogger = logging.get_logger(__name__)class BaiChuanConfig(PretrainedConfig):model_type = "baichuan"keys_to_ignore_at_inference = ["past_key_values"]def __init__(self,vocab_size=64000,hidden_size=4096,intermediate_size=11008,num_hidden_layers=32,num_attention_heads=32,hidden_act="silu",max_position_embeddings=4096,initializer_range=0.02,rms_norm_eps=1e-6,use_cache=True,pad_token_id=0,bos_token_id=1,eos_token_id=2,tie_word_embeddings=False,**kwargs,):self.vocab_size = vocab_sizeself.max_position_embeddings = max_position_embeddingsself.hidden_size = hidden_sizeself.intermediate_size = intermediate_sizeself.num_hidden_layers = num_hidden_layersself.num_attention_heads = num_attention_headsself.hidden_act = hidden_actself.initializer_range = initializer_rangeself.rms_norm_eps = rms_norm_epsself.use_cache = use_cachesuper().__init__(pad_token_id=pad_token_id,bos_token_id=bos_token_id,eos_token_id=eos_token_id,tie_word_embeddings=tie_word_embeddings,**kwargs,)类继承自 类。 类是 库中的一个类,用于存储预训练模型的配置信息。
剩下就是介绍下百川模型所用的参数了:
百川的模型代码
上一节我们介绍了LLaMA的的代码,现在我们来看看百川是如何实现的:
class RMSNorm(nn.Module):def __init__(self, hidden_size, eps=1e-6):"""RMSNorm is equivalent to T5LayerNorm"""super().__init__()self.weight = nn.Parameter(torch.ones(hidden_size))self.variance_epsilon = epsdef forward(self, hidden_states):variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)# convert into half-precision if necessaryif self.weight.dtype in [torch.float16, torch.bfloat16]:hidden_states = hidden_states.to(self.weight.dtype)return self.weight * hidden_states
实现逻辑大同小异,这里就不再赘述了。
下面我们再看下百川的位置编码:
class RotaryEmbedding(torch.nn.Module):def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):super().__init__()inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float().to(device) / dim))self.register_buffer("inv_freq", inv_freq)# Build here to make `torch.jit.trace` work.self.max_seq_len_cached = max_position_embeddingst = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device, dtype=self.inv_freq.dtype)freqs = torch.einsum("i,j->ij", t, self.inv_freq)# Different from paper, but it uses a different permutation in order to obtain the same calculationemb = torch.cat((freqs, freqs), dim=-1)self.register_buffer("cos_cached", emb.cos()[None, None, :, :], persistent=False)self.register_buffer("sin_cached", emb.sin()[None, None, :, :], persistent=False)def forward(self, x, seq_len=None):# x: [bs, num_attention_heads, seq_len, head_size]# This `if` block is unlikely to be run after we build sin/cos in `__init__`. Keep the logic here just in case.if seq_len > self.max_seq_len_cached:self.max_seq_len_cached = seq_lent = torch.arange(self.max_seq_len_cached, device=x.device, dtype=self.inv_freq.dtype)freqs = torch.einsum("i,j->ij", t, self.inv_freq)# Different from paper, but it uses a different permutation in order to obtain the same calculationemb = torch.cat((freqs, freqs), dim=-1).to(x.device)self.register_buffer("cos_cached", emb.cos()[None, None, :, :], persistent=False)self.register_buffer("sin_cached", emb.sin()[None, None, :, :], persistent=False)return (self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype),self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype),)
的实现主要是将sin和cos计算的结果缓存起来以便减少计算量。
这里面有一个有意思的知识点叫做 ,译成爱因斯坦求和约定。这个约定是一种简洁的线性代数表达式的表示方法,它省略了求和符号。也可以叫做 ,爱因斯坦表示法。
这种约定可以极大地简化复杂的张量表达式。例如,两个矩阵 A 和 B 的乘积可以简单地写为 C i j = A i k B k j C_{ij} = A_{ik} B_{kj} Cij=AikBkj,其中 i 和 j 是结果矩阵 C 的索引,而 k 是需要求和的索引。
再比如: i k , k j − > i j , A , B ik,kj->ij, A, B ik,kj−>ij,A,B ,就表示矩阵A和B的乘积。
在中,torch.()函数就是用来实现爱因斯坦求和约定的。
于是:
torch.einsum("i,j->ij", t, self.inv_freq)
就表示矩阵t和self.的乘积。
下面我们看下百川的全连接网络:
class MLP(nn.Module):def __init__(self,hidden_size: int,intermediate_size: int,hidden_act: str,):super().__init__()self.gate_proj = nn.Linear(hidden_size, intermediate_size, bias=False)self.down_proj = nn.Linear(intermediate_size, hidden_size, bias=False)self.up_proj = nn.Linear(hidden_size, intermediate_size, bias=False)self.act_fn = ACT2FN[hidden_act]def forward(self, x):return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
