LLaVA-Med 论文阅读笔记
LLaVA-Med: a Large -and- for in One Day 论文阅读笔记
本文提出了一种经济有效的方法训练一个可以回答生物医学图像开放研究问题的视觉-语言对话助手。其核心思想是从 中提取大规模、广覆盖的生物医学数字字母数据集,使用GPT-4对字幕的开放式教学跟随数据进行只知道然后对字幕中的数据进行微调。
论文地址:
项目地址:
目录
文章目录 6 s
1
论文的背景主要如下。
基于上述背景,作者团队提出了LLaVA-Med模型,第一次尝试将多模态指令调整应用于生物医学领域,通过自动生成的生物医学多模态指令遵循数据进行端到端训练。
论文的主要贡献包括:
2 Works
这一部分介绍了当前有的一些生物医学领域的聊天机器人。
这一部分介绍了构建能够基于生物医学图像问答问题的方法,现有的方法主要分为辨别式方法()和生成式()方法。
辨别式方法: 将VQA问题视为分类问题,其中模型从预定义的答案集中进行预测。辨别式方法在性能上表现良好,但处理封闭集预测,需要在推断时进行调整,特别是当提供了定制答案集时。生成式方法: 为了解决封闭集问题,开发了生成式方法,这些方法将答案预测为自由形式的文本序列。生成式方法更加灵活,因为它们自然地将封闭集问题视为一种特殊情况,其中候选答案以语言指令形式呈现。
生成式方法的优势在于其多功能性,更适用于处理开放问题,与通用生物医学助手回答现场问题的需求一致。
Model
LLaVA-Med与语言模型的前缀调优类似,使用一个可训练的模块连接冻结的图像编码器和语言模型。在论文*Open-ended of . arXiv arXiv:2303.05977, 2023*中,使用了一个三层MLP,如下图所示。而LLaVA-Med采用了和LLaVA相同的思路,使用简单的线性投影来作为接口以降低训练成本。
在模型结构上的创新不大,LLaVA-Med的主要贡献在于提出一种新颖的数据生成方法,利用GPT-4自我生成生物医学多模态指令遵循数据,使用来自 的广泛可用的生物医学图像文本对。
3 - Data
第三部分介绍了生物医学视觉指令跟随数据集的构建,由机器和人类共同参与,包括概念对齐和指令跟随两个部分。分别用于增强跨模态理解能力和遵循不同指令。
3.1 概念对齐数据( Data)
适用于通过训练来让生物医学图像的信息和文本相匹配。具体而言,对于生物医学图像 X v \{X_v} Xv以及字幕 X c \{X_c} Xc,给定一个问题 X q \{X_q} Xq(要求机器描述这个图像),使用这个三元组来构成一个数据样例。问题 X q \{X_q} Xq根据 X c \{X_c} Xc 的长度是否超过30个单词来决定是简洁还是具体地描述(在PMC-15M中,有25%的字幕是少于30词的),这些问题的列表在原文的 A。大致和LLaVA的内容相同。
H u m a n : X q , X v Human:\{X_q},\{X_v} Human:Xq,Xv \n A s s i s t a n t : X c :X_c :Xc \n
作者从PMC-15M中选出了一组600K 个图像-文本对用于构成这部分数据。
3.2 生物医学指令调整数据( - Data)
为了使模型能够遵循多样的指令,作者采取了以下措施:
