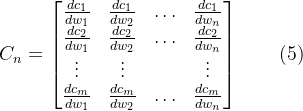视频重压缩检测学习计划和笔记
视频重压缩检测学习计划
记录学习的规划和过程中遇到的一些问题。
看的论文 日期论文名压缩编码格式场景目的特征做法与原理问题/idea
2023.2.14
Frame-wise of I- in H.264 Based on
AVC
非对齐GOP下的帧级的重定位帧(I-P)检测
连续三帧经过滤波的高频灰度图像再用CNN提的特征(像素域)
预处理提取高频信息 送入CNN训练 也就是说利用的也是重压缩产生的像素域高频损失
这里的滤波器我其实有时间可以了解一下 和SRM筛出特征的区别(好像是提出来的东西不一样)
为什么引入 GOP 效果没怎么下降?
2023.2.7
Frame-Wise of HEVC by Deep - in
HEVC
非对齐GOP下的帧级的重定位帧(I-P)检测
CSM和CPM(按照CU的大小和预测模式分别赋权重值)送入CNN和LSTM提取时空特征
具体来说,作者除了根据CU的size分别赋值,也利用了类似GVPF的思想,同时扩展到了CU中(I-P帧的I-CU增加,零运动矢量的P-CU增加和S-CU减少)并将其赋值得到CSM和CPM。将CSM、CPM作为CNN的输入,利用CNN+LSTM捕捉时空特征(捕捉三帧间的CU类型和大小的变化)
这篇文章很重要,如何设计CNN的特征给出了很好的示范
1.比特率下降效果会下降 2.没引入 GOP(可能导致该方法直接失效)
2023.3.7
HEVC with Non GOP Based on a with Flow and Units
HEVC
非对齐GOP下的序列级原始GOP估计和重压缩二分类
背景光流的残差融合上PU(帧内预测)的数量
利用算法给前景移动物体掩膜,然后用背景的光流残差作为一个特征,再将帧的帧内预测PU数量作为另一个特征进行融合,融合完利用这个特征周期性分析和SVM分类
2023.3.7
Video and GOP Size via of
AVC 但也可以用于HEVC
非对齐GOP下的帧级原始GOP估计和帧分类
GVPF(预测模式的变化,相比VPF还用了B帧和运动矢量的信息)
利用RD曲线分析不同类型MB的变化,发现I-P帧的I-MB增加 S-MB减少 零运动向量的P-MB增加 发现B帧中的P-MB不断减少 F-MB不断增加 利用这个特性设计了公式(这里能不能设计成特征图?能, CSM和CPM利用的就是这个思想,可能就是利用LSTM捕捉残差变化值)总的来说 这个思想就是利用预测单元的残差变化值来判断
2023.3.16
A Two-Stage for HEVC Based on
HEVC
非对齐GOP下的帧级的更为细粒度的I-P重定位帧检测(增加的比特率/降低的比特率)
针对上升比特率的重定位I-P帧,其CU类型变化比较明显,作者设计了一个50维的特征
其中h是16种CU所占的比率,s是概率分布的KL散度,共50维。针对较难分类的降低比特率的重定位I-P,作者设计了一个类似CS/PM映射图,映射规则为
还是利用的大小和预测模式,只有规则改了
分两个阶段分别判断两类重定位I-P帧,所以提高了比特率不同的情况下的准确率 。针对低阶统计信息相差大的I-P,直接用SVM分类。针对难分辨的I-P帧,作者设计了一个S-来捕捉时空特征,这里的做法应该是把三帧的特征图了。
这个方法的结果如下:
这个是咋训练的?有时间看下
2023.3.20
- of HEVC With the Same
HEVC
对齐GOP下的视频级的重压缩二分类
主要检测第二次压缩的I帧的痕迹(针对第二次压缩后生成的正常I帧,作者设计了一个特征用于捕捉其帧内预测模式(HEVC的35种预测模式)的变化以及不稳定PU的数量(这里不稳定针对的其实还是预测模式和划分方式,针对的是正常I帧间的差异),除此之外的自适应I帧,作者用了水平和垂直方向的光流异常)
先将单/双压缩视频编码解码三次,分别提取每次的特征然后起来送入SVM训练,这里的多重压缩等于一种特征增强
这篇是视频级的 那么有没有办法做到GOP级/帧级?
2023.3.21
in HEVC-coded video with the same using
HEVC
同参数下的重压缩二分类
5维度的统计信息和62维度的CNN特征,用了PU的帧内预测模式 PU的MPM信息 CU块的深度(也就是size) TU的深度
这篇文章的做法不是多重压缩增强特征,而是将原始序列/重压缩序列再次压缩,提取之间的变化ADM作为特征送入SVM训练
分析一下为什么会work,作者消融实验给了很好的解释:
可以看出文章特征是work的主要原因 1.因为CNN的原因,作者用了32*32或更大尺寸的PU特征 2.作者提出的MPM在实验中看起来也很有用
2023.3.21
Fake Using Deep- From Error
HEVC
GOP级的伪造(上升)比特率检测
I帧patch wise的重压缩误差 一个分支是像素域的亮度分量差 另一个分支是其“0元素效应”的统计信息
这里的one step 压缩类似上面这篇论文,因为这里设计的特征也是一种空域上的“变化”,然后提取I帧patch级的特征和统计特征,送入网络训练,得到GOP级的结果
2023.3.28
and of Video From AVC to HEVC Based on Deep of and PU Maps
转码
帧级AVC-HEVC转码检测
只有P帧的PU Map和高频视频帧
先用无池化层的CNN学习浅层特征,通过在两个卷积层中引入批归一化(BN)和整流线性单元(ReLU),减少了过拟合的可能性,并增加了非线性信息,同时加入skip ,特征表征模块的设计是为了增加通道的数量,压缩特征图的大小,学习每条路径上的最终特征。最后通过一个数据驱动的特征融合模块,帧分类后利用投票策略获得视频级分类
2023.4.4
of fake high for HEVC based on mode
HEVC
视频级假高清(上升比特率和下降QP)分类
一个十维的统计信息特征,4维从视频所有I帧中提取帧内预测模式的出现频率( DC H0和VO),6维是P帧和B帧中帧间预测模式的出现频率(Skip、Merge、AMVP)
2023.4.13
of HEVC with non- GOP via inter-frame
HEVC
视频级不对齐GOP的重压缩分类和原始GOP估计
设计的去块滤波和SAO滤波特征 具体没看懂
理论上是利用帧内和帧间环路滤波决策之间的差异,对重定位I帧的检测 方法是提取手工特征送入SVM
2023.4.17
of HEVC With the Same Based on of Intra
HEVC
视频级同参数重压缩视频分类
不稳定PU 下有推导
比特率相关论文整理:
IEEE 2018 of for HEVC With Fake 用的是每个GOP的第一个P帧的PU分区的直方图作为特征 视频级分类
TCSVT 2014 Fake Bit Rate and Bit Rates I帧的ac系数用于分类 从SSIM曲线中得到空域特征用于估计原始比特率 视频级
of for HEVC Based on the Co- of DCT 用DCT系数提取共生矩阵 视频级 这个论文的实验是不同QP
on Image and Video HEVC under
based on TU type 计算所有GOPs的第一个I/P帧中各TU分区类型的直方图 视频级
学习中遇到的问题 1 光流特征
首先,光流是空域特征,因为它基于像素的运动,描述了相邻图像中像素的运动和变化。
我是在《HEVC with Non- GOP Based on a with Flow and Units》这篇论文中接触到的,这篇文章利用重定位I帧相邻帧的关联性较弱,会导致光流周期性异常这一特点,用ViBe提取背景信息,再用LK算法提取相邻帧光流的残差信息,消除不同时间段内物体运动振幅差异的影响,其中还运用到了中值滤波的技术来减少不必要的噪声。
1.1 为什么帧之间的关联性弱会导致光流周期性异常?
在视频编码中,帧之间的关联性越强,那么相邻帧之间的像素差异就越小。这就意味着,当使用光流算法进行帧间运动估计时,相邻帧之间的运动矢量会更加准确和稳定。
相反,如果帧之间的关联性较弱,则相邻帧之间的像素差异会更大,这就会导致光流算法产生周期性异常。这是因为在这种情况下,光流算法很难估计帧之间的运动矢量,并且可能会产生错误的运动估计结果。当这些错误的运动矢量被用于视频压缩时,会导致视频质量的下降和编码效率的降低。
