training on Fashion Domain
1.介绍
如图a所示,该模型可以用于时尚杂志的搜索。我们提出了一种新的VL预训练体系结构(- bert),它由 Patch (KPG)、基于注意的对齐生成器(AAG)和对齐引导掩蔽(AGM)策略组成,以学习更好的VL特征。-BERT在标准的公共-Gen数据集上实现了最先进的技术,并部署到在线系统(a)。
我们提出了一种新的视觉语言(VL)预训练模型,称为 - bert,它引入了一种新的策略来实现的跨模态表示。与近年来VL模型的随机掩蔽策略相比,我们设计了对齐引导掩蔽策略来共同关注图像与文本的语义关系。为此,我们开展了五项新任务,i.e., , , , grey-to-color, and blank-to-color for self- VL pre- at of scale.该模型十分容易进行扩展,它在四个下游任务上取得了最先进的成果文本检索(R@1: 4.03% )图片检索(R@1: 7.13% abs imv.)类别识别(ACC: 3.28% abs imv.) (Bleu4: 1.2 abs imv.)我们在各种电子商务网站上验证了-BERT的有效性,证明了它在现实世界应用中的广阔潜力。之前的文本图片模型都着重学习文本和图片的表征,
这些技术将有利于一般的跨模态表示学习。
2.相关工作
然而,在各种电子商务环境中(例如,配件、服装、玩具),主要目标是学习细粒度的表示(例如短袖、棉质和针织衫),而不仅仅是一般领域中的粗粒度表示(what、where)。在这种情况下,当前的通用VL模型对于基于时尚的任务是次优的,当将基于全局特征的模型部署到属性感知任务中,如搜索特定的时尚标题,可能不太理想。从图像和文本中提取细粒度特征或相似性至关重要。
在本文中,我们提出了一种新颖的任务框架。其核心思想是专注于细粒度的表示学习,并在文本和图像之间架起语义的桥梁。为了实现这一目标,我们首先引入了一种有效的策略,提取一系列的多纹理图像块来实现图像的模态。因此,我们的模型被命名为- BERT。该策略是可扩展的,通过引入补丁变体的训练前方案,在很大程度上缓解了前面提到的粗糙表示问题。此外,为了弥合不同模式之间的语义鸿沟,采用注意机制构建 patch与文本标记之间的预对齐。这些预对齐信息进一步指导了预训练的掩蔽策略。-BERT1被迫明确地学习跨模态的语义信息。总之,我们的贡献如下:
Patch :我们提出了策略来生成一个多粒度特征的。-BERT模型能够学习细粒度的跨模态信息,并在领域优于基于固定patch或RoI的VL模型。
-based : - BERT引入了预对齐策略来推断 patch和文本标记之间的交叉模态映射。这些预先对齐的对很大程度上填补了模式之间的语义空白。
:我们提出了一种对齐引导的掩蔽策略来明确地迫使-BERT学习视觉和语言之间的语义联系。实验结果表明了基于注意的预对准和掩蔽策略的重要性。
许多跨模态的视觉-语言前训练模型(如视频/图像和文本对)已经被设计出来。对于视频-文本对模型,CBT和是研究训练前学习能力的重要工作。
of in VL pre- . T = Task. W = Word. V = Token. L = Label. E = . Trm = Block.