多轮对话的指令遵循数据: 通过提示只使用文本的 GPT-4,作者设计了包含生物医学图像的多轮对话指令。这些指令要求 GPT-4根据图像字幕生成多轮问题和答案,模拟一种语气,就像它能够看到图像一样。添加上下文信息的提示: 为了提供有关图像的更多上下文,作者创建了一种提示,不仅包括标题,还包括原始 论文中提到图像的句子。这有助于提供更多关于图像的信息,以便更好地生成有意义的对话。
手动策划的 few-shot 示例: 在提示中,作者手动策划了 few-shot 示例,以演示如何基于提供的标题和上下文生成高质量的对话。关于few-shot的提示()如下如所示。
图像和上下文的收集: 为了收集图像标题及其上下文,作者从 PMC-15M 中筛选出仅包含单一情节的图像。从这些图像中,他们采样了来自五种最常见成像模式的60K对图像文本。此外,他们从原始的 论文中提取提到图像的句子作为标题的额外上下文,灵感来自于外部知识有助于泛化的观察。
在上述代码中,few-shot 示例的实现涉及对 中的每个示例进行迭代,然后将其中的上下文信息和模型响应作为对话的一部分添加到 列表中。具体步骤如下:
首先, 是一个包含手动策划的 few-shot 示例的列表。这些示例可能包括输入上下文()和相应的模型响应()。使用 for in : 遍历 中的每个示例。对于每个示例,使用 [''] 作为用户的输入,将用户的消息添加到 中,{"role":"user", "":['']}。接着,使用 [''] 作为模型的输出,将模型的响应添加到 中,{"role":"", "":['']}。这样,每个 few-shot 示例都被添加为一个用户与助手的对话交互,其中包含了手动策划的上下文信息和相应的模型生成。
最后, 列表中也包含了系统提示和用户的查询消息,形成了一个完整的对话。这个对话可以用于提示 GPT-4 生成医学视觉指令遵循数据。整个对话被设计为一个多轮的交互,旨在引导模型以多样化的方式生成对于生物医学图像的指令遵循对话。
作者根据数据质量的迭代过程 生成了三个版本的数据:
数据的统计信息如图2所示。
(a, b):指令和响应的根动词-名词对: 图中显示了指令和响应的根动词-名词对的统计信息。图中的内圈表示输出响应的根动词,而外圈表示直接的名词。(c ):图像和问题回答对的领域分布: 图中展示了五个领域上的图像和问题回答对的分布。每个领域都展示了一个图像,这些图像来自特定的文献引用。
4 to the
将通用领域的LLaVA模型引入生物医学领域,其方法是使用同样的网络结构并使用生物医学领域的图像-文本数据训练,过程如图3所示。并在视觉会话和问答问题上进行了测评。与数据的划分一样,训练过程也分为两部分:生物医疗概念对齐和生物医疗指令调整。从图示中可以看到训练的过程只使用了不到一天的时间。
在机器学习中,Curriculum learning(课程学习)是一种训练模型的策略,其核心思想是通过逐步调整训练样本的难度,帮助模型逐渐学习复杂的模式和任务。Curriculum learning 的一般思路是从相对简单的例子开始,逐渐过渡到更难的例子。这种渐进式的学习方式可以帮助模型在早期阶段更容易收敛,提高整体学习效果。
4.1 Stage 1: .
在§3.1 中提到,作者从PMC-15M中选出了一组600K 个图像-文本对用于构成特征对齐的数据集。对于每个样本,在给定语言指令和图像输入的情况下,作者要求模型预测原始图像标题。在训练过程中,冻结了视觉编码器和语言模型的权重,只更新投影矩阵。通过这种方法来让模型学习在生物医学领域的概念对齐。