这里又出现了一个新的功能,它是一个字典,用来存储激活函数的名称和对应的函数。例如,如果 是 “gelu”,则 [] 将返回 torch.nn..gelu() 函数。
这是一个常见的模式,用于在 中使用自定义激活函数。它允许你在模型中使用任何你喜欢的激活函数,而无需编写额外的代码。
下面我们来看下百川的注意力机制:
class Attention(nn.Module):"""Multi-headed attention from 'Attention Is All You Need' paper"""def __init__(self, config: BaiChuanConfig):super().__init__()self.config = configself.hidden_size = config.hidden_sizeself.num_heads = config.num_attention_headsself.head_dim = self.hidden_size // self.num_headsself.max_position_embeddings = config.max_position_embeddingsif (self.head_dim * self.num_heads) != self.hidden_size:raise ValueError(f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"f" and `num_heads`: {self.num_heads}).")self.W_pack = nn.Linear(self.hidden_size, 3 * self.hidden_size, bias=False)self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)self.rotary_emb = RotaryEmbedding(self.head_dim, max_position_embeddings=self.max_position_embeddings)self.cos, self.sin = None, Nonedef _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
中规中矩,这里没有什么特别强调的地方。
def forward(self,hidden_states: torch.Tensor,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_value: Optional[Tuple[torch.Tensor]] = None,output_attentions: bool = False,use_cache: bool = False,) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:bsz, q_len, _ = hidden_states.size()proj = self.W_pack(hidden_states)proj = proj.unflatten(-1, (3, self.hidden_size)).unsqueeze(0).transpose(0, -2).squeeze(-2)if self.training: # for trainingquery_states = proj[0].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)key_states = proj[1].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)value_states = proj[2].view(bsz, q_len, self.num_heads, self.head_dim)kv_seq_len = key_states.shape[-2]cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)query_states = query_states.transpose(1, 2)key_states = key_states.transpose(1, 2)attn_output = xops.memory_efficient_attention(query_states, key_states, value_states,attn_bias=xops.LowerTriangularMask())attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)attn_output = self.o_proj(attn_output)return attn_output, None, Noneelse: # for inferencequery_states = proj[0].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)key_states = proj[1].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)value_states = proj[2].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)kv_seq_len = key_states.shape[-2]if past_key_value is not None:kv_seq_len += past_key_value[0].shape[-2]cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)if past_key_value is not None:key_states = torch.cat([past_key_value[0], key_states], dim=2)value_states = torch.cat([past_key_value[1], value_states], dim=2)past_key_value = (key_states, value_states) if use_cache else Noneattn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):raise ValueError(f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"f" {attn_weights.size()}")if attention_mask is not None:if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):raise ValueError(f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}")attn_weights = attn_weights + attention_maskattn_weights = torch.max(attn_weights, torch.tensor(torch.finfo(attn_weights.dtype).min))# upcast attention to fp32attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)attn_output = torch.matmul(attn_weights, value_states)if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):raise ValueError(f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"f" {attn_output.size()}")attn_output = attn_output.transpose(1, 2)attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)attn_output = self.o_proj(attn_output)if not output_attentions:attn_weights = Nonereturn attn_output, attn_weights, past_key_value
主要功能:
输出转置 到正确形状输出线性变换()返回输出、权重(可选)和cache (可选)
