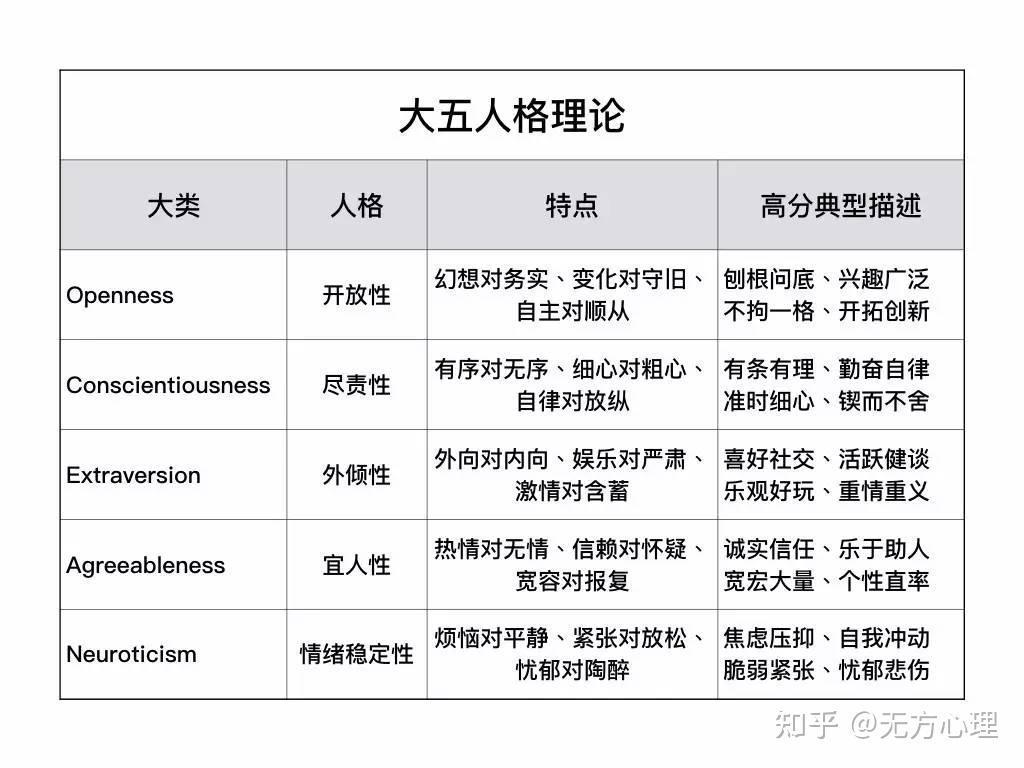
在XGBoost中通过Early Stop避免过拟合
本文翻译自Avoid By Early With In ,讲述如何在使用建模时通过Early Stop手段来避免过拟合。全文系作者原创,仅供学习参考使用,转载授权请私信联系,否则将视为侵权行为。码字不易,感谢支持。以下为全文内容:
过拟合问题是在使用复杂的非线性学习算法时会经常碰到的,比如 算法。
在这篇博客中你将发现如何通过Early Stop方法使得我们在使用中的模型时可以尽可能地避免过拟合问题:
读完这篇博客后,你将学到:
让我们开始吧。
使用Early Stop避免过拟合
Early Stop是训练复杂机器学习模型以避免其过拟合的一种方法。
它通过监控模型在一个额外的测试集上的表现来工作,当模型在测试集上的表现在连续的若干次(提前指定好的)迭代中都不再提升时它将终止训练过程。
它通过尝试自动选择拐点来避免过拟合,在拐点处,测试数据集的性能开始下降,而训练数据集的性能随着模型开始过拟合而继续改善。
性能的度量可以是训练模型时正在使用的损失函数(例如对数损失),或通常意义上用户感兴趣的外部度量(例如分类精度)。
在中监控模型的表现
模型在训练时可以计算并输入在某个指定的测试数据集的性能表现。
在调用model.fit()函数时,可以指定测试数据集和评价指标,同时设置参数为True,这样就可以在训练过程中输出模型在测试集的表现。
例如,我们可以通过下面的方法在使用训练二分类任务时输出分类错误率(通过“error”指定):
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, eval_metric="error", eval_set=eval_set, verbose=True)
提供了一系列的模型评价指标,包括但不限于:
完整的列表见文档中的“ Task ””章节。
例如,我们可以演示如何监控使用UCI机器学习存储库(更新:从这里下载)的关于Pima糖尿病发病数据集的模型在训练过程中的性能指标。
完整代码清单如下:
# monitor training performance
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=7)
# fit model no training data
model = XGBClassifier()
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, eval_metric="error", eval_set=eval_set, verbose=True)
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
运行这段代码将会在67%的数据集上训练模型,并且在每一轮迭代中使用剩下的33%数据来评估模型的性能。

每次迭代都会输出分类错误,最终将会输出最后的分类准确率。
...
[89] validation_0-error:0.204724
[90] validation_0-error:0.208661
[91] validation_0-error:0.208661
[92] validation_0-error:0.208661
[93] validation_0-error:0.208661
[94] validation_0-error:0.208661
[95] validation_0-error:0.212598
[96] validation_0-error:0.204724
[97] validation_0-error:0.212598
[98] validation_0-error:0.216535
[99] validation_0-error:0.220472
Accuracy: 77.95%
观察所有的输出,我们可以看到,在训练快要结束时测试集上的模型性能的变化是平缓的,甚至变得更差。
使用学习曲线来评估模型
我们可以提取出模型在测试数据集上的表现并绘制成图案,从而更好地洞察到在整个训练过程中学习曲线是如何变化的。
在调用模型时我们提供了一个数组,数组的每一项是一个X和y的配对。在测试集之外,我们同时将训练集也作为输入,从而观察在训练过程中模型在训练集和测试集上各自的表现。
例如:
eval_set = [(X_train, y_train), (X_test, y_test)]
model.fit(X_train, y_train, eval_metric="error", eval_set=eval_set, verbose=True)
模型在各个数据集上的表现可以在训练结束后通过model.()函数获取,这个函数返回一个dict包含了评估数据集的代码和对应的分数列表,例如:
results = model.evals_result()
print(results)
这将输出如下的结果:
{'validation_0': {'error': [0.259843, 0.26378, 0.26378, ...]},'validation_1': {'error': [0.22179, 0.202335, 0.196498, ...]}
}
“”和“”代表了在调用fit()函数时传给参数的数组中数据集的顺序。
一个特定的结果,比如第一个数据集上的分类错误率,可以通过如下方法获取:
results['validation_0']['error']
另外我们可以指定更多的评价指标,从而同时获取多种评价指标的变化情况。
接着我们可以使用收集到的数据绘制曲线,从而更直观地了解在整个训练过程中模型在训练集和测试集上的表现究竟如何。
下面是一段完整的代码,展示了如何将收集到的数据绘制成学习曲线:
# plot learning curve
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from matplotlib import pyplot
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=7)
# fit model no training data
model = XGBClassifier()
eval_set = [(X_train, y_train), (X_test, y_test)]
model.fit(X_train, y_train, eval_metric=["error", "logloss"], eval_set=eval_set, verbose=True)
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
# retrieve performance metrics
results = model.evals_result()
epochs = len(results['validation_0']['error'])
x_axis = range(0, epochs)
# plot log loss
fig, ax = pyplot.subplots()
ax.plot(x_axis, results['validation_0']['logloss'], label='Train')
ax.plot(x_axis, results['validation_1']['logloss'], label='Test')
ax.legend()
pyplot.ylabel('Log Loss')
pyplot.title('XGBoost Log Loss')
pyplot.show()
# plot classification error
fig, ax = pyplot.subplots()
ax.plot(x_axis, results['validation_0']['error'], label='Train')
ax.plot(x_axis, results['validation_1']['error'], label='Test')
ax.legend()
pyplot.ylabel('Classification Error')
pyplot.title('XGBoost Classification Error')
pyplot.show()
运行这段代码将会在每一次训练迭代中输出模型在训练集和测试集上的分类错误率。我们可以通过设置=False来关闭输出。
我们绘制了两张图,第一张图表示的是模型在每一轮迭代中在两个数据集上的对数损失:
第二张图表示分类错误率:
从第一张图来看,似乎有机会可以进行Early Stop,大约在20到40轮迭代时比较合适。
从第二张图可以得到相似的结果,大概在40轮迭代时效果比较理想。
在中进行Early Stop
提供了在指定轮数完成后提前停止训练的功能。
除了提供用于评估每轮迭代中的评价指标和数据集之外,还需要指定一个窗口大小,意味着连续这么多轮迭代中模型的效果没有提升。这是通过s参数来设置的。
例如,我们可以像下面这样设置连续10轮中对数损失都没有提升:
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True)
如果同时指定了多个评估数据集和多个评价指标,s将会使用数组中的最后一个作为依据。
下面提供了一个使用s的详细例子:
# early stopping
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# split data into train and test sets
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# fit model no training data
model = XGBClassifier()
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True)
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
运行这段代码将得到如下的输出(部分):
...
[35] validation_0-logloss:0.487962
[36] validation_0-logloss:0.488218
[37] validation_0-logloss:0.489582
[38] validation_0-logloss:0.489334
[39] validation_0-logloss:0.490969
[40] validation_0-logloss:0.48978
[41] validation_0-logloss:0.490704
[42] validation_0-logloss:0.492369
Stopping. Best iteration:
[32] validation_0-logloss:0.487297
我们可以看到模型在迭代到42轮时停止了训练,在32轮迭代后观察到了最好的效果。
通常将s设置为一个与总训练轮数相关的函数(本例中是10%),或者通过观察学习曲线来设置使得训练过程包含拐点,这两种方法都是不错的选择。
总结
在这篇博客中你发现了如何监控模型的表现以及怎么做Early Stop。
你学会了:
关于Early Stop或者这篇博客你还有什么想问的问题吗?欢迎在下方的评论区留言,我将尽我最大的努力来解答。