4.2 Stage 2: End-to-End -.
这一部分的数据如§3.2 中提到,使用生物医学文本-图像指令遵循数据对模型进行微调,开发生物医学聊天机器人。在训练过程中,只保持视觉编码器冻结 ,继续更新预训练的投影层和语言模型的权重。
4.3 Fine- to
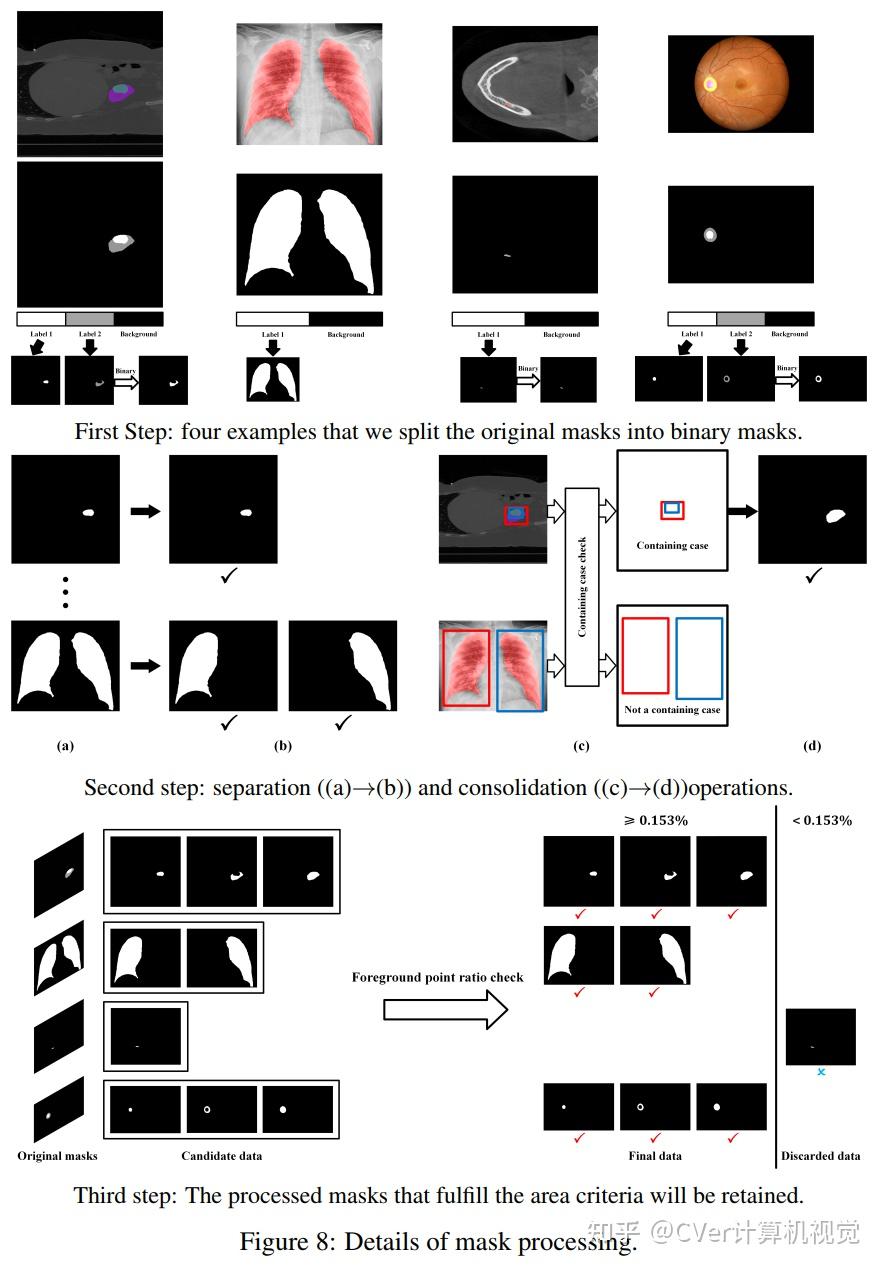
为了适应具体的生物医学任务,需要在下游数据集上进行微调。作者在模型完成两个阶段的训练后在三个生物医学 VQA数据集上进行了微调。具体方法是给定生物医学图像作为上下文,提供多个自然语言问题,让助手以自由文本形式回答闭集和开集的问题,并为每个闭合集问题的提示构建了候选答案列表。
论文这一部分的引用是[27]来自Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in Neural Information Processing Systems, 2022.
论文中,作者提出了Science Question Answering(SCIENCEQA),这是一个新的基准,包含约21,000个多模态的选择题,涵盖多样的科学主题,并附带了与相应讲座和解释对应的答案注释。
4.4
这段文字介绍了LLaVA-Med模型的三个优点或含义:
开发成本低廉: 与通过扩大数据/模型规模以获得最佳性能不同,LLaVA-Med旨在以较低的开发成本提供经济实惠且合理的解决方案。在8个40G A100 GPU上,第一阶段和第二阶段分别花费7小时和8小时。
通用于多个领域: 尽管本文侧重于生物医学领域,但所提出的适应过程具有通用性,可以推广到其他垂直领域,如游戏和教育。这些领域需要建立一个有帮助的助手,需要新颖的概念和领域知识。借用了论文中的don’t stop pre-的观点,作者考虑了从大规模未标记数据创建领域特定指导数据的可扩展流程,并提倡不停止指令调整以构建定制的大型多模态语言模型(LMM)。
Don't stop pre-training源自论文Don’t stop pretraining: Adapt language models to domains and tasks. arXiv preprint arXiv:2004.10964, 2020,论文的主要贡献是:
1、在跨越低资源和高资源情境的四个领域和八个任务中,对领域自适应和任务自适应预训练进行了彻底的分析;
2、对调整后的语言模型在不同领域和任务之间的可迁移性进行了研究;
3、进行了一项研究,强调在人工策划的数据集上进行预训练的重要性,并提出了一种简单的数据选择策略,以自动接近该性能。
低服务成本: 与通用LMM的模型规模可能巨大且服务成本可能过高相比,定制的LMM在低服务成本方面具有独特的优势。
平滑的模型适应: 该网络架构允许从 [49]初始化视觉编码器,或从 [43]初始化语言模型,这可能导致更高的性能。然而,从LLaVA初始化的适应过程是平滑的,作为一个聊天机器人,模型的行为从菜鸟过渡到能够提供有帮助的领域特定响应的专业助手。
对上述提到的和
来自论文Large-scale - for - . arXiv arXiv:2303.00915, 2023.