然后,请注意,百川的模型是只使用解码器的。我们来看下是如何用注意力机制实现解码器的:
class DecoderLayer(nn.Module):def __init__(self, config: BaiChuanConfig):super().__init__()self.hidden_size = config.hidden_sizeself.self_attn = Attention(config=config)self.mlp = MLP(hidden_size=self.hidden_size,intermediate_size=config.intermediate_size,hidden_act=config.hidden_act,)self.input_layernorm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)self.post_attention_layernorm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)def forward(self,hidden_states: torch.Tensor,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_value: Optional[Tuple[torch.Tensor]] = None,output_attentions: Optional[bool] = False,use_cache: Optional[bool] = False,) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
...residual = hidden_stateshidden_states = self.input_layernorm(hidden_states)# Self Attentionhidden_states, self_attn_weights, present_key_value = self.self_attn(hidden_states=hidden_states,attention_mask=attention_mask,position_ids=position_ids,past_key_value=past_key_value,output_attentions=output_attentions,use_cache=use_cache,)hidden_states = residual + hidden_states# Fully Connectedresidual = hidden_stateshidden_states = self.post_attention_layernorm(hidden_states)hidden_states = self.mlp(hidden_states)hidden_states = residual + hidden_statesoutputs = (hidden_states,)if output_attentions:outputs += (self_attn_weights,)if use_cache:outputs += (present_key_value,)return outputs
函数的输入包含 ,它可以用于防止模型关注到输入序列中的某些部分(例如,填充的部分)。
对于 Mask,还有两个辅助的函数需要介绍下:
# Copied from transformers.models.bart.modeling_bart._make_causal_mask
def _make_causal_mask(input_ids_shape: torch.Size, dtype: torch.dtype, device: torch.device, past_key_values_length: int = 0
):"""Make causal mask used for bi-directional self-attention."""bsz, tgt_len = input_ids_shapemask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min, device=device), device=device)mask_cond = torch.arange(mask.size(-1), device=device)mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)mask = mask.to(dtype)if past_key_values_length > 0:mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)# Copied from transformers.models.bart.modeling_bart._expand_mask
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):"""Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`."""bsz, src_len = mask.size()tgt_len = tgt_len if tgt_len is not None else src_lenexpanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)inverted_mask = 1.0 - expanded_maskreturn inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
函数创建一个用于双向自注意力的因果掩码。它首先根据输入的形状和数据类型创建一个全为负无穷大的张量,然后使用 torch. 和 方法将对角线以下的元素设置为 0。如果 th 大于 0,则在掩码的最后一维上添加一些全为 0 的列。最后将掩码扩展到指定的形状并返回。
是将注意力掩码从 [bsz, ] 的形状扩展到 [bsz, 1, , ] 的形状。它首先使用 方法将掩码扩展到指定的形状,然后将其转换为指定的数据类型。接着计算掩码的反转值,并将其填充为负无穷大。最后返回填充后的反转掩码。
下面是最后组装的成果,百川的模型,先看初始化的部分:
class Model(PreTrainedModel):
...def __init__(self, config: BaiChuanConfig):super().__init__(config)self.padding_idx = config.pad_token_idself.vocab_size = config.vocab_sizeself.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)self.layers = nn.ModuleList([DecoderLayer(config) for _ in range(config.num_hidden_layers)])self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)self.gradient_checkpointing = False# Initialize weights and apply final processingself.post_init()def get_input_embeddings(self):return self.embed_tokensdef set_input_embeddings(self, value):self.embed_tokens = value# Copied from transformers.models.bart.modeling_bart.BartDecoder._prepare_decoder_attention_maskdef _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_embeds, past_key_values_length):# create causal mask# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]combined_attention_mask = Noneif input_shape[-1] > 1:combined_attention_mask = _make_causal_mask(input_shape,inputs_embeds.dtype,device=inputs_embeds.device,past_key_values_length=past_key_values_length,)if attention_mask is not None:# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]expanded_attn_mask = _expand_mask(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]).to(inputs_embeds.device)combined_attention_mask = (expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask)return combined_attention_mask
