Java进阶--深入解析hashmap
原理
先以一个简单的例子来理解的原理。在Java中先随机产生一个大小为20的数组如下:
hash表的大小为7,将上面数组的元素,按mod 7分类如下图:
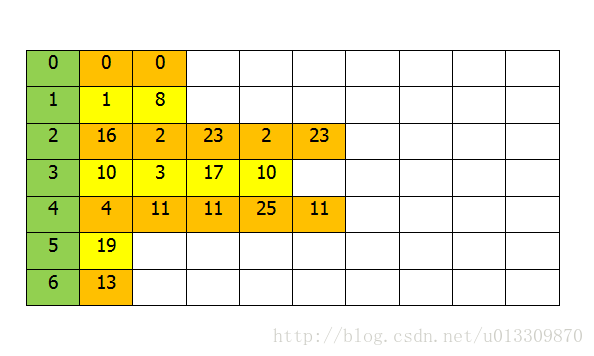
将这些点插入到中(简单)后如下图:
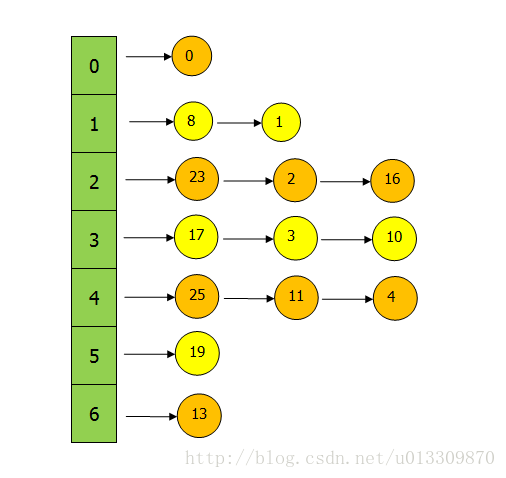
由上图可知:
① 是用链地址法进行处理,多个key 对应于表中的一个索引位置的时候进行链地址处理,其实就是一个数组+链表的形式。
② 当有多个key的值相同时,中只保存具有相同key的一个节点,也就是说相同key的节点会进行覆盖。
③在中查找一个值,需要两次定位,先找到元素在数组的位置的链表上,然后在链表上查找,在中的第一次定位是由hash值确定的,第二次定位由key和hash值确定。
④节点在找到所在的链后,插入链中是采用的是头插法,也就是新节点都插在链表的头部。
⑤在中上图左边绿色的数组中也存放元素,新节点都是放在左边的table中的,这个在上图中为了形象的表现链表形式而没有使用。
上面只是简单的模拟了 真实的的基本思想和上面是一样的不过更加复杂。中的一个节点是一个 类如下图:
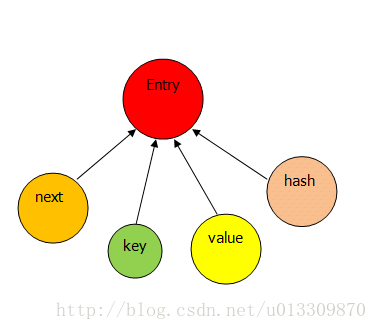
Entry是的内部类 包含四个值(next,key,value,hash),其中next是一个指向 Entry的指针,key相当于上面节点的值 value对应要保存的值,hash值由key产生,中要找到某个元素,需要根据hash值来求得对应数组中的位置,然后在由key来在链表中找Entry的位置。中的一切操作都是以Entry为基础进行的。的重点在于如何处理Entry。因此中的操作大部分都是调用Entry中的方法。可以说类本身只是提供了一个数组,和对Entry类中方法的一些封装。
下面从源码方面对 进行解析:
①的继承关系
public class HashMap<K,V>extends AbstractMap<K,V>implements Map<K,V>, Cloneable, Serializable从上面可以看到继承了 , 并且实现了, 接口。
②的构造函数
下面的代码都是经过简化处理的代码,基本流程不变只是为了更好的理解修改和删除了一部分内容
public HashMap(int initialCapacity, float loadFactor) {/*initialCapacity 初始化hashmap中table表的大小,前面的图中左边绿色部分的数组就是table。loadFactor填装因子。
*/if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);//如果初始化大小小于0,抛出异常 if (initialCapacity > 2^30)initialCapacity = 2^30;//HashMap 中table的最大值为2^30。 /* 生成一个比initialCapacity小的最大的2的n次方的值,这个值就是table的大小。table就是一个Entry类型的数组。*/int capacity = 1;while (capacity < initialCapacity)capacity <<= 1;table = new Entry[capacity];
//新建一个Entry类型的数组,就是前面图中左边的数组。不过数组的元素是Entry类型的。 }
上面的代码要做几点说明:
①填装因子: 表示填装因子的大小,简单的介绍一下填装因子:假设数组大小为20,每个放到数组中的元素mod 17,所有元素取模后放的位置是(0–16) 此时填装因子的大小为 17/20 ,装填因子就为0.85啦,你装填因子越小,说明你备用的内存空间越多,装填因子的选定,可以影响冲突的产生,装填因子越小,冲突越小。
②初始化过程就是新建一个大小为,类型为Entry的数组,Entry上面已经介绍过这个类,包含一个指针一个key,一个value,和一个hash。是2的次幂,至于为什么是2的次幂后面会有介绍的。
下面是另外两个构造函数
public HashMap(int initialCapacity) {HashMap(initialCapacity, 0.75);//调用了上面的构造函数,只不过使用了默认的填装因子0.75}public HashMap() {HashMap(16, 0.75);//生成一个table大小为16,填装因子0.75的HashMap}③由上可知如果用户直接使用()构造函数来new一个 会生成一个大小为16,填装因子为0.75的 。
③中的put(key,value)函数
还是先上源码
public V put(K key, V value) {if (key == null)return putForNullKey(value);
/*如果key为null则调用 putForNullKey(value) 函数 这个函数先在table[0]这条链上找有没有key 为null的元素如果有就覆盖,如果没有就新建一个new一个key为null,value=value hash=0,的Entry放在table[0]。