链接:. : An open- GPT-4 with 90%* .
5
在实验部分,作者团队考察了多模态生物医学指令数据(§3 )的质量LLaVA-Med模型(§4 )的表现。对于模型表现,考察了以下两点:
在实验过程中,仅使用只支持语言的GPT-4模型。
5.1
在生物医学多模态对话方面的性能,作者描述了数据机构建、问题生成、参考预测和回答生成、回答评估,得分计算,以及模型解释等方面。具体如下。
评估数据集构建: 通过随机选择50个未见过的PMC-15M图像和标题配对,生成两种类型的问题:对话和详细描述。问题生成流程: 对于对话数据,采用与第二阶段相同的自我指导数据生成流程。详细描述问题从一个固定的问题集中随机选择。参考预测与回答生成: 利用GPT-4进行参考预测,为教师模型设定上限答案。然后从另一个LMM生成相同问题的回答。回答评估: 利用GPT-4对两个助手(候选LMM和GPT-4)的响应进行评分,包括帮助程度、相关性、准确性和详细程度。并使用1到10的尺度给出总体得分,其中较高的分数表示更好的性能。相对得分通过使用GPT-4参考分数进行标准化计算。模型解释: 要求GPT-4提供对评估的全面解释,以更好地理解模型的表现。需要注意的是,GPT-4 通过考虑实际图像的地面真实标题和黄金行内提及来生成响应,而不是理解图像。虽然 LMMs 和 GPT-4 之间不是公平的比较,但 GPT-4 是一个一致且可靠的评估工具。
实验结果1:统计数据
尽管只完成了第一阶段的模型作为聊天机器人的表现不足,但是完成两个阶段培训的模型总体上优于通用LLaVA。其他结论包括:
实验结果2:对话样例
如下图所示的对话样例也可以看出LLaVA-Med模型与行内提及数据对模型性能的改善。相比之下,因为多模态GPT-4未公开,也与仅支持语言的GPT-4的回复进行了比较。
5.2 on
数据集描述
表三展示了测试使用的数据集数据详情,具体而言:
VQA-RAD: SLAKE: :
评估指标选择: 使用准确率评估封闭式问题,使用召回率评估开放式问题。开放式问题难度: 与文献中通常将训练集中的唯一答案作为答案候选项不同,作者采用更接近开放集性质的评估方法。评估方法的挑战: 由于对开放式问题的回应没有提供任何约束,因此这种评估方法可能更为困难,但也更全面。
在项目评估文件LLaVA-Med/llava/eval//.py中有如下几个评估指标:
BLEU Score: 使用n-gram权重计算BLEU分数,考虑了翻译结果和参考答案之间的匹配程度。BLEU是一种用于评估翻译结果的常见指标。Exact Match(精确匹配): 计算生成的答案与参考答案的精确匹配程度,即两者是否完全相同。 : 计算生成的答案与参考答案之间的相似性,考虑了候选答案和预测之间的共同词汇。 with : 考虑了生成的答案与参考答案之间的外观,通过归一化进行评估。F1 Score: 计算精确率()、召回率()和F1分数,用于综合评估生成的答案与参考答案之间的匹配程度。
with SoTA
LLaVA-Med与LLaVA和现有代表性方法的比较,结果如图4(a)所示,主要包括以下几个观点:
LLaVA-Med LLaVA: 所有LLaVA-Med的变体都表现优于LLaVA。在语言模型初始化方面,与LLaVA或相比,来自 CLIP的视觉编码器的初始化稍微优于来自一般领域CLIP的初始化。Fine- : 在关闭式问题上,LLaVA-Med的微调性能优于VQA-RAD和上监督学习的先进方法。这验证了LLaVA-Med在按照指令完成生物医学任务方面的强大能力,特别是当提供清晰的指令时(例如,是或否)。Open-Set : 在开放式问题上,LLaVA-Med在SLAKE上实现了SoTA,但在其他数据集上的表现有限,特别是与现有方法相比。这可能是因为开放式的生物医学问题可能存在歧义,而且难以限定其期望的答案选项。
论文的消融实验总结了在训练管道中考察了不同模型变体的性能以及对训练过程中的指导数据和超参数进行调整的影响,结果如图4(b)所示。主要几点发现如下:
LLaVA-Med相对于LLaVA的优越性: Stage 1训练的影响: Stage 2的指导数据的关键性: 下游数据集的微调和语言模型大小的影响:
训练时间
在§4中提到了训练成本,具体的数据如下。
同时作者发现在零样本的中文问题上模型也有不错的性能,可能原因是来自于LLaMA或者的知识,一些示例如下。
6
本文的主要贡献是推出了在生物医药领域适用的大语言视觉模型(large -and- model for the ),LLaVA-Med模型。
可能存在的缺陷和限制和寻常的大模型一样,主要包括幻觉和缺乏深度推理能力(in-depth )。
本文的主要贡献是推出了在生物医药领域适用的大语言视觉模型(large -and- model for the ),LLaVA-Med模型。
可能存在的缺陷和限制和寻常的大模型一样,主要包括幻觉和缺乏深度推理能力(in-depth )。
[1] Camel. , 2023. 2
[2] , Bai, Anna Chen, Dawn Drain, Deep , Tom , Andy Jones, , Ben Mann, Nova , et al. A as a for . arXiv arXiv:2112.00861, 2021. 1