基本上就是个标准的解码器组成的模型。
最后我们来看前向传播的逻辑:
def forward(self,input_ids: torch.LongTensor = None,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_values: Optional[List[torch.FloatTensor]] = None,inputs_embeds: Optional[torch.FloatTensor] = None,use_cache: Optional[bool] = None,output_attentions: Optional[bool] = None,output_hidden_states: Optional[bool] = None,return_dict: Optional[bool] = None,) -> Union[Tuple, BaseModelOutputWithPast]:output_attentions = output_attentions if output_attentions is not None else self.config.output_attentionsoutput_hidden_states = (output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states)use_cache = use_cache if use_cache is not None else self.config.use_cachereturn_dict = return_dict if return_dict is not None else self.config.use_return_dict# retrieve input_ids and inputs_embedsif input_ids is not None and inputs_embeds is not None:raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")elif input_ids is not None:batch_size, seq_length = input_ids.shapeelif inputs_embeds is not None:batch_size, seq_length, _ = inputs_embeds.shapeelse:raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")seq_length_with_past = seq_lengthpast_key_values_length = 0if past_key_values is not None:past_key_values_length = past_key_values[0][0].shape[2]seq_length_with_past = seq_length_with_past + past_key_values_lengthif position_ids is None:device = input_ids.device if input_ids is not None else inputs_embeds.deviceposition_ids = torch.arange(past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device)position_ids = position_ids.unsqueeze(0).view(-1, seq_length)else:position_ids = position_ids.view(-1, seq_length).long()if inputs_embeds is None:inputs_embeds = self.embed_tokens(input_ids)# embed positionsif attention_mask is None:attention_mask = torch.ones((batch_size, seq_length_with_past), dtype=torch.bool, device=inputs_embeds.device)attention_mask = self._prepare_decoder_attention_mask(attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length)hidden_states = inputs_embedsif self.gradient_checkpointing and self.training:if use_cache:logger.warning_once("`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")use_cache = False# decoder layersall_hidden_states = () if output_hidden_states else Noneall_self_attns = () if output_attentions else Nonenext_decoder_cache = () if use_cache else Nonefor idx, decoder_layer in enumerate(self.layers):if output_hidden_states:all_hidden_states += (hidden_states,)past_key_value = past_key_values[idx] if past_key_values is not None else Noneif self.gradient_checkpointing and self.training:def create_custom_forward(module):def custom_forward(*inputs):# None for past_key_valuereturn module(*inputs, output_attentions, None)return custom_forwardlayer_outputs = torch.utils.checkpoint.checkpoint(create_custom_forward(decoder_layer),hidden_states,attention_mask,position_ids,None,)else:layer_outputs = decoder_layer(hidden_states,attention_mask=attention_mask,position_ids=position_ids,past_key_value=past_key_value,output_attentions=output_attentions,use_cache=use_cache,)hidden_states = layer_outputs[0]if use_cache:next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)if output_attentions:all_self_attns += (layer_outputs[1],)hidden_states = self.norm(hidden_states)# add hidden states from the last decoder layerif output_hidden_states:all_hidden_states += (hidden_states,)next_cache = next_decoder_cache if use_cache else Noneif not return_dict:return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)return BaseModelOutputWithPast(last_hidden_state=hidden_states,past_key_values=next_cache,hidden_states=all_hidden_states,attentions=all_self_attns,)
