金融行业分布式数据库转型之路
分布式数据库是相对于集中式数据而言的,具备分布式数据管理能力的一种新型数据库软件产品。是面对高性能、大数据量业务系统,特别是无法进行大规模重构的业务系统,实现分布式能力引入的一种有效解决方案。分布式数据库具备数据分片管理、分布式事务、读写分离等关键分布式能力,能够为应用提供类似与集中数据库的使用方式,可以降低应用实施分布式改造的复杂度。近年来,各国产厂商都在积极推进分布式数据库产品的研发,技术已经逐步成熟,金融行业也已经有成功案例投入生产系统使用。本文尝试从多个角度,阐述金融行业分布式数据库转型所面临的问题及解决思考。
1. 背景:为何会走向分布式
人生基本上就是两件事,选题和解题。最好的人生是在每个关键点上,既选对题,又解好题。人生最大的痛苦在于解对了题,但选错了题,而且还不知道自己选错了题。正如人生最大的遗憾就是,不是你不行,而是你本可以。
1).业务驱动
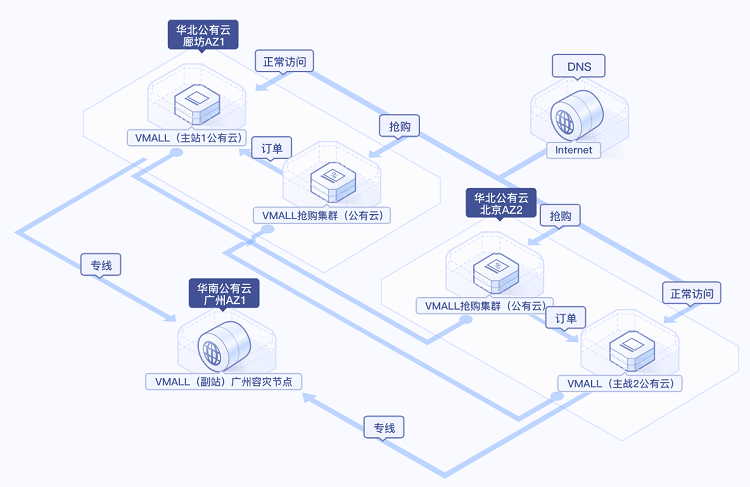
移动互联网和电子支付的蓬勃发展对金融系统能力带来全新的挑战
2).政策指导
《金融科技()发展规划(2019-2021)》中明确指出:“加强分布式数据库的研发应用。做好分布式数据库金融应用的长期规划,加大研发与应用投入力度。有计划、分步骤稳妥推动分布式数据产品先行先试,形成可借鉴、能推广的典型案例和解决方案,为分布式数据库在金融领域的全面应用探明路径。建立健全产学结合、校企协同的人才培养机制,持续加强分布式数据库底层和前沿技术研究,制定分布式数据库金融应用标准规范,从技术架构、安全防护、灾难恢复等方面明确管理要求,确保分布式数据库在金融领域的稳妥应用。”
2. 分布式可选技术路线
人生基本上就是两件事,选题和解题。最好的人生是在每个关键点上,既选对题,又解好题。人生最大的痛苦在于解对了题,但选错了题,而且还不知道自己选错了题。正如人生最大的遗憾就是,不是你不行,而是你本可以。
1).路线:分布式中间件+单机数据库
这类产品,一般采用了典型的“Share ”架构,实现存储与计算分离,通过上层无状态的计算节点提供弹性可扩展的计算能力,下层通过增强单机数据库提供基础存储能力及本地算力。这一架构通过硬件堆叠,可近似线性地提供计算性能和存储容量,具有可支持超大规模集群的能力。
❖ 产品优势
这一架构产品的优势在于功能丰富、可按业务做定制;稳定性较高,基于成熟稳定的单机引擎。在面对超大规模数据存储,通过灵活的分片配置策略,支持高灵活度数据打散技术,并可贴近场景需求定制分片。
❖ 产品劣势
相对不足在于全局事务能力、全局MVCC、副本控制、高可用等方面存在先天短板,需要有针对性增强。例如引入全局事务管理器组件,突破单机限制,实现分布式事务的实时一致性及全局MVCC能力,对应用透明的分布式事务处理,应用无需改造。通过一阶段提交+自动补偿机制,提升分布式事务处理性能。针对数据强一致性的要求,在单机库同步技术基础上,通过内核级的增强优化实现更高级别的复制保证数据不丢失。此外,由于需维护多节点一致性而带来的在跨分片DDL、分片节点扩容、跨节点复杂查询、全局一致的备份恢复等方面问题值得关注。
❖ 最佳实践
这种架构产品较为适用于数据规模巨大、对延迟要求很高的在线交易场景。在数据库设计时,需要特别注意分区键和分区策略的选择,合理布局数据,尽量避免跨节点的分布式事务处理,以提高数据库的效率。
2).路线:原生分布式数据库
这类产品,一般也是采用“Share ”架构,实现存储与计算分离。与上面不同的是,底层多采用自研或裸存储引擎,数据按规则打散并存储多个副本,通过paoxs/raft等分布式协议保证多个副本间数据一致。上层实现数据库基础的优化器、执行器等组件,对分布式事务、全局MVCC等支持更为彻底。此外,由于其底层的存储引擎不是依赖某一产品,可根据需要组织数据,因此在适配场景上更有优势,例如在某些分析类场景可选择列存。
❖ 产品优势
的原生实现,工程上不依赖其他产品,可控程度更高。面对很多新的需求,可从底层加以实现支持,不受限于第三方。在副本控制、数据一致性、容灾、弹性能力等方面更具有优势。此外,场景方面有更为灵活的选择及未来可扩展的空间。
❖ 产品劣势
