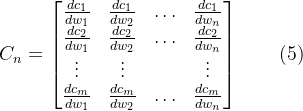3.3 PointNet layer
目录
.0 前言
.1
.2
2.1Set (SA)
.3 of
3. layer
3.
3. layer
3.4分类任务在提取特征后是怎么操作的,loss是什么
3.5分割任务中如何进行上采样, loss是什么?
3.6以解析++网络中维度和尺寸是怎么变化的 ?
3.++中的一些其它问题
:
如论文中++网络架构所示, ++的(, 特征学习)主要是由set 组成, set 由 , 和组成; 对于分类任务(下图中下面分支), 则是由全连接层组成;对于分割任务,部分主要由上采样(), skip link , 组成
.0 前言
不足之处
在卷积神经网络中,3D CNN和2D CNN很像,也可以通过多级学习不断进行提取,同时也具有着卷积的平移不变性。
具体见:CNN平移不变性_啥也不是的py人的博客-CSDN博客
而在中 网络对每一个点做低维到高维的映射进行特征学习,然后把所有点映射到高维的特征通过最大池化最终表示全局特征
(因为直接抽取全局特征mlp映射到高维)从本质上来说,要么对一个点做操作,要么对所有点做操作,实际上没有局部的概念(loal )
同时也缺少local 在平移不变性上也有局限性。(世界坐标系和局部坐标系)。对点云数据做平移操作后,所有的数据都将发生变化,导致所有的特征,全局特征都不一样了对于单个的物体还好,可以将其平移到坐标系的中心,把他的大小归一化到一个球中,但是在一个场景中有多个物体时则不好办,需要对哪个物体做归一化呢?
.1
在++中,作者利用所在空间的距离度量(L2范数)将点集划分()为有重叠的局部区域。
在此基础上,首先在小范围中从几何结构中提取局部特征(浅层特征),然后扩大范围,在这些局部特征的基础上提取更高层次的特征,直到提取到整个点集的全局特征。
可以发现,这个过程和CNN网络的特征提取过程类似,首先提取低级别的特征,随着感受野的增大,提取的特征level越来越高。
++需要解决两个关键的问题:
1. 如何将点集划分为不同的区域;
2. 如何利用特征提取器获取不同区域的局部特征。
这两个问题实际上是相关的,要想通过特征提取器来对不同的区域进行特征提取,需要每个分区具有相同的结构。这里同样可以类比CNN来理解,在CNN中,卷积块作为基本的特征提取器,对应的区域都是(n, n)的像素区域。而在3D点集当中,同样需要找到结构相同的子区域,和对应的区域特征提取器。
.2
对于问题一:
如何来划分点集从而产生结构相同的区域
作者使用邻域球来定义分区,每个区域可以通过中心坐标和半径来确定。中心坐标的选取,作者使用了最远点采样算法算法来实现( point (FPS) )
对于问题二:
作者使用了作为特征提取器
由可以看到,结构中只有一个max pool操作,并且得到了一个全局特征,没有得到局部特征,所以模型本身在三维点云场景分割的效果比较差。所以在的第二代,参考了二维图像中CNN的做法。CNN通过分层不断地使用卷积核扫描图像上的像素,使得越到后面的特征图感受野越大,同时每个像素包含的信息也越多。
先对整个点云数据划分一个个范围,范围内中心点之间的距离足够远,范围内其他点作为局部的特征,然后用进行一次特征的提取。通过了多次这样的操作后,原本的点的个数变得越来越少,每个点都是上一层通过提取出来的局部特征。这个过程论文中称为Set (SA)。
2.1Set (SA)
Set
一个SA层包含三个步骤:
:利用 point (最远点采样)随机采样点。
:利用query ball point划一个R为半径的圈,将每个圈里面的点云作为一簇。
: 对+以后的点云进行局部的全局特征提取
.3 of
++是的延伸,在的基础上加入了多层次结构( ),使得网络能够在越来越大的区域上提供更高级别的特征。
网络的每一组set 主要包括3个部分: layer, layer and layer。
layer:主要是对输入点进行采样,在这些点中选出若干个中心点;
layer:是利用上一步得到的中心点将点集划分成若干个区域;
layer:是对上述得到的每个区域进行编码,变成特征向量
每一组提取层的输入是(N,(d+C)),其中N是输入点的数量,d是坐标维度,C是特征维度。
输出是(N',(d+C^{'})),其中N'是输出点的数量,d是坐标维度不变,C'是新的特征维度。下面详细介绍每一层的作用及实现过程。
3. layer