1.2 ViBe算法
ViBe算法通常用于背景建模和运动检测,并生成背景掩膜。在这篇论文中,ViBe算法被用来生成背景掩膜,从而提取帧间的运动信息和特征。通过将ViBe算法生成的背景掩膜与其他特征进行融合,该算法能够更准确地检测HEVC双重压缩。
1.2LK稀疏光流算法
LK算法(也称为Lucas-算法)是一种常用的光流计算方法,它与传统的光流算法有以下几个区别:
局部像素匹配:传统的光流算法通常将整张图像看作一个整体,对于每个像素点都计算其在整张图像中的运动。而LK算法则是基于局部区域的像素匹配,它假设图像的小邻域内的像素具有相同的运动,然后利用这些邻域内的像素来估计运动。
高斯金字塔降采样:LK算法在计算光流之前会对图像进行高斯金字塔降采样,以减小计算量。在金字塔的不同层级上进行光流计算,可以得到不同尺度上的光流向量。
矩阵求解:传统的光流算法通常采用的是最小二乘法来求解光流向量,而LK算法则是通过求解一个线性方程组得到光流向量。这种方法更加稳定和准确。
总的来说,LK算法相对于传统的光流算法具有更好的稳定性和准确性,但是计算量更大。它适用于相邻帧之间的像素变化比较小的情况,例如相机运动较慢、物体静止等情况。
1.3 这篇文章中的 GOP 与 意欲何为
特别地,Non- GOP结构指的是在重编码过程中,两次GOP参数设置地不同,这个现象会导致周期性现象(由于I-P帧导致的周期峰值)。
利用周期性分析估计出第一次的GOP位置对更精细的取证是很有必要的。
周期性分析是为了去除这些不必要的峰值,因为它会影响I-P帧的检测。
补充:好像看到的光流特征都是为了减少运动物体的影响。
2 LBP特征
LBP(Local )算法
是一种描述图像特征像素点与各个像素点之间的灰度关系的局部特征的非参数算法,同时也是一张高效的纹理描述算法。
纹理是物体表面的自然特性,它描述图像像素点与图像领域之间的灰度空间的分布关系,不会因为光照强弱而改变图像的视觉变化。
原始的LBP算子定义为在33的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素 点的位置被标记为1,否则为0。这样,33邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该窗口中心像 素点的LBP值,并用这个值来反映该区域的纹理信息。
LBP的应用中,如纹理分类、人脸分析等,一般都不将LBP图谱作为特征向量用于分类识别,而是采用LBP特征谱的统计直方图作为特征向量用于分类识别。
LBP的应用中,如纹理分类、人脸分析等,一般都不将LBP图谱作为特征向量用于分类识别,而是采用LBP特征谱的统计直方图作为特征向量用于分类识别。
因为,从上面的分析我们可以看出,这个“特征”跟位置信息是紧密相关的。直接对两幅图片提取这种“特征”,并进行判别分析的话,会因为“位置没有对准”而产生很大的误差。后来,研究人员发现,可以将一幅图片划分为若干的子区域,对每个子区域内的每个像素点都提取LBP特征,然后,在每个子区域内建立LBP特征的统计直方图。如此一来,每个子区域,就可以用一个统计直方图来进行描述;整个图片就由若干个统计直方图组成;
例如:一幅100×100像素大小的图片,划分为10×10=100个子区域(可以通过多种方式来划分区域),每个子区域的大小为10×10像素;在每个子区域内的每个像素点,提取其LBP特征,然后,建立统计直方图;这样,这幅图片就有10×10个子区域,也就有了10×10个统计直方图,利用这10×10个统计直方图,就可以描述这幅图片了。之后,我们利用各种相似性度量函数,就可以判断两幅图像之间的相似性了;
而实际检测人脸时,因为不同块的表示人脸的贡献值不同,如眼睛的LBP的统计直方图对识别人脸的贡献明显要比光秃秃的额头的贡献大,在检测到人脸的情况下,我们通常给不同位置的块不同的权重来提高人脸识别的准确率,下面给出一组7*7时用到的权重模板的例子
2,1,1,1,1,1,2,
2,4,4,1,4,4,2,
1,1,1,0,1,1,1,
0,1,1,0,1,1,0,
0,1,1,1,1,1,0,
0,1,1,2,1,1,0,
0,1,1,1,1,1,0
对LBP特征向量进行提取的步骤
(1)首先将检测窗口划分为16×16的小区域(cell);