and HERO关注下游任务应用,而UniVL则专注于视频语言的理解和生成任务。对于图像-文本对模型,根据单模态输入的网络结构,可以分为单流和双流,甚至三流。在单流模型中,不同模式的特性直接输入。相比之下,在两流模型中,它们首先由两个单模态网络处理,然后馈送到中,在三流模型中如此。
在单流模型中,不同模式的特性直接输入。相比之下,在两流模型中,它们首先由两个单模态网络处理,然后馈送到中,在三流模型中如此。认为双流结构优于单流结构,而VL-BERT发现单流模型取得了更有前景的结果,因为这些模型具有更多的跨模态信息交互。Vi- 和B2T2是单流模型,推导出统一的VL理解网络。 - vl,VLP,ViL- BERT,VL-BERT都是在BERT框架下提出的。与泛型任务(如VCR,VQA)的激增形成对比。
-BERT研究的是层面的掩蔽策略,而不是任务层面的掩蔽策略,现有的VL模型主要侧重于相对粗糙的表示,而较少关注基于任务的细粒度表示学习。有两个并行的研究类似于我们的工作。是第一个在领域发表的作品。并行研究MAAF旨在提出一种模式不确定的注意融合策略来处理无区别的文本和图像查询任务。与利用patch固定掩蔽策略不同,MAAF采用图像级注意机制。我们认为,这两种模式限制了预训练表征学习的能力,特别是对于细粒度的时尚任务。因此,迫切需要一种更灵活的patch变体解决方案。据我们所知,- BERT是第一个通过联合更多地关注域的图像-文本一致性来提出对齐引导掩蔽的有效性的方法。
3. -BERT
在本节中,我们将介绍-BERT,它将学习 的细粒度VL特性,而不是VL任务的粗粒度表示特性。我们采用为NLP设计的标准,使我们的-BERT可扩展到不同数量的基于的VL学习任务。
- bert算法分为五个阶段:
(1)- bert算法采用两种输入方式:文本(如图像标题或描述)和 (KPG)生成的相应图像。与类似,每个文本都表示为一个标记序列,而每个图像都表示为一个 patch序列。
(2)在阶段,我们提出了基于注意的对齐生成器(AAG)来生成文本标记和 之间的预对齐,从而实现图像和文本的显式语义对齐。
(3)与现有的随机掩蔽策略不同,我们提出了一种对齐引导掩蔽(Align- ment , AGM)策略来缓解交叉模态建模的困难。
(4)文本标记与 - bert完全交互, - bert逐步学习VL语义信息并生成跨模态的细粒度表示。
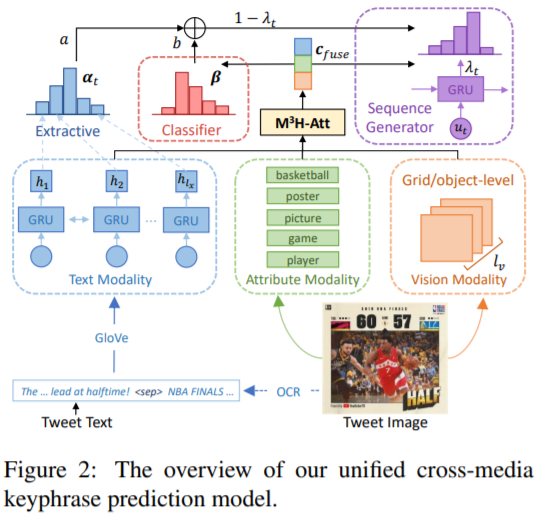
(5)最后,在mask语言建模和图像-文本匹配的基础上,我们采用了5个新的任务(i.e., , , camou- , grey-to-color and blank-to-color tasks )来监督网络。我们的实现是基于 /库。
3.1 Patch
在给定一幅图像作为输入的情况下,我们通过提出的 Patch (KPG)获得多粒度的Patch,我们可以引入一个显著性检测网络4(如BAS,EGNet,ICON或近期论文中的其他sota)来获取前景掩码,我们将图像分割成不同的尺度(这些图像patch就像 一样,可以根据具体任务的难度考虑更详细的划分(例如像Pixel-BERT那样的6*6或N*N)。最后,从每幅输入图像中得到55个 。为了生成这些的,我们使用了标准-50作为我们的主干。
3.2 -based
基于注意的对齐生成器(AAG)旨在找到文本标记之间的粗对齐和 ,同时SAT网络对每个token生成 heat-map由此我们可以推断出所生成的标记与图像区域之间的关系。利用生成的标记与原始文本标记的共现,以及图像区域与 的重叠区域,进一步构建原始文本标记与 的对齐。
3.3
启发我们修改the 的主要思想是,预对齐的〈token, patch〉对提供了两种模式之间的显式语义关系。这种对齐可以在训练前阶段使用,这进一步迫使-BERT显式地探索跨模态语义信息。与随机掩蔽策略不同,对齐引导掩蔽(AGM)为掩蔽预对齐对提供了较高的优先级。同时,对于每个选定的预对齐的〈token, patch〉对,我们随机掩模token部分或patch部分,这将刺激-BERT通过提供另一种方式的信息来学习缺失的信息。当遍历所有预对齐对且标记或patch数量不足时,采用随机屏蔽策略对未对齐标记和补丁进行独立屏蔽。通过这种方式,我们获得了token和patch掩码候选项。AGM策略作用于 的level-3、level-4、level-5。(1,2不同)