使用 point (FPS)选择N'个点,至于为什么选择使用这种方法选择点,文中提到相比于随机采样,这种方法能更好的的覆盖整个点集。具体选择多少个中心点,数量怎么确定,可以看做是超参数视数据规模来定。
FPS算法原理为:
从点云中选取第一个点A作为查询点,从剩余点中,选取一个距离最远的点B;
以取出来的点A,B作为查询点,从剩余点中,取距离最远的点C。此时,由于已经取出来的点的个数超过1需要同时考虑所有查询点(A,B)。方法如下:
2.1 对于剩余点中的任意一个点P,计算该点P到已经选中的点集中所有点(A, B)的 距离;取与点A和 B的距离中的最小值作为该点到已选点集的距离d;
2.2 计算出每个剩余点到点集的距离后,选取距离最大的那个点,即为点C3
3. 重复第2步,一直采样到N'个点为止。
++较的主要改进是引入了局部特征的思想: 将整个大点云P分成有的小点云,分别利用对小点云进行特征提取。(采样的目的)就是选出上述小点云的代表点(中心点),这里实现的方式采用的FPS( point ):
a. 有两个集合A = {}, B = P
b. 随机选择B中一个点x加入A, 并从B中删除点x
c. 计算B中每个点z到A中所有点的距离得到z_1, z_2, …, z_len(A), 选择min(z_1, z_2, …, z_len(A)记为点z到集合A的距离;
d. 从B中选择距离集合A最远的点y, 加入到集合A,并从B删除点y.
e. 重复c, d直到集合A中点的数量满足预先设定的阈值.
是不是和图论里的算法很类似,只不过算法求的是最短距离。下面用一张二维图更直观的表示的目的: 左图表示输入点,右图表示使用FPS算法采样得到的中心点(红色倒三角形)。这些中心点将用于接下来的group操作。
的代码(fps算法)的代码如下, 部分是采用的向量化实现,而且在实现的时候有些技巧性;建议首先自己思考一下如何用代码实现上述fps算法:
input和分别是什么 ? Input: 点集xyz shape=(B, N, 3), 中心点的数量M; : M个中心点的坐标或索引, shape=(B, M, 3)或(B, M). 代码中返回的是索引值。
如果不用for循环进行比较距离, 又该如何实现 ? 如果感觉不是很好写,看看下面的代码实现吧。
如何实现点集中的点-点距离的向量化计算 ? 这里实现时遇到了一个坑, 当dist=0时,有可能会出现1e-8之类很小的值,但开根号也没有报错,所以比较好的方式是使用平方距离,或者使用torch.where过滤一下距离等于0的值。
def farthest_point_sample(xyz, npoint):"""Input:xyz: pointcloud data, [B, N, 3]#B代表batch_sizenpoint: number of samplesReturn:centroids: sampled pointcloud index, [B, npoint, 3]"""device = xyz.deviceB, N, C = xyz.shapecentroids = torch.zeros(B, npoint, dtype=torch.long).to(device) # 采样点矩阵(B, npoint)distance = torch.ones(B, N).to(device) * 1e10 # 采样点到所有点距离(B, N)farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device) # 最远点,初试时随机选择一点点batch_indices = torch.arange(B, dtype=torch.long).to(device) # batch_size 数组for i in range(npoint):centroids[:, i] = farthest # 更新第i个最远点centroid = xyz[batch_indices, farthest, :].view(B, 1, 3) # 取出这个最远点的xyz坐标dist = torch.sum((xyz - centroid) ** 2, -1) # 计算点集中的所有点到这个最远点的欧式距离mask = dist < distance distance[mask] = dist[mask] # 更新distances,记录样本中每个点距离所有已出现的采样点的最小距离farthest = torch.max(distance, -1)[1] # 返回最远点索引return centroids3.
这一层使用Ball query方法对 采样的点生成个对应的局部区域,根据论文中的意思,这里使用到两个超参数 ,一个是每个区域中点的数量K,另一个是query的半径r。这里半径应该是占主导的,在某个半径的球内找点,点的数量上限是K。球的半径和每个区域中点的数量都是超参数。
经过操作,我们已经得到了点云P中M个中心点,group的操作就是以每个中心点为圆心,人工设定半径r,每个圆内部的点作为一个局部区域,再利用接下来的提取特征。这里需要注意的是,为了方便batch操作,每一个局部区域内的点的数量是一致的,都为K,如果某个圆内的点的数量小于K, 则可以重复采样圆内的点,达到数量K;如果某个区域内的点的数量大于K, 则随机选择K个点,即可。group操作得到的结果如下图所示,可以形成很多小的局部区域。
Group的代码该怎么写呢? 首先得先考虑清楚一下问题:
group的输入和输出是什么? 输入: 完整点云(B, N, 3), 中心点(B, M), 半径r, 前面提到的数量K; 输出: 很多个局部小点云(B, M, K, 3)或其索引(B, M, K),下面代码中返回的是索引值, shape为(B, M, K)
难点在于向量化实现选择K个点: 在圆内大于K和小于K时是如何操作的。
具体代码参考如下:
def gather_points(points, inds):''':param points: shape=(B, N, C):param inds: shape=(B, M) or shape=(B, M, K):return: sampling points: shape=(B, M, C) or shape=(B, M, K, C)'''device = points.deviceB, N, C = points.shapeinds_shape = list(inds.shape)inds_shape[1:] = [1] * len(inds_shape[1:])repeat_shape = list(inds.shape)repeat_shape[0] = 1batchlists = torch.arange(0, B, dtype=torch.long).to(device).reshape(inds_shape).repeat(repeat_shape)return points[batchlists, inds, :]def ball_query(xyz, new_xyz, radius, K):''':param xyz: shape=(B, N, 3):param new_xyz: shape=(B, M, 3):param radius: int:param K: int, an upper limit samples:return: shape=(B, M, K)'''device = xyz.deviceB, N, C = xyz.shapeM = new_xyz.shape[1]grouped_inds = torch.arange(0, N, dtype=torch.long).to(device).view(1, 1, N).repeat(B, M, 1)dists = get_dists(new_xyz, xyz)grouped_inds[dists > radius] = Ngrouped_inds = torch.sort(grouped_inds, dim=-1)[0][:, :, :K]grouped_min_inds = grouped_inds[:, :, 0:1].repeat(1, 1, K)grouped_inds[grouped_inds == N] = grouped_min_inds[grouped_inds == N]return grouped_inds
3. layer
经过了和group操作,整个大点云被分成了很多个有的小点云, 整个完整点云可表示为shape=(B, M, K, C0)的, M表示中心点的数量, K表示每个中心点的球邻域内选择的点的数量, C0是特征维度, 初始输入点位C0=3或C0=6(加上信息)。
接下来就是利用对每个小点云P’(shape=(K, C0))进行特征提取。对小点云P’中的每个点连续进行 1d卷积 + bn + relu 操作,学习每个点的特征, 最后在K通道上进行最大值和平均值池化,得到当前小点云的特征F(shape=(C, )),.
这里实现时并没有直接用nn.,而是使用了nn., size=1, 本质应该是一样的。每个小点云P’(K, C0)经过得到特征F(C, ), 那么一个batch的数据(shape=(B, M, K, C0)), 经过模块后, 将会得到维度为(B, M, C)的特征. 这部分代码比较简洁,就是的常规操作,部分代码如下:
self.backbone = nn.Sequential()for i, out_channels in enumerate(mlp):self.backbone.add_module('Conv{}'.format(i),nn.Conv2d(in_channels, out_channels, 1,stride=1, padding=0, bias=False))if bn:self.backbone.add_module('Bn{}'.format(i),nn.BatchNorm2d(out_channels))self.backbone.add_module('Relu{}'.format(i), nn.ReLU())in_channels = out_channels
上面就是一次set 操作了. ++是有3次set 操作的:
这里有一个细节问题, 可以看到C1和C2后面都加了3, 这是在学到特征的基础上又加了位置信息(x, y, z), 重新作为新的特征来送入网络。
3.4分类任务在提取特征后是怎么操作的,loss是什么
在提取了每个点云的特征(C3, )之后, 接下来就和图像里的分类任务一样了,C3维的特征作为输入,然后通过通过两个全连接层和一个分类层(分类层的是输出节点等于类别数的全连接层),输出每一类的概率。
损失函数采用的是交叉熵损失函数,对应中的nn.().
3.5分割任务中如何进行上采样, loss是什么?
分割任务需要对点云P中的每个点进行分类,而++中的set 由于操作减少了输入点云P中的点的数量,如何进行上采样使点云数量恢复输入时的点云数量呢?
在图像分割任务中,为了恢复图像的分辨率, 往往采用反卷积或者插值的方式来操作呢, 在点云中该如何恢复点云的数量呢?
其实,在++中的set 模块里,当前点云Q和下采样后的点云Q’的中的点位置信息一直是保存的,点云的上采样就是利用了这一特性。这里利用二维图直观的解释一下,下方左图中红色的倒三角形表示下采样后的点云Q’, 蓝色的点云表示下采样之前的点云Q, 点云里的上采样就是用学习后的点云Q’的特征表示下采样之前点云Q的特征。采用的方式是k近邻算法,论文中k=3。如图所示,对于Q中的每一个点O,在Q’中寻找其最近的k个点,基于距离加权(距离O近,其权重大; 距离O远, 其权重大)求和这k个点的特征来表示点O的特征,具体计算方式为:
上采样得到了C’维的特征, 而且点的数量已经恢复到了下采样之前的数量; 将C’维的特征与set 中相同点数量的点云(对称位置)特征(C维)进行进行操作,进而进行多个 + Bn + ReLU操作,来得到新的特征。
经过三次上采样操作后,点云恢复了初始输入点云中点的数量, 再经过一次 + bn + relu层 和一个对点的分类层,最终得到对每个点的分类。
上采样部分的实现代码如下:
def three_nn(xyz1, xyz2):''':param xyz1: shape=(B, N1, 3):param xyz2: shape=(B, N2, 3):return: dists: shape=(B, N1, 3), inds: shape=(B, N1, 3)'''dists = get_dists(xyz1, xyz2)dists, inds = torch.sort(dists, dim=-1)dists, inds = dists[:, :, :3], inds[:, :, :3]return dists, indsdef three_interpolate(xyz1, xyz2, points2):''':param xyz1: shape=(B, N1, 3):param xyz2: shape=(B, N2, 3):param points2: shape=(B, N2, C2):return: interpolated_points: shape=(B, N1, C2)'''_, _, C2 = points2.shapedists, inds = three_nn(xyz1, xyz2)inversed_dists = 1.0 / (dists + 1e-8)weight = inversed_dists / torch.sum(inversed_dists, dim=-1, keepdim=True) # shape=(B, N1, 3)weight = torch.unsqueeze(weight, -1).repeat(1, 1, 1, C2)interpolated_points = gather_points(points2, inds) # shape=(B, N1, 3, C2)interpolated_points = torch.sum(weight * interpolated_points, dim=2)return interpolated_points
分割任务中损失函数采用的也是交叉熵损失函数,对应中的nn.().