(2)对于每个cell中的一个像素,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数,即得到该窗口中心像素点的LBP值;
(3)然后计算每个cell的直方图,即每个数字(假定是十进制数LBP值)出现的频率;然后对该直方图进行归一化处理。
(4)最后将得到的每个cell的统计直方图进行连接成为一个特征向量,也就是整幅图的LBP纹理特征向量;
然后便可利用SVM或者其他机器学习算法进行分类了。
3 视频编码压缩中的主要参数
比特率(Bit Rate):比特率是指每秒钟传送的比特数,通常用bps(bit per )来表示。在视频压缩中,表示单位时间内视频压缩后所包含的信息量大小。
比特率(Bit Rate) = 帧宽度 × 帧高度 × 帧率 × 像素位数 × 压缩比率
码率( Rate):码率是指编码器每秒钟压缩的数据量,通常用bps来表示。在视频编码中,码率是指对视频进行压缩编码后每秒钟所占用的数据传输带宽。码率越高,视频的画面质量越高,但传输带宽也越大。码率是影响视频传输带宽的关键参数之一。在视频压缩编码中,码率与比特率是相同的,因为视频流中传输的就是比特数据。但在其他类型的数据传输中,如音频流或网络传输,码率可能不仅仅是比特率,它也可能包括一些其他的控制数据、头信息等。因此,虽然比特率和码率在视频压缩编码中通常可以互换使用,但它们在不同的领域中有所不同。比特率更加强调视频数据的传输速率和质量,而码率则更强调整个数据传输过程的速率和稳定性。
QPs代表量化参数( ),是一种用于控制压缩比和图像质量之间平衡的参数。量化是压缩编码的过程中,将输入的连续信号转换为离散信号的过程。QPs决定了量化步长的大小,因此越高的QP会导致更大的量化步长,从而减少了编码时需要传输的数据量,但也会降低图像的质量。因此,QPs是控制压缩比和图像质量之间平衡的重要参数。量化参数越大,压缩比就越高,图像质量就越低。
量化步长和量化参数QP的关系如下:
量化矩阵与量化步长的关系:
编码帧率是指视频压缩时每秒钟编码的帧数,也就是编码器处理视频的速度,它受到多个因素的影响,包括GOP大小、码率、视频分辨率等等。编码帧率越高,视频文件的大小就会越大,但也会有更高的画面流畅度和更好的视频质量。
视觉帧率是指观看视频时每秒钟显示的画面数,也就是人眼能够感知到的画面切换的速度。通常情况下,人眼可以感知到每秒钟大约24帧的画面切换,因此24fps被认为是最低要求的视觉帧率。视觉帧率越高,视频就会有更好的流畅度和更真实的感觉,但也会增加视频文件的大小。
GOP长度(Group of ):指视频编码中的一个GOP包含多少个帧,通常为15、30、60等。GOP长度越长,视频的压缩效率越高,但同时也会降低视频的响应速度和画面质量,也就更难检测重压缩的痕迹。
DCs代表直流系数(DC ),是一种用于压缩视频时降低低频信号能量的方法。低频信号通常在视频中占据大部分的信息量,但它们往往对最终的视觉质量影响较小。因此,通过对低频信号进行压缩,可以减少传输的数据量,提高压缩比。DCs是一种用于描述低频信号的系数,可以被压缩为更小的数据量以达到降低视频数据的目的。
R-D曲线(Rate- curve)是一种常用的视频质量评估指标,通常用于评估视频编码器的性能。
在视频编码中,编码器需要在压缩视频的同时尽可能保持视频质量。RD曲线是一种图表,它显示了压缩率(R)与失真度(D)之间的关系。这个曲线代表了在不同压缩比例下,视频质量的失真程度。D为取对数的PSNR,R为视频的,通常单位为kbps/Mbps。RD曲线的R可以用也可以用10log()
其中,R代表码率或压缩比率,表示每秒传输的比特数或者压缩比率。D代表失真度或畸变度,表示压缩后图像或视频与原始信号之间的差异或误差。
RD曲线越低,表示在给定的失真度水平下,可以达到更高的压缩比率,即编码器的性能更好。RD曲线的斜率反映了视频编码器在失真度和码率之间的权衡。斜率越陡峭,表示在增加码率的同时,失真度增加的速度越快,这意味着编码器在失真度和码率之间的平衡更好。
4 关于SVM和CNN的选择
在视频编码中,通常使用SVM等机器学习算法对编码单元(如CU、TU、PU等)的类型进行分类。原因是编码单元的类型数量相对较少,而且它们的特征通常是手工设计的,不需要考虑时空上的相关性。因此,传统的机器学习算法(如SVM、随机森林等)可以很好地处理这种低维数据,并且训练速度相对较快。
相比之下,卷积神经网络(CNN)通常用于处理高维数据,如图像或视频帧,以提取时空上的相关特征。CNN可以自动从数据中学习特征,因此在训练大型数据集时具有很好的性能。但是,在编码单元类型分类这种低维数据的任务中,CNN可能会过度拟合,因为数据量太小而不能提供足够的信息来训练复杂的神经网络。
因此,在视频编码中,倾向于使用传统的机器学习算法对低维数据进行分类,而使用深度学习算法如CNN等处理高维数据,例如视频帧、图像序列或时间序列等
5 GOP
GOP(Group of )技术是一种视频编码技术,它可以根据视频内容的特性动态地选择不同的GOP大小。
传统的GOP大小在编码过程中是固定的,但是视频内容的复杂性和变化性可能导致固定的GOP大小无法在不损失质量的情况下有效地压缩视频数据。因此, GOP技术可以根据视频内容的特性动态地选择不同的GOP大小,以在不影响视频质量的情况下实现更高的视频压缩率。
具体来说, GOP技术可以根据视频内容中的运动和场景变化,动态选择不同的GOP大小,并根据需要调整每个GOP中的I帧、P帧和B帧的数量。这种技术可以使编码器在处理视频内容变化时更加灵活,从而在保持视频质量的同时提高视频压缩率。
6 视频压缩编码过程中的作用
在视频压缩编码过程中,通常是指一个缓存区或缓存器,用于存储编码器处理的数据。具体来说,它是一个临时存储区域,用于存储视频流中的一定数量的帧或部分帧,以便在编码器中进行处理和压缩。
在视频编码中起着非常重要的作用,因为它可以平衡处理器的工作速度和视频数据的产生速度之间的差异。如果视频数据的产生速度过快,而处理器的工作速度跟不上,就会出现数据包丢失或处理延迟等问题。因此,使用可以帮助调整视频数据的产生速度,以使其与处理器的工作速度匹配。
此外,还可以用于解决视频传输中的网络延迟问题。例如,在实时视频通信中,可以用来缓存一定数量的帧,以便在网络传输出现延迟时能够保证视频的连续性。
7 MPM(Most Mode)
《 in HEVC-coded video with the same using 》这篇论文中接触到了这个编码信息。
在HEVC标准中,为了提高帧内预测的精度,采用了更多的预测模式,但这也导致了编码的开销增加。因此,为了降低帧内编码的开销,需要高效地选择合适的预测模式。
与H.264/AVC中仅使用一个MPM不同,HEVC为每个预测单元(PU)派生了三个MPM,以提高预测的准确性。
在MPM的选择过程中,HEVC使用左侧PU的预测模式(PML)和上方PU的预测模式(PMA)来决定当前PU的三个MPM。具体来说,对于每个PU,HEVC根据左侧PU和上方PU的预测模式,从可行的预测模式中选择三个最可能的模式作为当前PU的MPM。
这么做的好处是压缩数据节省传输的开销,具体来说,果当前PU的预测模式可以从三个MPMs中选择一个,则只需要将所选的MPM的位置信息发送给解码器即可。
如果当前PU的预测模式不能从MPMs中选择一个,则需要使用5位编码来表示其余的预测模式。这个5位的编码表示当前PU所使用的预测模式的编号。
因此,根据当前PU的预测模式是否能够从MPMs中选择,采用不同的编码方式,可以在保证视频编码质量的同时,尽可能地减小数据传输量,提高编码效率。
7.1 比特流和码流的区别
比特流()指的是视频编码器输出的二进制数据流,它包含了所有视频帧的编码信息,其中每个比特代表着视频帧的一个信息单元。比特流中的信息包括了视频帧的像素信息、预测模式、运动矢量、量化参数、码表等等。
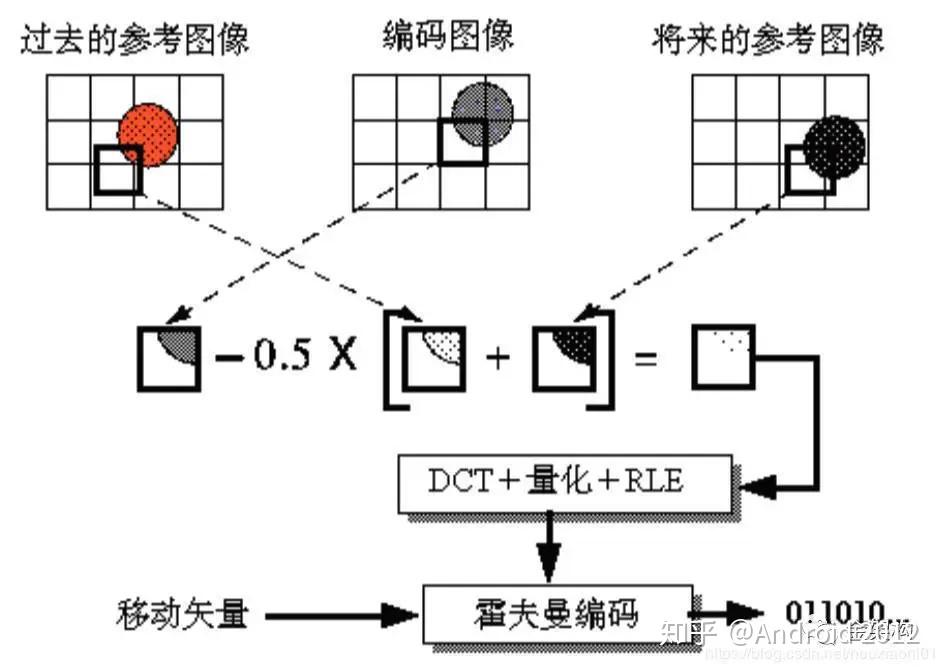
码流()则是将比特流打包成一个完整的数据流,通常包含帧同步信息和错误检测、纠错码等冗余信息。在视频传输和存储中,码流经常被用于网络传输和磁盘存储,通常以压缩后的形式出现。码流的大小通常以比特率()来衡量,即每秒传输的比特数,常见的单位是Mbps(兆比特每秒)。
因此,比特流和码流都是视频编码后的输出结果,但比特流是原始的二进制数据流,而码流则是经过打包和加入冗余信息的数据流。
7.2 本文的特征设计( in HEVC-coded video with the same using )
理解下这个公式,x和y是PU所在位置,文章说i和j是PU的深度,那就是大小呗,一个32×32的那么i和j就取到31,所以这和CPM好像没区别,准确的说这是PPM,且这里的M指的是帧内预测模式(35种那个)。
**在帧内预测中,CU可以选择35种帧内预测模式之一,包括模式和其他模式。而PU则仅可以使用CU选择的预测模式来预测像素的值。因此,选择哪种帧内预测模式是由CU来决定的。
**
HEVC视频编码中的预测模式是针对编码单元( Unit, CU)内的每个预测块( Unit, PU)而言的,而不是针对整个CU而言的。
在HEVC中,CU是视频帧的最小编码单元,一个CU由多个PU组成,每个PU代表了一个预测块。每个PU可以采用不同的预测模式进行预测,例如帧内预测中的直流(DC)预测、水平(H)预测、竖直(V)预测、向上(U)预测、向下(D)预测等等。因此,每个PU需要选择一个预测模式进行预测。
实际上,每个CU都确定了一个预测模式,但是CU的预测模式仅仅用于确定CU内的参考像素,而不是PU内的参考像素。而PU的预测模式是用于确定PU内参考像素的,因此在HEVC中需要在PU中查找预测模式。
同时,由于在HEVC中,PU的大小和位置不一定是固定的,可能存在大小和位置不同的PU共存于一个CU中的情况,因此需要在每个PU中查找预测模式,以便选择合适的预测模式进行编码。
7.3 编码模式
在HEVC编码器中,默认的编码模式是Main ,在这个模式下支持的视频格式与H.264/AVC相同,但是使用了新的编码算法。
All Intra (AI)编码模式是一种只使用帧内预测,不使用帧间预测的编码模式。这种编码模式对于实时视频传输、视频监控等领域具有重要的应用价值,因为它可以减少视频压缩的延迟。
Low Delay P(LDP)编码模式则是一种具有低延迟的帧间预测编码模式,适用于实时通信等需要低延迟的场景。在这种模式下,编码器会限制B帧的数量,以减少编码延迟。
8 量化中的f是什么
在HEVC视频压缩编码中,量化过程中的一个重要参数是量化步长,它用于将变换系数量化为离散的整数值。在计算量化步长时,通常还需要考虑一个称为f的参数,它控制着量化系数的舍入关系。
具体来说,f参数用于确定在量化系数舍入之前应该加上的偏移量。偏移量的大小与f的取值有关,通常为0、1/2或1。偏移量的作用是防止量化误差过大,并降低量化引起的失真。
举个例子,假设量化步长为10,变换系数为27。如果f参数为0,那么量化后的系数为2,即27/10取整数部分;如果f参数为1/2,那么加上偏移量后的系数为27+1/2=27.5,量化后的系数为3,即27.5/10取整数部分;如果f参数为1,那么加上偏移量后的系数为27+1=28,量化后的系数为2,即28/10取整数部分。
因此,f参数的作用是调整量化系数的舍入方式,以获得更好的编码效果和视频质量。通常,在编码器中,f参数的取值会根据不同的量化模式、视频质量和压缩率进行动态调整。
9 假清晰度场景的理论分析
视频比特率是反映视频质量的重要因素之一,可以从文件头中获得。
假比特率视频是通过上转换原始视频的比特率来生成的,用类似插值的方法增加了视频每秒钟传输的比特量,让视频文件更大,但是该操作没有增加视频内容的额外信息,无法通过比特率上转换操作提高原始视频的视觉质量。
在实际应用中,制作假比特率视频总是为了获得高点击率(CTR),其中CTR表示点击特定链接的用户与查看广告、电子邮件或网页的总用户数量的比例。
QP代表量化参数( ),是一种用于控制压缩比和图像质量之间平衡的参数,具体来说,调低量化参数,量化步长就会变小,量化后的值就越大,保留的细节信息就更多,压缩比就越低,假QP视频并没有更多的细节信息,所以也无法提高原始视频质量。
高/低比特率:
“Bit rate is the to the of , for with the . In this , we how of CU per- form when a video is with bit rates. We two types of , with the bit rate and with the bit rate. For the first case, are also as fake bit rate in works [23, 24], where the video of fake bit rate be with their . On the other hand, for the case, of , such as I- [10, 17], from a more by the lossy .”
也就是说低比特率是存在的,因为带宽限制
高/低清晰度:再想想
10 实验编码参数分析 10.1 和Adapt GOP对实验的影响
一般会做不同GOP的检测效果,因为GOP越大,压缩质量越差,视频的细节和纹理信息丢失的就越多,也就是说伪造和篡改的痕迹也随之更加模糊,因此GOP的size可以衡量算法的鲁棒性。
Adapt GOP的影响在这篇文章( Frame-wise of I- in H.264 Based on )中很小,可能是因为输入是一个三帧片段的原因,这种帧级检测引入Adapt并不会下降特别多,只有I I-P P P后三帧作为输入这种情况检测不出。如果算法只考虑I-P帧的周期性,那么引入Adapt将会直接导致算法失效,所以这篇文章(HeNET)做了个帧级的检测。
还有 可能由于这篇文章用的数据集MV不是特别大,Adapt I帧出现的少,所以检测每下降多少。
当第二次GOP设置比第一次小时,实验效果都会变差,这是因为帧间预测的错误传播容易消除I-P帧的伪影。
10.2 Bit Rates对实验的影响
同比特率变化检测的理论分析,特别的,实验证明当参数属于下采样时,压缩域的信息比像素域更work。(原文:这表明压缩域的编码信息更适合提取鲁棒特征,特别是在重编码过程中出现严重的有损量化时。此外,当B1≤B2时,所有方法都有很好的检测结果,因为在这种情况下,在压缩和解压缩域中,双重压缩引起的痕迹的强度可以保持相对可区分。)
做这个实验也是看算法在上采样/下采样场景下的效果是否鲁棒,不过这里的比特率是否单独代表了上下采样这个场景,目前还不理解,还要学习编码过程。
10.3 QP对实验的影响
这里做的是相同编码参数的场景,通常情况下 ,QP越高,效果越来越差。在本文中,随着QP的增加,准确性并没有明显的降低或增加。这是因为无论QP的值如何变化,量化过程所引入的失真都是不可避免的。在连续压缩过程中,信息的丢失肯定会导致像素值的变化,而我们提出的检测特征可以有效地表征这种类型的变化。
11 压缩与重压缩导致的误差损失
视频压缩过程主要由预测变换、量化和熵编码组成。
量化过程中通常会引入f偏移量控制量化系数的舍入关系(偏移量的作用是防止量化误差过大,并降低量化引起的失真,量化过程使用整数进行,所以需要floor),这会引起舍入误差,一般称其为量化误差。
在量化后,还需要将帧逆量化和变化,并进行环路滤波将其作为参考帧。
其中RT代表舍入和截断操作,这一部分的信息损失主要由舍入截断误差(这里的舍入是将浮点数舍入为离散整数 截断误差是因为逆量化器的运算数位表示有限,所以在恢复为原始信号时会出现误差)和环路滤波(主要是去块滤波)导致的。
1.针对假比特率场景
真比特率视频编码时量化矩阵中的元素是比较小的,这样可以尽可能地保留视频地细节和视觉质量。因此真高清视频的信息损失主要来源于量化和舍入截断。
为了伪造假高清视频,假比特率视频第一次编码的Q1是远大于Q2的,不仅如此,第一次压缩由于Q1较大,块伪影会更加严重,因此第二次压缩会采用去块滤波技术消除伪影,因此假高清视频的信息损失主要来源于量化和去块滤波。
两种不同的信息损失经过多次重压缩在空域所显示的伪影不同,因此可以用于检测。
除了空域的伪影,在编码域中,假比特率视频的帧内和帧间预测模式也会有所变化,第一次压缩降低了图像的纹理复杂度,因此第二次帧内编码会使用更多的和DC模式,角度模式中会使用更多的H0和V0。第一次压缩也减少了块间的时空差异,因此在第二次帧间编码中会使用更多的Skip模式,因此在编码域中也可以找到特征。
而出现这种现象的原因仍然是因为量化误差,
如果是比特率上升或QP下降(假高清)的场景,那么第一次量化产生的误差大,那么第二次编码时预测模式变化的就更多。
如果是比特率下降或者QP提升(假低清)场景,那么第一次量化误差相比就小的很多,那么第二次编码时量化会更严重,而重压缩痕迹也会因此退化的更严重,那么基于预测模式就很难检测出假视频。
“若用ERR 表示误差,可以近似地表示为 NQRT 和 NLP 之和。NQRT 指的是量化、舍入和截断损失,NLP 指的是循环滤波损失。这里主要考虑量化损失,因为舍入和截断损失相对较小。具体来说,NQRT 损失可以视为量化引起的高频损失,因为一些高频系数会被量化为 0。而循环滤波可以抵消因块效应和环绕效应引起的不一致性和波动,因此 NLP 也可以视为高频损失。”
也就是说损失主要是两点,量化损失和环路滤波损失。
量化是将原始视频信号转化为离散的频域系数,由于高频信号变化比较快,所以它们的系数值通常比低频系数值更小。当进行量化时,为了控制压缩比率,一些较小的高频系数可能会被量化为0,因此这些被量化为0的高频系数就会丢失,从而导致高频信号的损失,因此可以视为高频损失。
为什么高频信号变化快?
在信号处理中,频率越高意味着信号变化得越快。这是因为频率指的是信号在单位时间内震荡的次数,而高频信号震荡得更加频繁,因此变化也更快。相反,低频信号震荡得更少,变化也相对较慢。在视频编码中,由于高频信号变化得比较快,因此它们的系数值通常比低频系数值更小。
高频信号出现在哪里?
在一张图像中,高频信号通常会出现在边缘和细节等变化较大的区域。这是因为边缘和细节等区域中的亮度值变化很快,相邻像素之间的差异很大,因此在变换域中对应的频率分量就比较高。相反,一些平滑的区域,如背景和大片的同色区域,其亮度值变化较缓慢,相邻像素之间的差异较小,因此在变换域中对应的频率分量就比较低。在视频编码中,由于高频分量通常需要较多的比特来表示,因此在量化时可能会出现0值,从而导致高频损失。
因此也可以推导出环路滤波也会导致高频信息的损失:
循环滤波(in-loop )是在图像编码过程中为了减少块效应和环绕效应所引起的不一致性和波动而引入的技术。块效应和环绕效应是由于编码器在将图像分成块时引入的边缘效应而产生的,这些效应可能会导致图像质量降低。
由于循环滤波技术会对编码后的图像进行过滤处理,因此它可以抵消块效应和环绕效应带来的一些损失,包括高频损失。在HEVC重编码检测中,将这部分损失归为NLP,主要是因为在循环滤波的过程中,边缘和细节等区域中的高频分量通常会被滤波去除或者减弱,从而产生一定的损失。因此,NLP也可以被视为高频损失的一种,尽管它与量化误差引起的高频损失的机制不同。
简单来说,环路滤波通过去除边缘细节来优化压缩后的图像质量,这样也导致高频的信号一定的损失。
特别的,量化矩阵中的值有何意义?
在视频压缩中,量化矩阵中的值越大代表压缩比越高,图像质量越低。具体来说,量化过程就是将离散余弦变换(DCT)后的图像系数除以一个量化矩阵,再四舍五入取整。量化矩阵中的每个元素决定了对应的频域系数的量化级别。值越大,表示对应的频域系数会被量化得更严格,进而降低图像质量,实现更高的压缩比。值越小,表示对应的频域系数会被量化得更松散,图像质量相对更好,但压缩比相应也会降低。不同的视频编码标准和不同的编码场景都会采用不同的量化矩阵。此外,高频信息对应的量化矩阵的值也会比较大,如下图:
对应的矩阵:
11 TMM假比特率论文
重压缩导致的高频误差 单压缩(真实比特率视频)的质量退化主要是因为量化、舍入截断 重压缩则是量化和去块滤波| 这篇文章利用解压缩帧的亮度分量差来检测比特率假高的重压缩视频,这个特征之所以work,是因为两次压缩质量退化的原因是不同的.对于©中误差为0的正方形区域,这是由于一些高度可预测性的局部内容,帧内预测算法可以获得精确的预测,这使得第一次压缩时预测残差非常小,对于假比特率视频,那么在经历第二次压缩变换量化时其结果可能就为0了,那么在一步进一步的再压缩操作之后,解压缩帧中的像素可能不再改变,这导致了这种零元素聚集正方区域。做法上。patch级别检测然后多数投票策略
为什么这里是GOP级别而不是帧级检测,是因为作者只使用了一个GOP中的I帧的特征做检测,作者声称PB帧中的帧间质量退化过于复杂
作者做了这方面的实验,看来帧级的检测是有望的,只要能分析出帧间编码的运动补偿和传播噪声。
12 推一下不稳定PU的公式
VF代表I帧中每个PU的luma分量的帧内预测模式和分区类型的统计信息
NUPU就表示了”不稳定“PU的数量 AVR则代表了平均变化率。
为什么帧内编码质量退化会导致PU趋于稳定?
所谓不稳定PU就是说PU分类和帧内预测模式的变化,可以理解经过不断地压缩,图像细节纹理慢慢消失,采用的帧内预测模式也就慢慢的不变了。这让我联想到了之前看地空域“零方块”现象,多一次压缩,会有些编码单元“稳定”下来,本质上是一个原因。
11 模型和特征维度整理
128维
128维
62维