产品成熟度,仍需较长时间沉淀。特别是使用在核心业务场景,仍然需要较长时间的锤炼。此外,其内置的分片规则,对于某些需贴合业务的架构设计不太友好。对于高并发、低延迟的极端场景仍然有一定局限。
3).路线:云原生数据库
在某种程度上讲,云原生数据库也是一种分布式,但与前两者区别是非Share 架构,而是Share 模式。其底层是与分布式云存储,本质上来说仍然是一种集中式架构。上层的计算部分,是无状态的一组结点组成。针对这种架构不足展开说明,原因是这种方式是需要对底座有比较重的依赖,无法在金融行业相对要求独立环境中部署,除非整个底层都更换。因此,使用选择上存在一定困难。
4).路线:业务自研+(开源)单机数据库
这一模式是在传统单机数据库的基础上,通过业务自研完成数据拆分。在处理上,尽量通过业务单元化方式,将数据集中在单元内完成;即使极少数需要跨单元,也可以通过应用层面解决事务类问题。
❖ 产品优势
优势很显然,底层基础设施不用修改,避免了引入新产品带来的风险及其他管理成本。可根据业务需求灵活定制,对底层依赖很小,未来的迁移、扩容等很从容。
❖ 产品劣势
最大的缺点无疑是成本及效率。由于其对业务有较大侵入性,需要投入较大的开发维护成本,当然也有些可改进的方式。如引入数据库中间件类的产品,将逻辑尽可能封装在底层,上层可更专注于业务开发。
5).技术路线对比
根据不同技术栈的特点,在不同场景上各有所擅长。下面简单总结的一些场景,当然不同企业在技术路线选择上,不仅仅会考虑技术特点,还要综合其他多种因素。
6).最佳实践:解耦路线依赖
通过数据库的技术标准化和轻量化工作,形成统一的数据库使用规范,解耦应用和底层数据库技术架构,在标准数据库协议及语义下,可以很轻松的更换数据库架构。通过构建异构间数据同步、流量接入控制(限流、灰度等)、全局数据服务(如事务、快照等),实现业务的无感切换和迁移回退,保证最大的灵活可控。
3. 技术路线选型路径
人生基本上就是两件事,选题和解题。最好的人生是在每个关键点上,既选对题,又解好题。人生最大的痛苦在于解对了题,但选错了题,而且还不知道自己选错了题。正如人生最大的遗憾就是,不是你不行,而是你本可以。
1).选型难点
银行在分布式数据库选型应用上也有几大难点:
2).选型要素
技术为业务服务的,不能为了使用技术而使用,需要综合考虑成本和收益的平衡。分布式数据库使用场景,应当在数据大规模、高并发、高可用性等场景下有其特有优势。一般的业务场景如果能用单机数据库支撑的尽量用单机库。选择一款分布式数据库,会带来一系列的成本,如应用适配成本、运维成本、硬件成本,这方面后面会赘述。此外,在做上述判断时,还需考虑业务的发展,最好是能判断三年的数据量和交易量的增长变化。
在进行分布式选型时,可重点考察下列几个方面:
3).选型依据
除了上述技术因素外,在选型中还需考虑系统运行现状,可重点参考下述指标:
4).资源评估
除了对运行时的各种因素评估外,作为底层技术基础设施的更换,还需要考虑基础资源的使用。分布式数据库通常会采用廉价x86 pc服务器,搭配本地ssd固态盘、万兆网卡,单体硬件成本较低。但在服务器数量上,需要有更多考虑。一方面分布式数据库组件众多,且每个组件都需要高可用配置,即使部分可采用混部方式解决,但在整体数量上仍然会较多。此外,还需要考虑各组件的负载模型不同、关键组件独立部署、数据多副本等等问题。另一方面,结合重点关注的性能数据、例如支持的QPS等,从而计算出服务器数量需求。需要注意的是,分布式数据库厂商提供的性能测试采用的服务器参数,一般是高配服务器,如果实际生产使用服务器配置降低,还则要考虑性能数据损耗等问题。
5).运维评估
作为 一种新型的数据库产品,对运维方面也会带来不小的工作。至少包含了以下一些方面:
4. 分布式转型成本分析
人生基本上就是两件事,选题和解题。最好的人生是在每个关键点上,既选对题,又解好题。人生最大的痛苦在于解对了题,但选错了题,而且还不知道自己选错了题。正如人生最大的遗憾就是,不是你不行,而是你本可以。
分布式转型,势必会带来一定的成本。这里尝试将可能带来的成本做个分析:
1).成本分析
这里我们将成本分解为几个方面:
2).方案成本对比
采用不同的技术路线,针对上述的成本投入是存在较大差异的。
韩锋频道: