[work] 算法学习笔记 (爬山法,模拟退火算法,遗传算法)
在优化问题中,有两个关键点
代价函数
确定问题的形式和规模之后,根据不同的问题,选择要优化的目标。如本文涉及的两个问题中,一个优化目标是使得航班选择最优,共计12个航班,要使得总的票价最少且每个人的等待时间之和最小。第二个问题是学生选择宿舍的问题,每个学生可以实现填报志愿,如果安排的宿舍与志愿完全一致,则代价为0,与第二志愿一致,代价为1,如果没有和志愿一致,代价为3。 故,抽象问题的能力很重要,如何将自己要优化的目标量化的表达出来,是解决优化函数的关键。如在普通的数值优化问题中,可选择当前值与目标值距离的绝对之差,或者使用平方损失函数,均可。
值域
值域是确定搜索的范围。一个可行解的范围是多少,比如学生选宿舍的问题,一共学校有100间宿舍,编号为1-100,那么这个数值优化问题的每个可行解的范围均在100之内。不同的问题对应不同的可行解,也要具体问题具体分析。
随机搜索算法
随机搜索算法是最简单的优化搜索算法,它只适用于代价函数在值域范围内没有任何变化规律的情况。即找不到任何使得代价下降的梯度和极小值点。
我们只需要在值域范围内生成足够多的可行解,然后分别计算每个可行解的代价,根据代价选择一个最小的可行解作为随机搜索的最优解即可。
# 搜索方法1: 随机搜索算法
# 函数会作1000次随机猜测,记录总代价最低的方法. domain为航班号的范围(0-9),共有5个人,因此共有10项def randomoptimize(self, domain):best_sol = []bestcost = 99999for i in range(1000):sol = [0] * len(domain)for j in range(len(domain) / 2): # 人数sol[2 * j] = random.randint(domain[2 * j][0], domain[2 * j][1])sol[2 * j + 1] = random.randint(domain[2 * j + 1][0], domain[2 * j + 1][1])print sol[:]newcost = self.schedulecost(sol)if newcost < bestcost:bestcost = newcostbest_sol = solelse:continueself.printschedule(best_sol)print "随机搜索算法的结果的最小代价是:", bestcostreturn best_sol
爬山法
爬山法假设当前解和周围的解是有变化规律的,如,当前解得下方有一个代价较小的解,则我们就认为,沿着这个方向走,解会越来越小。步骤为:首先选择一个解作为种子解,每次寻找与这个解相近的解,如果相近的解中有代价更小的解,则把这个解作为种子解。而如果周围的解都比该解的代价大,则表示已经到达了局部极小值点,搜索停止。

# 搜索算法2:爬山法# 首先随机选择一个解作为种子解,每次寻找这个种子相近的解,如果相近的解有代价更小的解,则把这个新的解作为种子# 依次循环进行,当循环到某种子附近的解都比该种子的代价大时,说明到达了局部极小值点,搜索结束def hillclimb(self, domain):# 随机产生一个航班序列作为初始种子seed = [random.randint(domain[i][0], domain[i][1]) for i in range(len(domain))]while 1:neighbor = []# 循环改变解的每一个值产生一个临近解的列表for i in range(len(domain)):# 下列判断是为了将某一位加减1后不超出domain的范围# print seedif seed[i] > domain[i][0]:newneighbor = seed[0:i] + [seed[i] - 1] + seed[i + 1:]# print newneighbor[:]neighbor.append(newneighbor)if seed[i] < domain[i][1]:newneighbor = seed[0:i] + [seed[i] + 1] + seed[i + 1:]# print newneighbor[:]neighbor.append(newneighbor)# 对所有的临近解计算代价,排序,得到代价最小的解neighbor_cost = sorted([(s, self.schedulecost(s)) for s in neighbor], key=lambda x: x[1])# 如果新的最小代价 > 原种子代价,则跳出循环if neighbor_cost[0][1] > self.schedulecost(seed):break# 新的代价更小的临近解作为新的种子seed = neighbor_cost[0][0]print "newseed = ", seed[:], " 代价:", self.schedulecost(seed)# 输出self.printschedule(seed)print "爬山法得到的解的最小代价是", self.schedulecost(seed)return seed
模拟退火算法
从一个问题的原始解开始,用一个变量代表温度,这一温度开始时非常高,而后逐步减低。在每一次迭代期间,算法会随机选中题解中的某个数字,使其发生细微变化,而后计算该解的代价。关键的地方在于计算出该解的代价后,如果决定是否接受该解。
如果新的成本更低,则新的题解就会变成当前题解,这与爬山法类似;如果新的成本更高,则新的题解与概率 P 被接受。这一概率会随着温度T的降低而降低。即算法开始时,可以接受表现较差的解,随着退火过程中温度的不断下降,算法越来越不可以接受较差的解,知道最后,它只会接受更优的解。 **
其中P = exp[-( - )/ T ]
其中是新解的成本,是当前成本,T为当前温度。算法以概率P接受新的解。**
# 搜索算法4:模拟退火算法# 参数:T代表原始温度,cool代表冷却率,step代表每次选择临近解的变化范围# 原理:退火算法以一个问题的随机解开始,用一个变量表示温度,这一温度开始时非常高,而后逐步降低# 在每一次迭代期间,算啊会随机选中题解中的某个数字,然后朝某个方向变化。如果新的成本值更# 低,则新的题解将会变成当前题解,这与爬山法类似。不过,如果成本值更高的话,则新的题解仍# 有可能成为当前题解,这是避免局部极小值问题的一种尝试。# 注意:算法总会接受一个更优的解,而且在退火的开始阶段会接受较差的解,随着退火的不断进行,算法# 原来越不能接受较差的解,直到最后,它只能接受更优的解。# 算法接受较差解的概率 P = exp[-(highcost-lowcost)/temperature]def annealingoptimize(self, domain, T=10000.0, cool=0.98, step=1):# 随机初始化值vec = [random.randint(domain[i][0], domain[i][1]) for i in range(len(domain))]# 循环while T > 0.1:# 选择一个索引值i = random.randint(0, len(domain) - 1)# 选择一个改变索引值的方向c = random.randint(-step, step) # -1 or 0 or 1# 构造新的解vecb = vec[:]vecb[i] += cif vecb[i] < domain[i][0]: # 判断越界情况vecb[i] = domain[i][0]if vecb[i] > domain[i][1]:vecb[i] = domain[i][1]# 计算当前成本和新的成本cost1 = self.schedulecost(vec)cost2 = self.schedulecost(vecb)# 判断新的解是否优于原始解 或者 算法将以一定概率接受较差的解if cost2 < cost1 or random.random() < math.exp(-(cost2 - cost1) / T):vec = vecbT = T * cool # 温度冷却print vecb[:], "代价:", self.schedulecost(vecb)self.printschedule(vec)print "模拟退火算法得到的最小代价是:", self.schedulecost(vec)return vec
随机生成一组解,成为一个种群