上面的代码虽然不少,但是逻辑还是比较清晰的,主要步骤为:
ast对象包含了最后的隐藏状态,过去的键值对,所有的隐藏状态和注意力权重。
推理功能
首先是一些类定义:
class BaiChuanForCausalLM(PreTrainedModel):def __init__(self, config):super().__init__(config)self.model = Model(config)self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)# Initialize weights and apply final processingself.post_init()def get_input_embeddings(self):return self.model.embed_tokensdef set_input_embeddings(self, value):self.model.embed_tokens = valuedef get_output_embeddings(self):return self.lm_headdef set_output_embeddings(self, new_embeddings):self.lm_head = new_embeddingsdef set_decoder(self, decoder):self.model = decoderdef get_decoder(self):return self.model
然后核心是调用model的前向计算:
def forward(self,input_ids: torch.LongTensor = None,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_values: Optional[List[torch.FloatTensor]] = None,inputs_embeds: Optional[torch.FloatTensor] = None,labels: Optional[torch.LongTensor] = None,use_cache: Optional[bool] = None,output_attentions: Optional[bool] = None,output_hidden_states: Optional[bool] = None,return_dict: Optional[bool] = None,) -> Union[Tuple, CausalLMOutputWithPast]:
...output_attentions = output_attentions if output_attentions is not None else self.config.output_attentionsoutput_hidden_states = (output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states)return_dict = return_dict if return_dict is not None else self.config.use_return_dict# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)outputs = self.model(input_ids=input_ids,attention_mask=attention_mask,position_ids=position_ids,past_key_values=past_key_values,inputs_embeds=inputs_embeds,use_cache=use_cache,output_attentions=output_attentions,output_hidden_states=output_hidden_states,return_dict=return_dict,)hidden_states = outputs[0]logits = self.lm_head(hidden_states)loss = Noneif labels is not None:# Shift so that tokens < n predict nshift_logits = logits[..., :-1, :].contiguous()shift_labels = labels[..., 1:].contiguous()# Flatten the tokensloss_fct = CrossEntropyLoss()shift_logits = shift_logits.view(-1, self.config.vocab_size)shift_labels = shift_labels.view(-1)# Enable model parallelismshift_labels = shift_labels.to(shift_logits.device)loss = loss_fct(shift_logits, shift_labels)if not return_dict:output = (logits,) + outputs[1:]return (loss,) + output if loss is not None else outputreturn CausalLMOutputWithPast(loss=loss,logits=logits,past_key_values=outputs.past_key_values,hidden_states=outputs.hidden_states,attentions=outputs.attentions,)
在前向计算方法中,首先根据输入的参数和模型配置设置一些变量的值,包括:
如果输入了标签,则计算损失。首先将 和标签进行平移和展平处理,然后使用交叉熵损失函数计算损失。
最后根据返回类型的设置返回不同的结果。如果返回类型为字典,则返回一个包含损失、、过去的键值对、隐藏状态和注意力张量的字典。否则,返回一个元组,其中包含损失和其他输出结果。
最后是
def prepare_inputs_for_generation(self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs):if past_key_values:input_ids = input_ids[:, -1:]position_ids = kwargs.get("position_ids", None)if attention_mask is not None and position_ids is None:# create position_ids on the fly for batch generationposition_ids = attention_mask.long().cumsum(-1) - 1position_ids.masked_fill_(attention_mask == 0, 1)if past_key_values:position_ids = position_ids[:, -1].unsqueeze(-1)# if `inputs_embeds` are passed, we only want to use them in the 1st generation stepif inputs_embeds is not None and past_key_values is None:model_inputs = {"inputs_embeds": inputs_embeds}else:model_inputs = {"input_ids": input_ids}model_inputs.update({"position_ids": position_ids,"past_key_values": past_key_values,"use_cache": kwargs.get("use_cache"),"attention_mask": attention_mask,})return model_inputs
这是为的生成阶段准备输入的代码。
主要逻辑:
如果有,截取的最后一个token作为当前输入。计算: 构造字典: 返回给模型函数使用
这样在生成序列时,可以利用缓存,只输入当前时间步的token,而不需要每次传整个序列。
同时动态计算,mask等信息,方便生成不同长度的序列。
小结
这一节我们观其大略地了解了一下百川模型的模型代码。
细节有很多,我们暂时先不一步一步细讲。讲太细了怕大家局限在某一种实现里面。我们现在优先广度搜索,先多看看各家的开源大模型分别是如何实现的,然后再深入研究其中的细节。
我们也希望能够通过走马观花,先了解它们有哪些共同点,哪些是做大模型自然语言处理时都要做的。