再进行一层归一化(LN)层。对于图像一侧,我们通过将其重新组织为每个patch的5D特征([x1, x2, y1, y2, w∗h])来编码位置信息。在此之后,patch和位置特征都被输入到完全连接(FC)层,以便将它们投射到相同的空间中。我们通过将三个FC输出(即FC (seg id),FC (img ),FC (pos emb))相加,获得每个patch的视觉嵌入,然后将它们通过LN层。
3.4Pre- -BERT
为了缓解VL语义差距,提高特征表示,我们设计了3个训练前任务,即对(AMLM)、图像与文本匹配(ITM)和提出的对齐 Patch建模(AKPM)(包含5个子任务)来监督我们的- bert。
3.4.1 AMLM
我们可以获得掩码候选,包括token和patch候选。在确定掩蔽指标后,我们将掩蔽词分解为随机的10%、不变的10%和80%。
式中CE为交叉熵损失。F是- BERT函数。F(·)MSK 表示掩码标记的隐藏输出。K为掩膜后的 patch序列。
3.4.2 ITM
ITM任务通过下一个句子预测(NSP)通过 BERT我们使用函数来预测分数在0到1之间。从同一款产品中抽取一个正面样本的文字和图像,而从不同的产品中随机抽取一个反面样本的文字和图像。
其中,ym表示文本和图像匹配标签。
3. (RR)旋转
对于1*1层级(记为K1)的patch,将原图片随机旋转一个角度{0°90°,180°,270°},让模型预测旋转的角度(4分类任务)。训练过程中,将K1图像块经过模型编码后的输出经过一个全连接层+激活函数,做四分类,损失函数如下:
yr the angle
3.6拼图
将这4个patch的顺序打乱作拼图,视为分类任务,让模型预测顺序,因为打乱后一共有4!=24种顺序,所以相当于做24分类。这个任务能挖掘patch之间的空间关系。
其中yj为拼图排列。
3.7伪装
对于3*3层级(记为K3)的patch,用来自其它商品的一个patch伪装在正常的patch中,让模型判断哪个patch被替换过(9分类任务)。该任务能增加模型的识别能力。
Yc为伪装patch的索引。
3.8着色
在现有的图片特征掩码策略中,一般直接用零向量来替换被掩码的特征,这里作者提出了一种更加平滑的方法,就是将被掩码的图片块置为灰色,做灰度图特征到彩色图特征的重构。该任务有利于多模态模型在图像侧的自监督学习。
损失函数采用KL散度,最小化重构后的特征和原始特征之间的差异:
训练阶段,图片端不同的子任务在验证集上的损失变化曲线。可见损失函数下降的比较平稳,预训练过程正常进行,说明所设计的预训练任务能够很好地学习。
4.实验
和一样,本文在-Gen数据集上进行了所有实验。该数据集包含67,666个带文本描述的时尚产品,其中260,480个图片-文本对用于训练、35,528个图片-文本对用于测试。
本文设置了四个下游任务:文本检索(ITR)、图像检索(TIR)、类目/子类目预测(CR & SUB)、时尚描述(FC)。其中,预测商品的类目和子类目是一个分类任务,{, }, {, PANTS}就是2个{类目、子类目}例子。
(1)-BERT几乎在所有指标上都取得较大的性能提升,证明了它在时尚领域卓越的理解和生成能力。主要是本文提出的三个创新点充分挖掘了图像模态的语义信息。
(2)方法相较于[60]与[45]有更好的表现,是因为它使用了图像patch特征,而不是RoIs特征。
(3)和OSCAR两个预训练模型比和更好,这四个模型用的都是RoIs特征,但是后面两个额外使用了对应的区域类别标签,在图像端利用了更多信息,所以表现更好一些。
消融实验
1)在输入端,探究多粒度图像块生成模块(KPG)的作用
作者对比了三种生成patch的方法:固定尺寸切割(Scale-fixed)、多尺寸切割(.)、本文提出的多尺寸切割+显著性检测(.+SOD)。我们可以从表格中看到本文提出的图像块生成方法表现最好,这是因为多尺寸的切割能更好地捕捉到图像细粒度表征,进一步引入显著性检测避免了切分块出现大量空白。
从表中,我们可以看到AGM策略能明显提升模型效果,这是因为它考虑了模态间的语义关联,优先掩码预对齐的对,能让-BERT更好地理解多模态信息。