[3] Malek Ayoub, Megan , Abdul- K Abdel-, Poe Lwin, and Megan K . Covid or not covid? a great the smoke . , 13(11), 2021. 5
[4] Bappy Basak, , , and Joyce . of the rib: A rare tumor with for local . , 13(10), 2021. 5 1
[5] Bazi, Al , Laila , and Zuair. model for in . , 2023. 3, 9
[6] , Jain, , Hafiz , and . - lung : An . , 12, 07 2020. 7
[7] , Naoto , , C , Anton , , Maria , , Nori, -Valle, et al. the most of text to – . In ECCV. , 2022. 2
[8] , , and De Melo. : How much does clip in the ? In of the for : EACL 2023, pages 1151–1163, 2023. 2, 3, 9
[9] Zhe Gan, Li, Li, Wang, Liu, Gao, et al. pre-: , , and . and ® in and , 2022. 1
[10] Yu Gu, Tinn, Hao Cheng, Lucas, Naoto , Liu, , Gao, and Poon. - model for . ACM on for (), 3(1):1–23, 2021. 2
[11] , Ana ́ c, , Kyle Lo, Iz , Doug , and Noah A Smith… Don’t stop : Adapt to and tasks. arXiv arXiv:2004.10964, 2020. 6
[12] Han, Lisa C Adams, Jens- , Paul , Tom , Löser, Truhn, and Keno K . –an open- of ai and data. arXiv arXiv:2304.08247, 2023. 2
[13] He, Zhang, Mou, Eric Xing, and Xie. : 30000+ for . arXiv arXiv:2003.10286, 2020. 3, 8
[14] Kexin Huang, Jaan , and . : notes and . arXiv arXiv:1904.05342, 2019. 2
[15] EW , Tom J , Seth J , R , P , Chih-ying Deng, Roger G Mark, and Horng. Mimic-cxr, a de- of chest with free-text . data, page 317, 2019. 2
[16] Jason J Lau, Gayen, Asma Ben , and Dina -. A of and about . data, 2018. 7
[17] Lee, Yoon, Kim, Kim, Kim, Chan Ho So, and Kang. : a pre- model for text . , 36(4):1234–1240, 2020. 2
[18] Peter Lee, , and Petro. , , and risks of gpt-4 as an ai for . New of , 388(13):1233–1239, 2023. 2
[19] Peter Lee, Carey , and Isaac . The ai in : Gpt-4 and . 2023. 2
[20] Lewis, Ethan Perez, , Fabio , , Naman Goyal, Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. - for - NLP tasks. , 2020. 3 1
[21] Li, Liu, Li, Zhang, Jyoti Aneja, Yang, Ping Jin, Hu, Liu, Yong Jae Lee, and Gao. : A and for - . In Track on and , 2022. 1
[22] Li, Gang Liu, Lin Tan, Liao, and Zhong. Self- for . arXiv arXiv:2211.13594, 2022. 3, 9
[23] Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. Slake: A - for . In on (ISBI). IEEE, 2021. 8, 10
[24] Liu, Li, Wu, and Yong Jae Lee. . arXiv arXiv:2304.08485, 2023. 1, 2, 4, 6
[25] Liu, Kilho Son, Yang, Ce Liu, Gao, Yong Jae Lee, and Li. with - . arXiv arXiv:2301.07094, 2023. 3
[26] Yunyi Liu, Wang, Dong Xu, and Zhou. : vqa via an . arXiv arXiv:2304.01611, 2023. 3, 9
[27] Pan Lu, , Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, , Peter Clark, and . Learn to : via for . in , 2022. 5
[28] Luo, Liai Sun, Xia, Tao Qin, Sheng Zhang, Poon, and Tie-Yan Liu. : pre- for text and . in , 2022. 2, 3
[29] , Abbas , , , and . of the : of a rare case. Case , 9(9):, 2021. 5
[30] Nori, King, Scott Mayer , Dean , and Eric . of gpt-4 on . arXiv arXiv:2303.13375, 2023. 2
[31] . . , 2022. 2
[32] . GPT-4 . , 2023. 1, 2
[33] A , , , , and . tear to . of Case , 11(9):7, 2021. 5
[34] Peng, Li, He, , and Gao. with GPT-4. arXiv arXiv:2304.03277, 2023. 2
[35] Roger Kevin and H Wyatt. The use of in : a of two cases of spine pain. & , 14(1):1–8, 2006. 4
[36] Alec , Jong Wook Kim, Chris , , Goh, , , , , Jack Clark, et al. from . arXiv arXiv:2103.00020, 2021. 9
[37] Alec , Wu, Rewon Child, David Luan, Dario , Ilya , et al. are . blog, 2019. 3 1
[38] Shih, Carol C Wu, S , Marc D Kohli, M , Tessa S Cook, Arjun , K , , Maya -, et al. the of chest with of . : , 2019. 2
[39] Chang Shu, Baian Chen, Liu, Zihao Fu, Ehsan , and Nigel . med-: A - llm with . 2023. 2
[40] Hugo , , , , Marie-Anne , ée , Rozière, Naman Goyal, Eric , Azhar, et al. Llama: Open and . arXiv arXiv:2302.13971, 2023. 3
[41] Tom van , Mahdi , Ivona , Cees GM Snoek, and . Open-ended of . arXiv arXiv:2303.05977, 2023. 3, 9
[42] A , J , and M . : a - large model for text. . : Dec, 23, 2022. 3
[43] . : An open- GPT-4 with 90%* . https: ///, 2023. 3, 6
[44] Wang, Chi Liu, Nuwa Xi, Zewen Qiang, Zhao, Bing Qin, and Ting Liu. : llama model with , 2023. 2
[45] Wu, Zhang, Ya Zhang, Wang, and Weidi Xie. Pmc-llama: llama on . arXiv arXiv:2304.14454, 2023. 2
[46] Xiong, Sheng Wang, Yitao Zhu, Zihao Zhao, Liu, Qian Wang, and Shen. : Fine- your is not a task. arXiv arXiv:2304.01097, 2023. 2
[47] Li , Li Zihan, Zhang Kai, Dan , and Zhang You. : A chat model fine-tuned on llama model using . arXiv arXiv:2303.14070, 2023. 2
[48] Zafar, Abdul Wahab , , Tila , Mark , , and Abdul . of : A case of a rare . , 13(12), 2021. 5
[49] Sheng Zhang, Yanbo Xu, Naoto , Bagga, Tinn, Sam , Rao, Mu Wei, , Cliff Wong, et al. Large-scale - for - . arXiv arXiv:2303.00915, 2023. 2, 3, 6, 9