3.6以解析++网络中维度和尺寸是怎么变化的 ?
骨干网络:
Input data(B, N, 6) -> Set [(B, 512, 3) -> group(B, 512, 32, 6) -> (B, 512, 32, 128) -> (B, 512, 128)] -> Set [(B, 128, 3) -> group(B, 128, 64, 128 + 3) -> (B, 128, 64, 256) -> (B, 128, 256) ] -> Set [(B, 1, 3) -> group(B, 1, 128, 256 + 3) -> (B, 1, 128, 1024) -> (B, 1, 1024)] -> (B, 1, 1024)
分类模块:
(B, 1024) -> FC(B, 512) -> FC(B, 256) -> (B, )
分割模块:
(B, 1, 1024) -> FP[(B, 128, 1024) -> (B, 128, 1024+256)->(B, 128, 256)]
-> FP((B, 512, 256) -> (B, 512, 256+128) -> (B, 512, 128))
-> FP((B, N, 128) -> (B, N, 128+6)->(B, N, 128))
-> (B, N, 128) -> (B, N, )
上述模块如果能够了解清楚并能写出代码的话,基于的++网络就可以实现了。
3.++中的一些其它问题
++ 的MSG, MRG架构 ?
上述文章主要介绍了++的SSG( scale ), 为了解决点云中密度分布不均匀的问题,作者提出了MSG(multi-scale )和MRG(multi ).
下面这张图是作者论文里的图(在数据集上的实验), 测试了, SSG, MSG, MRG的性能,横坐标表示的是在预测时点云中点的数量,纵坐标表示的是准确率。从图中可以看到, 在点的数量较多时,SSG, MRG, MSG性能相近,明显高于; 但随着点云中的点的数量下降,准确率明显下滑的有两条线,有轻微下降趋势的有四条线。明显下滑的两条线是没有采取DP策略的。 即使是网络在采取了DP策略后,其性能在点的数量小于600也会明显高于SSG.。由此可见,DP在解决点云密度不均匀时发挥了重要作用, 而MSG, MRG貌似显得没那么重要 ? 这里就简单介绍一下MSG的思想。
MSG是指在每次Set 的时候, 在对某个中心点进行group操作的时候采用不同尺寸(例如0.1, 0.2, 0.4, SSG只有0.2)的半径, 来得到不同大小的局部区域,分别送到不同的网络中,最终把这些学习到的不同尺度的特征进行操作来代表当前中心点的操作。
点云如何数据增强 ?
点云不同于图像,图像中有随机裁剪、缩放、颜色抖动等数据增强方式。在点云里,应该如何做数据增强呢?
点云的数据增强主要包括: 随机旋转,随机平移,随机抖动等, 具体实现代码参考:
DP有什么用,是怎么实现的 ?
DP指的是在训练时随机丢弃一些输入点(DP means input ),这样的训练方式对于预测低密度点云较为有效(相对于输入点云), 即在高密度点云中训练的模型,在低密度点云中进行预测,可以达到和训练集中旗鼓相当的效果。具体来说,人工设置超参数p(论文中p=0.95), 从[0, p]中随机出一个值dr( ratio), 对于点云中的每一个点,随机产生一个0-1的值, 如果该值小于等于dr则表示该点被丢弃。这里有一个细节,某些点被丢弃之后,每个batch中的点的数量就不相同了,为了解决这个问题,所有被丢掉的点使用第一个点代替,这样就维持了每个batch中点的数量相同。具体实现代码如下(代码中的p=0.875)
def random_point_dropout(pc, max_dropout_ratio=0.875):dropout_ratio = np.random.random()*max_dropout_ratio # 0~0.875drop_idx = np.where(np.random.random((pc.shape[0]))<=dropout_ratio)[0]if len(drop_idx)>0:pc[drop_idx,:] = pc[0,:] # set to the first pointreturn pc
:
基于实现++的博客-CSDN博客
++详解与代码_自动驾驶小学生的博客-CSDN博客_xyz.(0, 2, 1)