通过上述三种方法,从上一代种群中构建出了下一代种群。而后,这一过程重复进行,知道达到了指定的迭代次数,或者连续数代都没有改善种群,则整个过程就结束了。
# 搜索算法5: 遗传算法
# 原理: 首先随机生成一组解,我们称之为种群,在优化过程的每一步,算法会计算整个种群的成本函数,
# 从而得到一个有关题解的有序列表。随后根据种群构造进化的下一代种群,方法如下:
# 遗传:从当前种群中选出代价最优的一部分加入下一代种群,称为“精英选拔”
# 变异:对一个既有解进行微小的、简单的、随机的修改
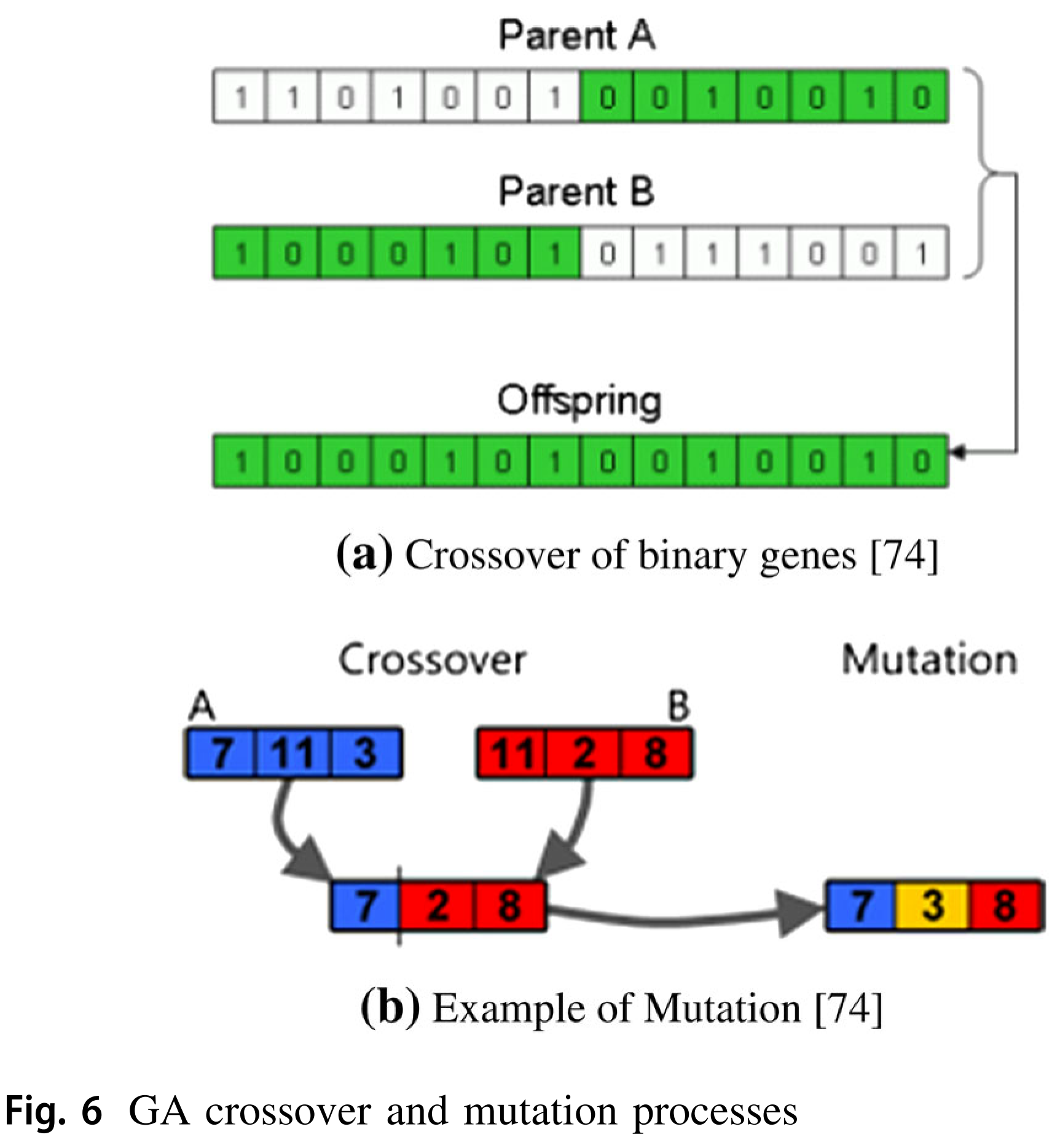
# 交叉:选取最优解中的两个解,按照某种方式进行交叉。方法有单点交叉,多点交叉和均匀交叉
# 一个种群是通过对最优解进行随机的变异和配对处理构造出来的,它的大小通常与旧的种群相同,尔后,这一过程会
# 一直重复进行————新的种群经过排序,又一个种群被构造出来,如果达到指定的迭代次数之后题解都没有得
# 改善,整个过程就结束了
# 参数:
# popsize-种群数量 step-变异改变的大小 mutprob-交叉和变异的比例 elite-直接遗传的比例 maxiter-最大迭代次数
def geneticoptimize(self, domain, popsize=50, step=1, mutprob=0.2, elite=0.2, maxiter=100):# 变异操作的函数def mutate(vec):i = random.randint(0, len(domain) - 1)if random.random() < 0.5 and vec[i] > domain[i][0]:return vec[0:i] + [vec[i] - step] + vec[i + 1:]elif vec[i] < domain[i][1]:return vec[0:i] + [vec[i] + step] + vec[i + 1:]# 交叉操作的函数(单点交叉)def crossover(r1, r2):i = random.randint(0, len(domain) - 1)return r1[0:i] + r2[i:]# 构造初始种群pop = []for i in range(popsize):vec = [random.randint(domain[i][0], domain[i][1]) for i in range(len(domain))]pop.append(vec)# 每一代中有多少胜出者topelite = int(elite * popsize)# 主循环for i in range(maxiter):scores = [(self.schedulecost(v), v) for v in pop]scores.sort()ranked = [v for (s, v) in scores] # 解按照代价由小到大的排序# 优质解遗传到下一代pop = ranked[0: topelite]# 如果当前种群数量小于既定数量,则添加变异和交叉遗传while len(pop) < popsize:# 随机数小于 mutprob 则变异,否则交叉if random.random() < mutprob: # mutprob控制交叉和变异的比例# 选择一个个体c = random.randint(0, topelite)# 变异pop.append(mutate(ranked[c]))else:# 随机选择两个个体进行交叉c1 = random.randint(0, topelite)c2 = random.randint(0, topelite)pop.append(crossover(ranked[c1], ranked[c2]))# 输出当前种群中代价最小的解print scores[0][1], "代价:", scores[0][0]self.printschedule(scores[0][1])print "遗传算法求得的最小代价:", scores[0][0]return scores[0][1]

书中给出了关于学生宿舍选择的一个具体例子,以下是代码
# -*- coding: utf-8 -*-
__author__ = 'Bai Chenjia'import random
import math
"""