*/ int hash = hash(key);
//获得key的hash值 int i = indexFor(hash, table.length);
//由hash值确定放在table表中的那一条链上。类似于取模后放在数组中的哪个位置。 for (Entry e = table[i]; e != null; e = e.next) {Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;//如果链上原来有一个hash值相同,且key相同的则用新的value值进行覆盖。 }}
//否则利用hash,key,value,new一个Entry对象插入到链表中。modCount++;addEntry(hash, key, value, i);return null;} 对上面代码做几点说明:
① 中的key可以为 null ,此时hash=0,为什么key可以为null,因为中放的元素是Entry,而Entry包含了4个值(key,value,hash,next),key为 null 时不影响Entry映射到中。
②hash(key),产生一个正整数,这个整数与key相关。这个hash(key)函数比较关键,后面会进行说明。
③用户插入的(key,value)对不是直接放到中的,而是用(key,value)以及后面由key value产生的hash,new一个Entry对象后再插入到中的。
④如果对应的链上有一个hash值个key相同的Entry则覆盖value值,不new Entry对象,如果没有会先new 一个对象在将其插到对应的链上。(其中可能会涉及到扩充)。
下面看看hash(key)函数
final int hash(Object k) {int h = 0;h ^= k.hashCode(); //hashCode 返回一个整数值,这个值跟对象有关,不同对象的hashCode值一般不同。 h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);}
hash函数的作用是使里面的元素位置尽量的分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,而不用再去遍历链表。
④中的get( key)函数
上源码
public V get(Object key) {if (key == null)return getForNullKey();
//如果key==null则在table[0]这条链上找,如果找到返回value值,否则返回null ,因为key==null的都是放在table[0]这条链上的。 Entry entry = getEntry(key);
// getEntry(key)先key的hash值找到在数组的哪条链上,然后在链上查找key相同的如果没找到返回null
//如果找到了返回Entry的value值。 return null == entry ? null : entry.getValue(); }private V getForNullKey() {for (Entry e = table[0]; e != null; e = e.next) {if (e.key == null)return e.value;}return null;}Entry getEntry(Object key) {int hash = (key == null) ? 0 : hash(key);for (Entry e = table[indexFor(hash, table.length)];e != null;e = e.next) {Object k;if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;}return null;} 上面代码的几点说明
① 通过key来链表中查找元素包括两个过程,先由hash找到链(hash由key产生,不同的key可能产生相同的hash值,相同的hash值放在同一条链上),再用key在链上找。
② 如果key为null则只在table[0]和其链上查找,因为key为null都放在table[0]及其链上了。
③因为在中查找到的是Entry对象,返回的值是Entry对象的value值。
重点Entry类
其实理解最重要的在于理解Entry类,Entry类相当于链表中的一个节点,是操作的基础。下面主要从Entry类的几个方法来理解Entry类和的关系。
①Entry中的( hash, key, value, )函数
在中调用put(key,value)时,如果(key,value)是首次加入到中,就会调用
( hash, key, value, )函数,将其加入到table表对应的位置中(注意是table中,不是后面的链中,首次加入的元素都是采用的头插法)。下面是源码:
void addEntry(int hash, K key, V value, int bucketIndex) {if ((size >= threshold) && (null != table[bucketIndex])) {resize(2 * table.length);//如果size的值超过了threshold,将table扩容两倍hash = (null != key) ? hash(key) : 0;//如果key为null则hash=0,否则hash函数利用key来产生hash值。bucketIndex = indexFor(hash, table.length);//bucketIndex就相当于取模后对应的table表中的哪个位置。}//如果不存在容量不够问题则直接新建一个Entry对象。 createEntry(hash, key, value, bucketIndex);}void createEntry(int hash, K key, V value, int bucketIndex) {Entry e = table[bucketIndex];//获得原来首位的Entry对象table[bucketIndex] = new Entry<>(hash, key, value, e);//将新建的Entry对象放在链表的首位,然后用next指向原来放在首位的对象。也就是头插。size++;}
上面代码的几点说明:
①是由hash取模后对应于table表中的哪个位置。(hash, table.)其实是一个取模函数。它的实现很简单 hash& (-1),就是用hash值与上table表的长度减1。
②并不是对每一个(key,value)对都产生一个Entry对象,只是(key,value)对首次放到中时,或者中没有相同的key时,才产生一个Entry对象,否则如果有相同的key则会直接将value值赋个Entry的value。
③新产生的Entry都是放在了table中,也就是链表的首位,采用链表的头插法。
②中的()函数
作用:返回中key的集合。是中的内部类:
public Set keySet() {Set ks = keySet;return (ks != null ? ks : (keySet = new KeySet()));//如果keyset为null就产生一个keyset对象。}private final class KeySet extends AbstractSet {public Iterator iterator() {return newKeyIterator();//newKeyIterator迭代器用于遍历key。}public int size() {return size;//返回keyset的大小}public boolean contains(Object o) {return containsKey(o);//是否包含某个key}public boolean remove(Object o) {return HashMap.this.removeEntryForKey(o) != null;//移除某个key的Entry。}public void clear() {HashMap.this.clear();}}
是用来遍历整个的,因此是十分重要的,下面做几点说明。
①中有一个迭代器可以迭代的获取下一个key的值,通过key的值就可以获得Entry对象了。
②对应key的迭代遍历是table表中由左向右,由上向下进行的,也就是先遍历table[0]这条链上的,然后遍历table[1]这条链上的依次往下进行。
③具体实现这里就不多介绍,只要知道上面的功能怎么实现就可以了。
下面是利用来实现遍历的例子:
HashMap<Integer, Integer> hashMap=new HashMap<Integer, Integer>(); for(int i=0;i<20;i++){hashMap.put(i, i+1);}//新建一个hashmap往里面放入20个(key,value)对。Iterator<Integer> iterator= (Iterator<Integer>) hashMap.keySet().iterator();//获得keyset的iterator,进行遍历整个hashmap。while(iterator.hasNext()){Integer key=(Integer) iterator.next();Integer val=(Integer)hashMap.get(key);System.out.println(key+": "+val);}②中的()函数
作用:返回中Entry的集合。对于这里就不上源码了,举一个使用遍历的例子:
HashMap hashMap=new HashMap(); for(int i=0;i<20;i++){hashMap.put(i, i+1);}Iterator> iterator=hashMap.entrySet().iterator();while(iterator.hasNext()){Entry entry= iterator.next();System.out.println(entry.getKey()+": "+entry.getValue());} 使用()函数遍历比()函数遍历快,因为()函数是先通过()求出key然后在通过key来遍历获得Entry的,所以速度比()慢很多。
参考文献:
①
②