文本生成图像工作简述1--概念介绍和技术梳理
一、相关概念介绍 1.1、多模态机器学习
模态是指某件事情发生或经历的方式。每一种信息的来源或者形式,都可以称为一种模态。人类对世界的体验是多模态的例如触觉,听觉,视觉,嗅觉;而人类获取信息的媒介,有语音、视频、文字等;
为了让人工智能在理解我们周围的世界方面取得进展,它需要能够一起解释这种多模态信号。多模态机器学习旨在建立能够处理和关联来自多种模态的信息的模型。
这是一个日益重要和具有非凡潜力的充满活力的多学科领域。
基于近年来图像处理和语言理解方面的技术突破,融合图像和文本处理的多模态任务获得了广泛的关注并取得了相当大的成功,例如基于视觉的指代表达理解和短语定位、图像和视频字幕生成、视觉问答(VQA)、基于文本的图像生成(文本生成图像)、基于语言的视觉推理等。
1.2、文本生成图像
如果我们的计算机视觉系统要真正理解视觉世界,它们不仅必须能够识别图像,而且必须能够生成图像。
文本到图像的 AI 模型仅根据简单的文字输入就可以生成图像。用户可以输入他们喜欢的任何文字提示——比如,“一只可爱的柯基犬住在一个用寿司做的房子里”——然后,人工智能就像施了魔法一样,会产生相应的图像。
这些模型产生的图像在世界上和任何人的想象中都从未存在过。它们是新颖的创作,其独创性和复杂性令人叹为观止。
文本生成图像(text-to-image)即根据给定文本生成符合描述的真实图像,其是多模态机器学习的任务之一,具有巨大的应用潜力,如视觉推理、图像编辑、视频游戏、动画制作和计算机辅助设计。除了传授深刻的视觉理解,生成逼真图像的方法也可以是实际有用的。在短期内,自动图像生成可以帮助艺术家或平面设计师的工作。有一天,我们可能会用生成定制图像和视频的算法来取代图像和视频搜索引擎,以响应每个用户的个人喜好。
1.3、零样本学习
基于深度学习的模型近年来在图像识别和对象检测等很多问题上已经达到或超过了人类水平。然而,这些模型依赖于监督学习,其性能在很大程度上取决于带标注的训练数据。此外,模型局限于识别训练时见过的类别。
零样本学习 Zero-Shot 就是用来解决这一问题的,其致力于让计算机模拟人类的推理方式,来识别从未见过的新事物。在传统的图像识别算法中,要想让计算机认出斑马,往往需要给计算机投喂足够量的斑马图像才有做到。而且,训练出来的分类器,往往无法识别它没有见过的其他类别的图像。
但是人类却可以依据斑马的先验知识,在没见过斑马的情况下识别出斑马,零样本学习就是希望能够模仿人类的推理过程,使得计算机具有识别新事物的能力。
文本生成图像模型的预期最佳效果也是零样本学习的文本生成图像,即具有迁移性,在没有提供新事物数据的情况下,只凭特征描述就能生成出新事物。
二、技术梳理 2.1、生成对抗网络:GAN
文本编码器 + 生成器 + 鉴别器的结构。文本编码器由RNN或者Bi-LSTM组成,生成器可以做成堆叠结构或者单阶段生成结构,主要用于在满足文本信息语义的基础上生成图像,鉴别器用于鉴别生成器生成的图像是否为真和是否符合文本语义。整个训练过程都是两者不断地进行相互博弈和优化。生成器不断得生成图像的分布不断接近真实图像分布,来达到欺骗判别器的目的,提高判别器的判别能力。判别器对真实图像和生成图像进行判别,来提高生成器的生成能力。
Reed等人是第一个扩展条件GAN以实现文本到图像合成的人。由于GANs在图像合成方面的进步,该任务在采用堆叠架构、循环一致性、注意力机制、对利用条件仿射变换方面取得了重大进展。如:
堆叠结构:、++、HDGAN;循环一致性:PPGN、、;注意力机制:、SEGAN、、;条件仿射变换:DFGAN、SSGAN、;…
感兴趣可以深入查看专栏:文本生成图像专栏
2.2、扩散模型 : Model
不同于 VQ-VAE,VQ-GAN,扩散模型是当今文本生成图像领域的核心方法,当前最知名也最受欢迎的文本生成图像模型 ,Disco-,Mid-,DALL-E2 等等,均基于扩散模型。
在扩散模型中,主要有两个过程组成,前向扩散过程,反向去噪过程,前向扩散过程主要是将一张图片变成随机噪音,而逆向去噪过程则是将一张随机噪音的图片还原为一张完整的图片,原理:由浅入深理解扩散模型( Model)
扩散过程从右向左( X 0 = > X t X_0 =>X_t X0=>Xt)对图片逐渐加噪, X 0 X_0 X0表示从真实数据集中采样得到的一张图片,当t足够大时, X t X_t Xt变为高斯分布。其本质就是在原始图像上添加噪音,通过 T 步迭代,最终将原始图片的分布变成标准高斯分布 ,而重要的事,每一步噪音都是已知的,即 q ( X t ∣ X t − 1 ) q(X_t | X_t-1) q(Xt∣Xt−1)是已知的(因为知道图像t-1,知道噪声数据),根据马尔科夫过程的性质,可以递归得到 q ( X t ∣ X 0 ) q(X_t |X_0) q(Xt∣X0),得到 X t X_t Xt。
逆扩散过程从左向右( X t = > X 0 X_t =>X_0 Xt=>X0)对图片逐渐降噪,如果我们能够在给定 X t X_t Xt条件下知道 X t − 1 X_{t-1} Xt−1,我们就可以逐步从 X t X_t Xt推出 X 0 X_0 X0,即就可以从噪声推导出一张图像。要达到这种,我们要知道 q ( X t ∣ X t − 1 ) q(X_t | X_t-1) q(Xt∣Xt−1),即如何从任意一张噪声图片中经过一次次的采样得到一张图片而达成图片生成的目的。显然我们很难知道 q ( X t ∣ X t − 1 ) q(X_t | X_t-1) q(Xt∣Xt−1),于是我们使用 p ( X t ∣ X t − 1 ) p(X_t | X_t-1) p(Xt∣Xt−1)来近似 q ( X t ∣ X t − 1 ) q(X_t | X_t-1) q(Xt∣Xt−1), p ( X t ∣ X t − 1 ) p(X_t | X_t-1) p(Xt∣Xt−1)就是我们要训练的网络。我们可以使用 q ( X t ∣ X t − 1 ) q(X_t | X_t-1) q(Xt∣Xt−1)来指导 p ( X t ∣ X t − 1 ) p(X_t | X_t-1) p(Xt∣Xt−1)的训练,在完成训练之后,训练好的模型就可以通过不断的「减去」模型预测的噪音,完成逆扩散步骤,逐渐的生成一张完整的图片。
直观上理解,扩散模型其实是通过一个神经网络 ,来预测每一步扩散模型中所添加的噪音。
扩散模型在实现文本生成图像任务中,主要有以下策略:
(以文本描述作为语义引导)通过使用引导函数来注入语义输入(此时文本可以看成一种分类器或者判别器),以指导无条件扩散模型的采样过程,这使得扩散模型中的生成更加可控,并为语言和图像引导提供了统一的公式。在逆向过程的每一步,用一个文本条件对生成的过程进行引导,基于文本和图像之间的交叉熵损失计算梯度,用梯度引导下一步的生成采样
-Free :前文额外引入一个网络来指导,推理的时候比较复杂,且将引导条件作为模型的输入效果其实一般。-Free 核心思路是共同训练有条件和无条件扩散模型,并发现将两者进行组合,可以得到样本质量和多样性之间的权衡。这个方法一个很大的优点是,不需要重新训练扩散模型,只需要在前馈时加入引导既能实现相应的生成效果。应用有:GLIDE、DALL·E 2、等… 2.3、基于的自回归方法
模型利用其强大的注意力机制已成为序列相关建模的范例,受GPT模型在自然语言建模中的成功启发,图像GPT(iGPT)通过将展平图像序列视为离散标记,采用进行自回归图像生成。生成图像的合理性表明,模型能够模拟像素和高级属性(纹理、语义和比例)之间的空间关系。整体主要分为和两大部分,利用多头自注意力机制进行编码和解码。但其训练成本高,推理时间较长,且强大而有趣的模型一直未开源。
在实现文本生成图像上,大概有以下策略:
和VQ-VAE(矢量量化变分自动编码器)进行结合,首先将文本部分转换成token,利用的是已经比较成熟的模型;然后将图像部分通过一个离散化的AE(Auto-)转换为token,将文本token和图像token拼接到一起,之后输入到GPT模型中学习生成图像。训练后,在处理文本图像生成类任务时,模型会通过计算一个 Score对生成图像进行排序,从而选择与文本最为匹配的图像作为结果:如
和CLIP结合。首先对于一幅没有文本标签的图像,使用 CLIP 的图像编码器,在语言-视觉(-)联合嵌入空间中提取图像的 。接着,将图像转换为 VQGAN 码本空间( space)中的一系列离散标记(token)。也就是将图像以与自然语言相同的方式进行表示,方便后续使用 进行处理。其中,充当 image 角色的 VQGAN 模型,可以使用手里的无标记图像数据集进行训练。最后,再训练一个自回归 ,用它来将图像标记从 的语言-视觉统一表示中映射出对应图像。经过这样的训练后,面对一串文本描述, 就可以根据从 CLIP 的文本编码器中提取的文本嵌入(text )生成对应的图像标记(image )了。如:CLIP-GEN、DALL·E、DALL·E 2
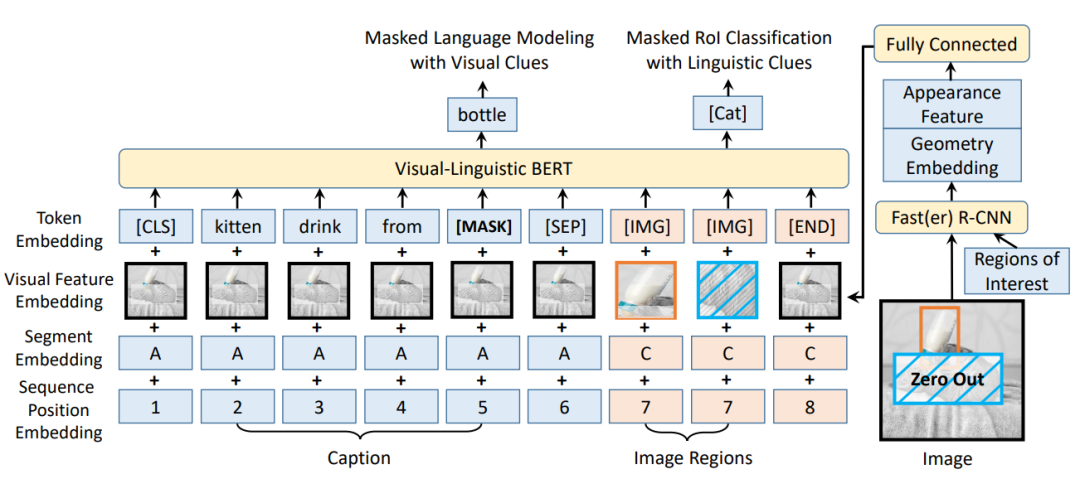
… 2.4、基于对比的图片-文本的跨模态预训练模型:CLIP
CLIP( -Image Pre-,简称 CLIP) 模型严格来说是一种辅助模型,是 在 2021 年初发布的用于匹配图像和文本的预训练神经网络模型,CLIP 最初是一个单独的辅助模型,用于对 DALL·E 的结果进行排序。
对比模型可以给来自同一对的图像和文本产生高相似度得分,而对不匹配的文本和图像产生低分。
该模型由两个编码器组成:一个用于文本,另一个用于图像:
图像编码器:用于将图像映射到特征空间;
文本编码器:用于将文本映射到相同的特征空间。
原理其实很简单:为了对image和text建立联系,首先分别对image和text进行特征提取,image特征提取的可以是系列模型也可以是VIT系列模型,text特征提取目前一般采用bert模型,特征提取之后,由于做了,直接相乘来计算余弦距离,同一pair对的结果趋近于1,不同pair对的结果趋近于0,因为就可以采用对比损失loss(info-nce-loss),熟悉这个loss的同学应该都清楚,这种计算loss方式效果与batch size有很大关系,一般需要比较大的batch size才能有效果。
CLIP可以理解成一种多模态 方式,为文本和图像在特征域进行对齐。
但CLIP采取了4亿的图像文本对的数据集,但这4亿的图像文本对并未对外开源,且CLIP是通过庞大的数据集来尽可能的覆盖下游任务,而它在未见过的数据上表现非常不理想,其不非常侧重算法上的创新,而是采集了大量的数据以及使用了大量的训练资源(592 个 V100 + 18天 和 256 个 V100 + 12天)。
CLIP主要作为辅助模型在文本生成图像中应用,比如GAN+CLIP(如)、 Model +CLIP (如GLIDE、DALL·E )、+CLIP(如CLIP-GEN、DALL·E 2)
参考
What are ?:扩散模型( Model)——由浅入深的理解基于扩散模型的文本引导图像生成算法:扩散模型与其在文本生成图像领域的应用:连接文本和图像的第一步:CLIP: 下一篇
文本生成图像工作简述2–常用数据集汇总与分析
最后
我们已经建立了T2I研学社群,如果你对本文还有其他疑问或者对文本生成图像方向很感兴趣,可以点击下方链接或者私信我加入社群。
加入社群 抱团学习:中杯可乐多加冰-采苓AI研习社
限时免费订阅:文本生成图像T2I专栏
支持我:点赞+收藏⭐️+留言