宿舍分配问题,属于搜索优化问题。优化方法使用optimization.py中使用的
随机搜索、爬山法、模拟退火法、遗传算法等. 但题解的描述比之前的问题复杂
"""class dorm:def __init__(self):# 代表宿舍,每个宿舍有两个隔间可用self.dorms = ['Zeus', 'Athena', 'Hercules', 'Bacchus', 'Pluto']# 代表选择,第一列代表人名,第二列和第三列代表该学生的首选和次选self.prefs = [('Toby', ('Bacchus', 'Hercules')),('Steve', ('Zeus', 'Pluto')),('Karen', ('Athena', 'Zeus')),('Sarah', ('Zeus', 'Pluto')),('Dave', ('Athena', 'Bacchus')),('Jeff', ('Hercules', 'Pluto')),('Fred', ('Pluto', 'Athena')),('Suzie', ('Bacchus', 'Hercules')),('Laura', ('Bacchus', 'Hercules')),('James', ('Hercules', 'Athena'))]# 题解的表示法:# 设想每个宿舍有两个槽,本例中共有5个宿舍,则共有10个槽,我们将每名学生依序安置于各空槽# 内————则第一名学生有10种选择,解的取值范围为0-9;第二名学生有9种选择,解的取值范围为# 0-8,第三名学生解的取值范围是0-7,以此类推,最后一名学生只有一个可选。# 按照上述题解的表示法初始化题解范围:self.domain = [(0, 2*len(self.dorms)-1-i) for i in range(len(self.prefs))]# 根据题解序列vec打印出最终宿舍分配方案# 注意,输出一个槽后表明该槽已经用过,需将该槽删除def printsolution(self, vec):slots = []# slots = [0,0,1,1,2,2,3,3,4,4]for i in range(len(self.dorms)):slots.append(i)slots.append(i)# 循环题解print "选择方案是:"for i in range(len(vec)):index = slots[vec[i]]print self.prefs[i][0], self.dorms[index]del slots[vec[i]]# 代价函数: 如果学生当前安置的宿舍使其首选则代价为0,是其次选则代价为1,否则代价为3# 注意,输出一个槽后表明该槽已经用过,需将该槽删除def dormcost(self, vec):cost = 0# 建立槽slots = []for i in range(len(self.dorms)):slots.append(i)slots.append(i)# 循环题解for i in range(len(vec)):index = slots[vec[i]]if self.dorms[index] == self.prefs[i][1][0]:cost += 0elif self.dorms[index] == self.prefs[i][1][1]:cost += 1else:cost += 3del slots[vec[i]]return cost"""下列函数与 optimization 中函数相同,只不过代价函数和输出函数用本问题的输出函数"""# 搜索方法1: 随机搜索算法# 函数会作1000次随机猜测,记录总代价最低的方法. domain为航班号的范围(0-9),共有5个人,因此共有10项def randomoptimize(self, domain):best_sol = []bestcost = 99999for i in range(1000):sol = [0] * len(domain)for j in range(len(domain) / 2): # 人数sol[2 * j] = random.randint(domain[2 * j][0], domain[2 * j][1])sol[2 * j + 1] = random.randint(domain[2 * j + 1][0], domain[2 * j + 1][1])print sol[:]newcost = self.dormcost(sol)if newcost < bestcost:bestcost = newcostbest_sol = solelse:continueself.printsolution(best_sol)print "随机搜索算法的结果的最小代价是:", bestcostreturn best_sol# 搜索算法2:爬山法# 首先随机选择一个解作为种子解,每次寻找这个种子相近的解,如果相近的解有代价更小的解,则把这个新的解作为种子# 依次循环进行,当循环到某种子附近的解都比该种子的代价大时,说明到达了局部极小值点,搜索结束def hillclimb(self, domain):# 随机产生一个航班序列作为初始种子seed = [random.randint(domain[i][0], domain[i][1]) for i in range(len(domain))]while 1:neighbor = []# 循环改变解的每一个值产生一个临近解的列表for i in range(len(domain)):# 下列判断是为了将某一位加减1后不超出domain的范围# print seedif seed[i] > domain[i][0]:newneighbor = seed[0:i] + [seed[i] - 1] + seed[i + 1:]# print newneighbor[:]neighbor.append(newneighbor)if seed[i] < domain[i][1]:newneighbor = seed[0:i] + [seed[i] + 1] + seed[i + 1:]# print newneighbor[:]neighbor.append(newneighbor)# 对所有的临近解计算代价,排序,得到代价最小的解neighbor_cost = sorted([(s, self.dormcost(s)) for s in neighbor], key=lambda x: x[1])# 如果新的最小代价 > 原种子代价,则跳出循环if neighbor_cost[0][1] > self.dormcost(seed):break# 新的代价更小的临近解作为新的种子seed = neighbor_cost[0][0]print "newseed = ", seed[:], " 代价:", self.dormcost(seed)# 输出self.printsolution(seed)print "爬山法得到的解的最小代价是", self.dormcost(seed)return seed# 搜索算法4:模拟退火算法# 参数:T代表原始温度,cool代表冷却率,step代表每次选择临近解的变化范围# 原理:退火算法以一个问题的随机解开始,用一个变量表示温度,这一温度开始时非常高,而后逐步降低# 在每一次迭代期间,算啊会随机选中题解中的某个数字,然后朝某个方向变化。如果新的成本值更# 低,则新的题解将会变成当前题解,这与爬山法类似。不过,如果成本值更高的话,则新的题解仍# 有可能成为当前题解,这是避免局部极小值问题的一种尝试。# 注意:算法总会接受一个更优的解,而且在退火的开始阶段会接受较差的解,随着退火的不断进行,算法# 原来越不能接受较差的解,直到最后,它只能接受更优的解。# 算法接受较差解的概率 P = exp[-(highcost-lowcost)/temperature]def annealingoptimize(self, domain, T=10000.0, cool=0.98, step=1):# 随机初始化值vec = [random.randint(domain[i][0], domain[i][1]) for i in range(len(domain))]# 循环while T > 0.1:# 选择一个索引值i = random.randint(0, len(domain) - 1)# 选择一个改变索引值的方向c = random.randint(-step, step) # -1 or 0 or 1# 构造新的解vecb = vec[:]vecb[i] += cif vecb[i] < domain[i][0]: # 判断越界情况vecb[i] = domain[i][0]if vecb[i] > domain[i][1]:vecb[i] = domain[i][1]# 计算当前成本和新的成本cost1 = self.dormcost(vec)cost2 = self.dormcost(vecb)# 判断新的解是否优于原始解 或者 算法将以一定概率接受较差的解if cost2 < cost1 or random.random() < math.exp(-(cost2 - cost1) / T):vec = vecbT = T * cool # 温度冷却print vecb[:], "代价:", self.dormcost(vecb)self.printsolution(vec)print "模拟退火算法得到的最小代价是:", self.dormcost(vec)return vec# 搜索算法5: 遗传算法# 原理: 首先随机生成一组解,我们称之为种群,在优化过程的每一步,算法会计算整个种群的成本函数,# 从而得到一个有关题解的有序列表。随后根据种群构造进化的下一代种群,方法如下:# 遗传:从当前种群中选出代价最优的一部分加入下一代种群,称为“精英选拔”# 变异:对一个既有解进行微小的、简单的、随机的修改# 交叉:选取最优解中的两个解,按照某种方式进行交叉。方法有单点交叉,多点交叉和均匀交叉# 一个种群是通过对最优解进行随机的变异和配对处理构造出来的,它的大小通常与旧的种群相同,尔后,这一过程会# 一直重复进行————新的种群经过排序,又一个种群被构造出来,如果达到指定的迭代次数之后题解都没有得# 改善,整个过程就结束了# 参数:# popsize-种群数量 step-变异改变的大小 mutprob-交叉和变异的比例 elite-直接遗传的比例 maxiter-最大迭代次数def geneticoptimize(self, domain, popsize=50, step=1, mutprob=0.2, elite=0.2, maxiter=100):# 变异操作的函数def mutate(vec):i = random.randint(0, len(domain) - 1)res = []if random.random() < 0.5 and vec[i] > domain[i][0]:res = vec[0:i] + [vec[i] - step] + vec[i + 1:]elif vec[i] < domain[i][1]:res = vec[0:i] + [vec[i] + step] + vec[i + 1:]else:res = vecreturn res# 交叉操作的函数(单点交叉)def crossover(r1, r2):i = random.randint(0, len(domain) - 1)return r1[0:i] + r2[i:]# 构造初始种群pop = []for i in range(popsize):vec = [random.randint(domain[i][0], domain[i][1]) for i in range(len(domain))]pop.append(vec)# 每一代中有多少胜出者topelite = int(elite * popsize)# 主循环for i in range(maxiter):if [] in pop:print "***"try:scores = [(self.dormcost(v), v) for v in pop]except:print "pop!!", pop[:]scores.sort()ranked = [v for (s, v) in scores] # 解按照代价由小到大的排序# 优质解遗传到下一代pop = ranked[0: topelite]# 如果当前种群数量小于既定数量,则添加变异和交叉遗传while len(pop) < popsize:# 随机数小于 mutprob 则变异,否则交叉if random.random() < mutprob: # mutprob控制交叉和变异的比例# 选择一个个体c = random.randint(0, topelite)# 变异if len(ranked[c]) == len(self.prefs):temp = mutate(ranked[c])if temp == []:print "******", ranked[c]else:pop.append(temp)else:# 随机选择两个个体进行交叉c1 = random.randint(0, topelite)c2 = random.randint(0, topelite)pop.append(crossover(ranked[c1], ranked[c2]))# 输出当前种群中代价最小的解print scores[0][1], "代价:", scores[0][0]self.printsolution(scores[0][1])print "遗传算法求得的最小代价:", scores[0][0]return scores[0][1]if __name__ == '__main__':dormsol = dorm()#sol = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]#dormsol.printsolution(sol)#dormsol.dormcost(sol)domain = dormsol.domain# 方法1:随机猜测#dormsol.randomoptimize(domain)# 方法2:爬山法#dormsol.hillclimb(domain)# 方法3:模拟退火法#dormsol.annealingoptimize(domain)# 方法4:遗传算法dormsol.geneticoptimize(domain)
三种算法分析
这三种都是用来求解函数“最大值”问题的算法,我们可以把函数曲线理解成一个一个山峰和山谷组成的山脉(如图片所示)。那么我们可以设想所得到的每一个解就是一只青蛙,我们希望它们不断的向着更高处跳去,直到跳到最高的山峰(尽管青蛙本身不见得愿意那么做)。所以求最大值的过程就转化成一个“青蛙跳”的过程。
下面介绍介绍“青蛙跳”的几种方式。
爬山算法(最速上升爬山法):
从搜索空间中随机产生邻近的点,从中选择对应解最优的个体,替换原来的个体,不断重复上述过程。因为只对“邻近”的点作比较,所以目光比较“短浅”,常常只能收敛到离开初始位置比较近的局部最优解上面。对于存在很多局部最优点的问题,通过一个简单的迭代找出全局最优解的机会非常渺茫。(在爬山法中,青蛙最有希望到达最靠近它出发点的山顶,但不能保证该山顶是珠穆朗玛峰,或者是一个非常高的山峰。因为一路上它只顾上坡,没有下坡。)
模拟退火算法:
这个方法来自金属热加工过程的启发。在金属热加工过程中,当金属的温度超过它的熔点( Point)时,原子就会激烈地随机运动。与所有的其它的物理系统相类似,原子的这种运动趋向于寻找其能量的极小状态。在这个能量的变迁过程中,开始时。温度非常高,使得原子具有很高的能量。随着温度不断降低,金属逐渐冷却,金属中的原子的能量就越来越小,最后达到所有可能的最低点。利用模拟退火算法的时候,让算法从较大的跳跃开始,使到它有足够的“能量”逃离可能“路过”的局部最优解而不至于限制在其中,当它停在全局最优解附近的时候,逐渐的减小跳跃量,以便使其“落脚”到全局最优解上。(在模拟退火中,青蛙喝醉了,而且随机地大跳跃了很长时间。运气好的话,它从一个山峰跳过山谷,到了另外一个更高的山峰上。但最后,它渐渐清醒了并朝着它所在的峰顶跳去。)
遗传算法:
模拟物竞天择的生物进化过程,通过维护一个潜在解的群体执行了多方向的搜索,并支持这些方向上的信息构成和交换。以面为单位的搜索,比以点为单位的搜索,更能发现全局最优解。(在遗传算法中,有很多青蛙,它们降落到喜玛拉雅山脉的任意地方。这些青蛙并不知道它们的任务是寻找珠穆朗玛峰。但每过几年,就在一些海拔高度较低的地方射杀一些青蛙,并希望存活下来的青蛙是多产的,在它们所处的地方生儿育女。)可以描述成这样的一个故事:从前,有一大群青蛙,它们被莫名其妙的零散地遗弃于喜马拉雅山脉。于是只好在那里艰苦的生活。海拔低的地方弥漫着一种无色无味的毒气,海拔越高毒气越稀薄。可是可怜的青蛙们对此全然不觉,还是习惯于活蹦乱跳。于是,不断有青蛙死于海拔较低的地方,而越是在海拔高的青蛙越是能活得更久,也越有机会生儿育女。就这样经过许多年,这些青蛙们竟然都不自觉地聚拢到了一个个的山峰上,可是在所有的青蛙中,只有聚拢到珠穆朗玛峰的青蛙被带回了美丽的澳洲。)